If you’ve been reading the Sharp Sight blog for a while, you’ll know that I’m a big fan of elite performers: Navy SEALs, elite athletes, grandmaster chess players, etcetera.
I like to research how elite performers operate, because I want to find what makes them special. The techniques. The training methods. The mindsets.
In particular, I’m interested in how they become so great at what they do.
What’s the process? How do they get from a normal person, to a master of their field?
If you ask this question long enough, and you look at elite performers across many disciplines, you’ll start to see patterns.
After many years of studying top performers, I’ve discovered quite a few tips, strategies, and “secrets.”
And I’ve been able to apply to data science to help people learn very quickly and become top performers.
In this tutorial, I’m going to distill these strategies of elite performers into 7 steps that will help you to master data science fast:
- Focus on Foundations
- Identify the Most Important Techniques
- Identify the Most Commonly Used Parameters
- Break Everything Down into Small Units
- Practice the Small Units
- Repeat Your Practice
- Reintegrate Everything into a Coherent Whole
Let’s talk about each of those steps.
1: Focus on Foundations
If I had a dollar for every time I had this conversation, I quit data science and retire to a beach on the Italian Riviera:
Data science hopeful: “HoW dO i LEaRN mACHiNE LeARnINg?”
Me: Have you mastered data wrangling and data analysis yet?
Data science hopeful: No.
Me: ????
Look. I understand that I’m being a bit of an asshole here.
And, I get it: machine learning is very cool. Artificial intelligence is white hot right now. As I’ve said in the past, machine learning will probably impact every major part of our economy. It’s one of the most important general purpose technologies since the invention of electricity. Moreover, many people with an elite machine learning skillset are making over $200,000 per year (or way more).
But here’s the problem …
Machine learning is an advanced skill that’s dependent on other foundational skills.
For example, at Tesla, the machine learning team spends 75% of their time on “the data.”
Specifically, they spend most of their time cleaning their data up, getting it ready for analysis, visualizing it and analyzing it.
Here’s Tesla’s former head of AI, Andrej Karpathy, discussing the AI team at Tesla a few years ago:
For reference, the dude talking in that video is Andrej Karpathy, the head of AI at Tesla.
Listen to what he says: “At Tesla, I spend most of my time just massaging the datasets.”
Meanwhile, he also has a bullet point in his presentation noting that Tesla AI programmers spend a lot of time “visualizing datasets.”
My point here, is that if you want to do the sexy stuff in data science (like machine learning, deep learning, AI, etc) …
Then you need to master. the. foundations.
What are the foundations? In data science, these are the foundations:
- data wrangling
- data visualization
- data analysis
In Python, that means that you need to learn:
- Pandas
- Numpy
- and at least 1 data visualization package, like Seaborn
(I strongly prefer Seaborn to Matplotlib, these days.)
Additionally, you need to know how to combine these tools to analyze data and do real work.
At the risk of belaboring the point, I offer a quote by the basketball GOAT himself, Michael Jordan.
“Get the fundamentals down and the level of everything you do will rise.”
As I said earlier: you can learn the principles of master from the the people who mastered their own field. Follow MJ’s advice. Get the fundamentals down.
2: Identify the most important Techniques
Once you’ve decided to master the fundamentals, you need to identify the principal techniques.
This actually comes from Tim Ferriss (although, you can also find it in many other places).
In The 4 Hour Chef, Ferriss wrote about rapid skill acquisition. Superficially, the book is about cooking, but in reality, the book is about learning.
In The 4 Hour Chef, Ferriss wrote about why it’s so important to select the most important things.
So for example, in the book, Ferriss notes that if you want to learn English, you should focus on the most frequently used words. Why? The English language has almost 200,000 words, but 100 words account for 50% of all printed material. And the top 1000 words account for about 80% of printed material. (Note that this is an example of the 80/20 rule.)
“Language hackers” and polyglots (people who speak multiple languages) know this fact, and use it to learn foreign languages: many of them on the top 1000 words first, which enables them to get to a competent level very quickly, because they’re focusing on the most commonly used things.
The same principle applies to data science.
If you want to learn data science fast, you need to focus on the most commonly used tools and techniques.
For example, I previously wrote about the Top 19 Pandas Methods that you Should Memorize:
- read csv
- set index
- reset index
- loc
- iloc
- drop
- dropna
- fillna
- assign
- filter
- query
- rename
- sort values
- agg
- groupby
- concat
- merge
- pivot
- melt
I chose these 19 tools and techniques because they account for a huge amount of the data wrangling code that I write and other people write.
Again: this is just an application of the 80/20 rule.
Find the most commonly used techniques, and focus on them.
You can apply this principle to data visualization to by focusing on the most common visualizations … like bar charts, line charts, histograms, and other commonly used tools.
Ultimately, you need to identify the most frequently used tools and techniques in data science, so you can focus on them.
3: Identify the Most Commonly Used Parameters
Once you identify the most commonly used tools and techniques, you need to identify the most commonly used parameters.
Take for example, the Seaborn histogram.
By my count, there are around 32 parameters for the sns.histplot() function.
But how many of those parameters will you actually use?
About 5, Chad.
And if you’re likely to use only a few parameters the vast majority of the time, then it makes sense to focus on those parameters, right?
Yes. It does.
This is why, at Sharp Sight, you’ll notice that we break things down and select the most important parameters.
For example, when I wrote our tutorial about the Seaborn histogram a while ago, it focused on 5 or 6 parameters. That’s it. In the visual syntax explanation, I identified 2 parameters. And then later, in the text of the tutorial, I discussed and used only a few more.
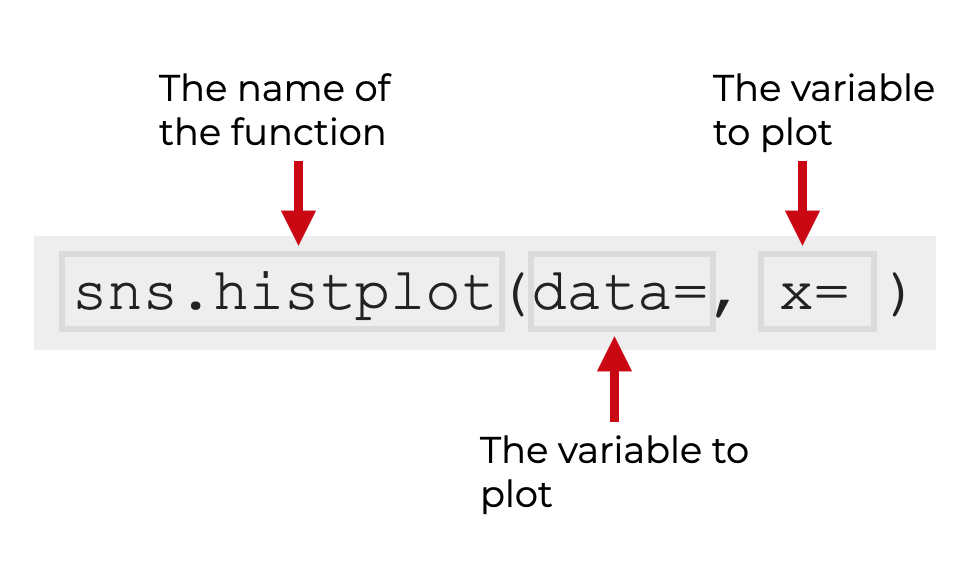
If you’ve been paying attention, and if you understand our learning philosophy, you’ll understand that this is once again another application of the 80/20 rule.
You need to learn the most commonly used things, and that includes learning the most commonly used parameters.
4: Break Everything Down into Simple Units
After you’ve identified the most commonly used techniques and parameters, you need to find the “minimal learnable units.”
Once again, this concept comes from Tim Ferriss. In an episode of The Tim Ferriss Podcast, Ferriss talked about identifying the small “building blocks” of a skill.
The good news is that if you’ve already identified the most important functions, and the most important parameters, you’re over half way there.
In the case of data science, the minimal learnable units (MLUs) are mostly the function names and parameter names. These are small units of syntax that you need to be able to recall in order to memorize and master the syntax.
There might also be a few other things that qualify as MLUs, like the meaning of some function arguments. For example, in Numpy, we often need to execute a technique along a particular axis. That means that you need to know the difference between axis 0 and axis 1 when you use some Numpy functions, and need to provide an argument to the axis parameter.
5: Practice the Small Units
Once you’ve identified the important units of syntax, you need to practice.
Practice is critical for mastery.
Navy SEAL marksman Chris Sajnog emphasized this in his book Navy SEAL shooting:
“Ever wish you could shoot like a Navy SEAL?
… there is no secret.
It all boils down to practice, and lots of it.”
He notes later that “the best way to learn and reinforce [skills], is through slow, perfect practice.”
Practice is one of the keys to mastery. Lots of practice.
Now, I will point out that practice systems are a complicated topic.
How you practice really matters.
Some practice methods work better than others.
I’ll eventually write a separate blog post about good practice methods.
Having said that, I’ll mention that Cal Newport’s quiz-and-recall comes close to what I have in mind. You should find a way to quiz yourself on the “minimal learnable units” of syntax, and try to recall those MLUs.
6: Repeat Your Practice over time
If you thought that you could just study something once and then know it forever, I have some bad news for you.
The brain forgets.
Forgetting is a normal, natural process.
Have you ever been introduced to a new person by name, and then forgot their name a few minutes later?
Of course.
We’ve all had that experience.
The brain naturally forgets.
And for better or worse, something very similar happens with learning data science: it’s very common to “learn” a new piece of syntax, and then forget it a few days later.
This is normal, but it’s terrible if you’re trying to master data science skills and knowledge.
But, there’s some good news.
There’s a way to strengthen your memory over time: repeat practice.
In particular, if you review your practice materials repeatedly over time, and at somewhat regular intervals, then your memory of those things will get stronger and stronger.
Repeating practice eventually moves information from short term memory to long term memory.
It’s how you solidify your memory of things, like new data science skills.
Repeat practice.
Having said that, the details about the how to structure your repeated practice are complex.
Some methods are more efficient than otheres.
For example, there are ways to optimize the time intervals between review sessions to maximize your learning efficiency (we cover this in our paid courses).
But suffice it to say: you must repeat your practice activities over a period of time to solidify your memory.
7: Reintegrate Everything into a Coherent Whole
Up until this point, most of the tips have been about deconstructing data science into small units that you can practice.
As you practice, and as you repeat your practice, you will eventually master those small techniques and units of syntax.
But, real data science work requires you to combine multiple techniques together. That’s why the next step is to reintegrate all of those isolated techniques into a coherent whole.
For example, a while aho, I published a thread on Twitter where I show how to get, clean, and visualize some Wikipedia data using Python.
In that thread, I demonstrated some fairly detailed data cleaning using Pandas:
This is what real data wrangling looks like. As you can see, I’m using multiple techniques in combination to get sh*t done.
Also notice that most of the tools that I used are things that I mentioned earlier in this post: Pandas query, Pandas assign, Pandas melt. But in the video, you can see that I’m using them together.
So part of the secret to mastering data science is that you need to identify, isolate, and practice techniques individually, so you know the code for each individual tool.
But then, you need to learn how to combine them. That’s how you unlock the real power of data wrangling with Pandas.
So to reiterate: after you deconstruct data science into small learnable units, you must learn how to put those things back together to do real work.
Recap: Take it apart, practice, put it back together
Let’s quickly recap:
To learn data science as quickly and efficiently as possible, you need to:
- Focus on Foundations
- Identify the Most Important Techniques
- Identify the Most Commonly Used Parameters
- Break Everything Down into Small Units
- Practice the Small Units
- Repeat Your Practice
- Reintegrate Everything into a Coherent Whole
A different way of saying it, is that you need to take data science apart, identify the most important and most commonly used techniques, practice repeatedly, and then put the pieces back together … all while keeping the 80/20 rule in mind.
This general path will be the fastest, most efficient way to learn data science.
Join Python Data Mastery
Having said that, the devil really is in the details.
Executing on this process could be challenging if you aren’t sure how to implement it.
If you want to save yourself the time of trying to figure it out yourself, you could just join our course: Python Data Mastery.
Python Data Mastery is our premium data science training course that will teach you:
- data wrangling
- data visualization
- data analysis
… using Numpy, Pandas, Seaborn, and other important Python packages.
And this courses uses the training principles I’ve laid out in this blog post.
We’ve designed this course to be the fastest and most efficient way to learn data science in Python.
The course will reopen for enrollment on Monday, but you must be on our email list to be notified when the doors open.
You can join the list here:
Many thanks for this great insight. I find it very applicable
????????????
thanks a lot
You’re welcome.
Great insight but with a fundamental flaw: how do you know which parts are the essential core? By experience.
So if your recommendation is to get the grasp of the most important and fundamental you have only one option: search a mentor, because this is something that internet or a book is not going to give it to you.
I agree and disagree.
Yes: it takes experience to know which are the essential parts.
But I also literally told you the top 19 most important Pandas methods. I also mentioned several of the data visualization techniques you should learn.
Moreover, I’ve been writing similar articles for several years. With some clever google searches, you could probably find my recommendations for how to distill Numpy, data visualization, and a few other topics.
Still, you are correct: having a mentor or coach will dramatically accelerate your progress. But isn’t that also true for sports, or chess, or music?
With enough time and effort, you can figure it out on your own (using the path outlined above).
But you’ll make much faster progress with a coach.
What’s your time worth to you?
Hey mate, how many languages do you speak yourself and also if your expertise is worth $200,000 plus why are you not at apple etc anymore? self employment more suitable?
Also super interested in your IQ. You seem super intelligent, if you were to take a wild guess would you say over 130? to major in physics at a prestigous university is a 130 minimum I would assume
I speak a few languages to varying degrees.
Entrepreneurship has advantages and disadvantages. Less money in the short run, but more freedom. And much, much bigger possible upside in the long run.
I like that sir. You have all the tools, good luck on your journey. You haved been vitally important on my journey.