Last week, I wrote a blog post explaining that it’s actually hard to master data science ultra fast.
In order to master data science at an accelerated rate, you need to do a lot of things correctly. You need to work hard, and you need to do things that most students aren’t willing to do.
One of the things that I talked about was syntax memorization.
Syntax memorization is very, very effective … if you do it right.
I realize that a lot of people say that memorization is a waste of time (classically, the great Richard Feynman said something like this).
In spite of the arguments against it, I can say with conviction that syntax memorization can help you learn data science a lot faster.
But here, the details matter. The effectiveness of syntax memorization really depends on how you execute it, and what you choose to learn.
“How do I do it all?”
One of the key problems was highlighted by a comment on last week’s post by reader MG.
When I mentioned syntax memorization in that post, MG asked:

It’s a reasonable question.
MG points out that there are a lot of data science toolkits and subject areas to learn.
Data manipulation, data visualization, data analysis, geospatial visualization, machine learning, deep learning, NLP ….
The list could go on and on.
What do you do?
How do you memorize it all?
The short answer: You don’t memorize it all at once.
Learn faster by learning less
The great error here is that you need to learn everything immediately, or that you need to know everything in order to be a productive data scientist.
Let me say this plainly: you don’t need to know everything to be productive. You don’t need to know everything to create valuable deliverables.
To create value (which is what you need to do, if you want people to actually pay you), you probably need to know only 3 major skill areas.
Moreover, you don’t need to know everything in those skill areas … you just need to know a few things.
Here, I’m reminded of an old Bruce Lee quote:
I fear not the man who has practiced 10,000 kicks once, but I fear the man who has practiced one kick 10,000 times.
His point is that it’s better to know a few things really well, than to be really bad at a lot of things.
Ultimately, it’s best to be skilled at a lot of things, but as a beginner, that just won’t be possible.
You need to focus.
If you can focus on a small set of important things, you can learn and memorize them much faster.
How to chose what to focus on
There are two major recommendations that will help you select the right things to focus on:
- First: focus relentlessly on the “core” data science skills
- Second: apply the 80/20 rule
If you apply these principles, you’ll make much faster progress.
Let’s discuss both of them.
focus on “core” data science skills
One of the big mistakes (particularly for beginners) is thinking that you need to know everything.
You don’t.
Your first major goal is to master “the core.”
What is the core?
Data visualization, data manipulation, and data analysis.
Almost everything in data science requires these skills.
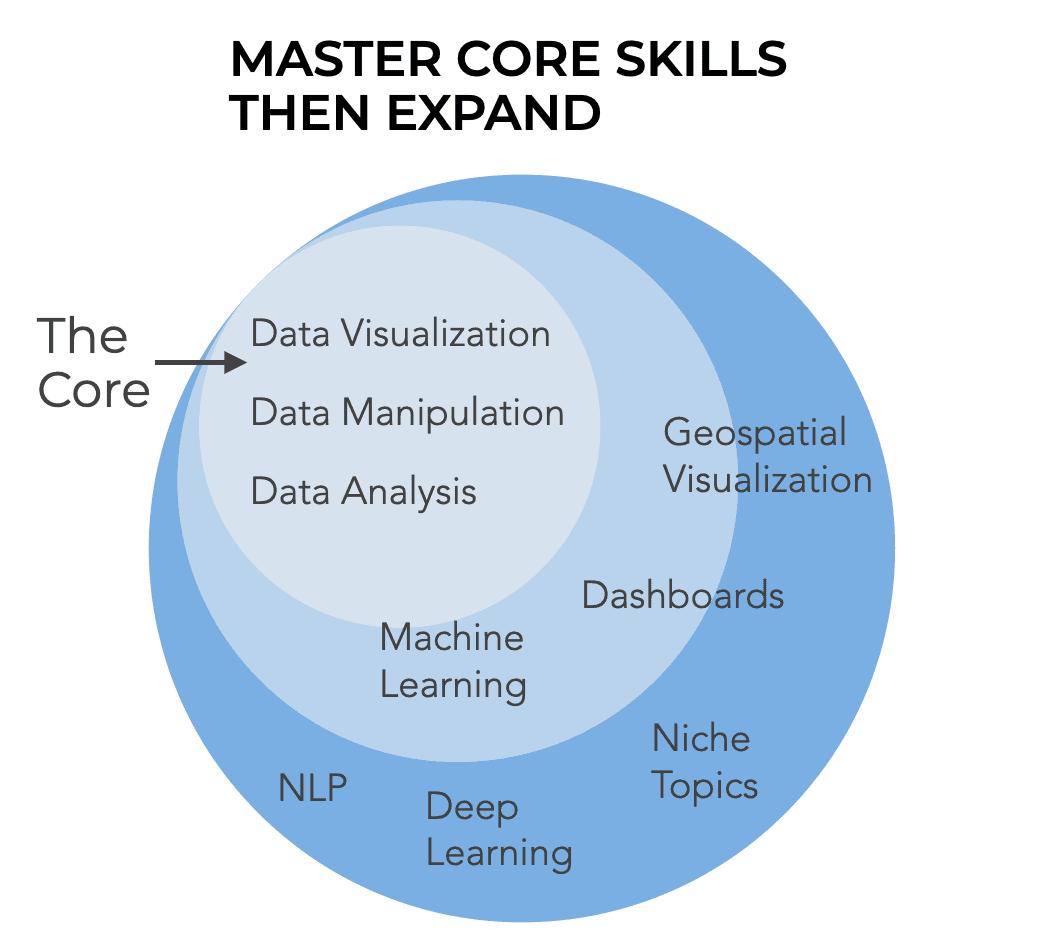
If you want to create a report, you need to know these skills. If you want to perform an analysis, you need to know these skills. If you want to work on a machine learning project, you need to know them.
Data visualization, data manipulation, and data analysis are the core. They are the foundation. You need to know them well enough that you can do productive work.
Apply the 80/20 rule
In addition to focusing on “the core,” you should also use the 80/20 rule to identify the most important, most commonly used techniques.
For those of you who don’t know, the 80/20 rule states that 80% of the output comes from 20% of the inputs.
If you’re applying 80/20 thinking to data science, you should be looking for the most common, most frequently used techniques.
You need to identify the “high frequency” techniques that are used over and over again.
If you’ve never worked as a data scientist, it might be a little hard to identify these techniques.
But since I’m a generous guy, I’ll just tell you. You’re welcome.
A brief list of things you need to know
Here is a quick list of things you need to know, broken out into data visualization and data manipulation.
Data Visualization tools
For data visualization, you should be able to create:
- line charts
- bar charts
- histograms
- scatterplots
- box plots
You should be able to create these quickly, reliably, and painlessly.
You should be able to create these without looking up the code.
So at minimum, you should memorize the code to create these.
If you’re working in Python, that probably means memorizing several matplotlib functions and probably some seaborn functions.
Data Manipulation tools
Next is data manipulation.
As I’ve emphasized before, 80% of data science is data manipulation.
In fact, to create the charts and graphs that I mentioned above, you will probably need to clean or wrangle your data first.
That being the case, here are the data manipulation techniques that you absolutely need to know.
You should be able to:
- Add new variables
- Delete variables
- Subset rows
- Subset columns
- Fill in missing data
- Rename columns
- Join datasets
- Sort data
- Reshape datasets from long to wide and from wide to long
- Group data by a categorical variable
- Aggregate data
… and maybe a couple of other things.
But that’s really the short-list of the 100% essential data manipulation tasks.
That’s a small list!
But again, you should be able to perform these techniques quickly, reliably, and from memory.
That’s what it takes to be productive.
Apply the 80/20 rule for parameters too
One more quick note on memorizing syntax:
You can apply the 80/20 rule to parameters as well.
Most functions and methods have a lot of parameters that control how they work.
Do you need to memorize them all?
No.
For most functions, there are a few parameters that you need to use frequently, and many other parameters that you’ll rarely use, if ever.
Identify the most frequently used parameters and memorize those.
You don’t have to memorize every parameter … just the ones that you’ll use often.
Over time, if you end up using other parameters, you can memorize those too.
But in the beginning target the most frequently used parameters and memorize them.
Master the foundations before you move on
As a beginner, you should focus relentlessly on mastering the most frequently used “core” skills.
What this also implies is that you should not try to learn advanced skills.
If you can’t make simple data visualizations quickly and 100% from memory, you have no business moving on to advanced data visualization techniques like geospatial visualization.
You should be able to create simple charts and graphs fast and you should be able to write the code from memory. That’s what it takes to be a productive person in a data-job.
The same thing goes for other advanced techniques.
If you haven’t mastered the core (data visualization, data manipulation, and data analysis), then stop learning advanced techniques.
No one gives a $#^! that you have a “certificate in machine learning” if you can’t even deliver a good data analysis under time pressure.
I repeat: master the core skills.
Memorize the code to do these things, and become someone who can quickly and reliably produce entry-level deliverables like reports, analyses, and data pulls.
Once you’re really good at doing those things, you can expand and add more advanced skills you your skill stack.