In the last several blog posts at Sharp Sight, I’ve created several different maps.
Maps are great for practicing data visualization. First of all, there’s a lot of data available on places like Wikipedia that you can map.
Moreover, creating maps typically requires several essential skills in combination. Specifically, you commonly need to be able to retrieve the data (e.g., scrape it), mold it into shape, perform a join, and visualize it. Because creating maps requires several skills from data manipulation and data visualization, creating them will be great practice for you.
And if that’s not enough, a good map just looks great. They’re visually compelling.
With that in mind, I want to walk you through the logic of building one step by step.
In the last several blog posts about maps, I gave some detail about how to create them, but in this post, I want to give a little more detail about the logic.
I want you to understand the thinking behind the code. This post will show you how to make a map, and explain the R code that creates it.
Ok, let’s get to it.
Install packages
First, we’ll just install the packages we’re going to use. Pretty straightforward.
#================= # INSTALL PACKAGES #================= library(tidyverse) library(rvest) library(magrittr) library(ggmap) library(stringr)
Scrape data from website
The data that we’re going to plot exists as a table on a website.
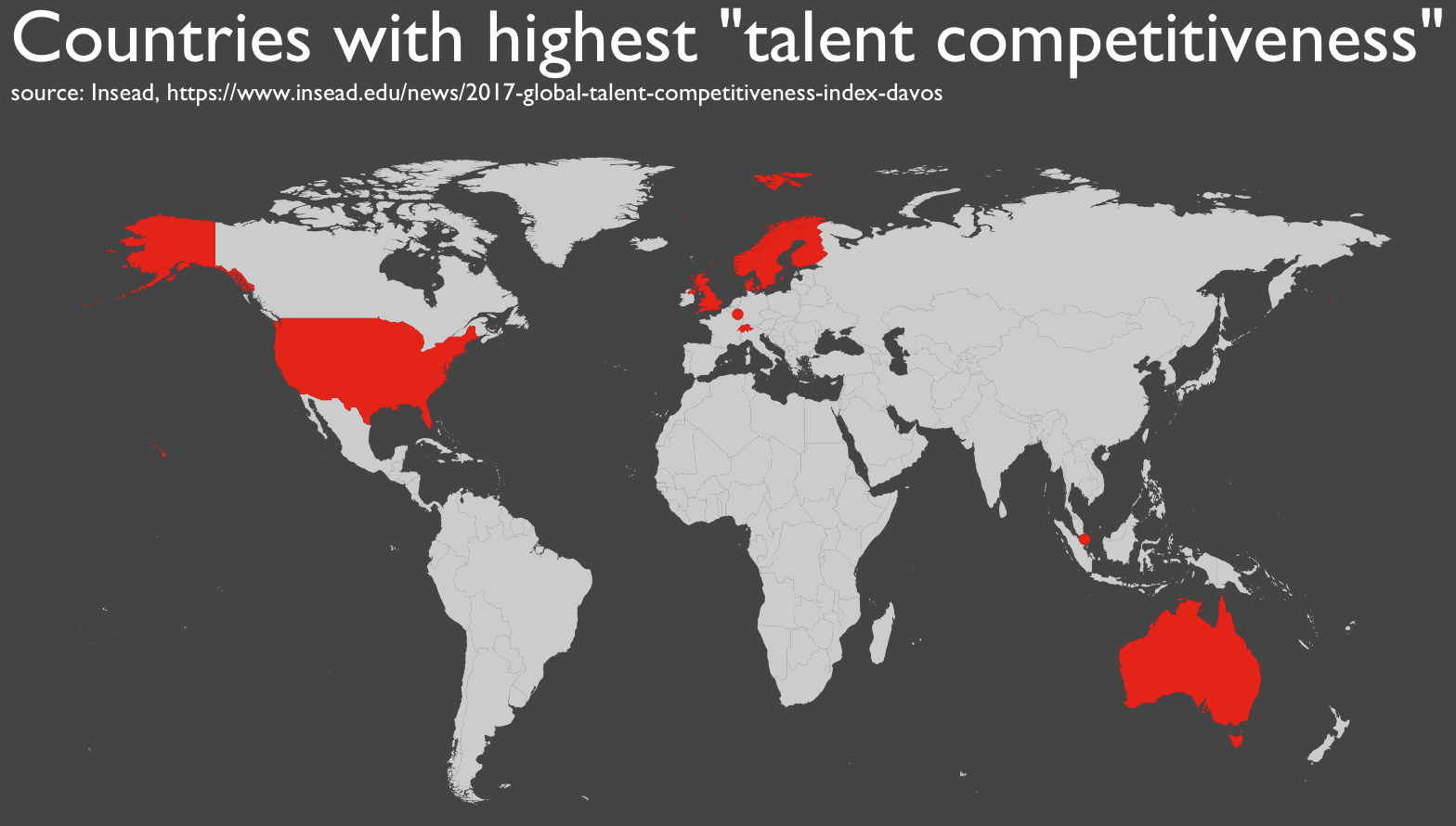
The data is a list of the top 10 countries with the highest ‘talent competitiveness’ (i.e., the countries that are most attractive to talented workers). The data was created as part of an analysis by the business school, INSEAD.
If you go to the webpage that summarizes the talent competitiveness report, you’ll find the following table:
Global Talent Competitiveness Index 2017 Rankings: Top Ten
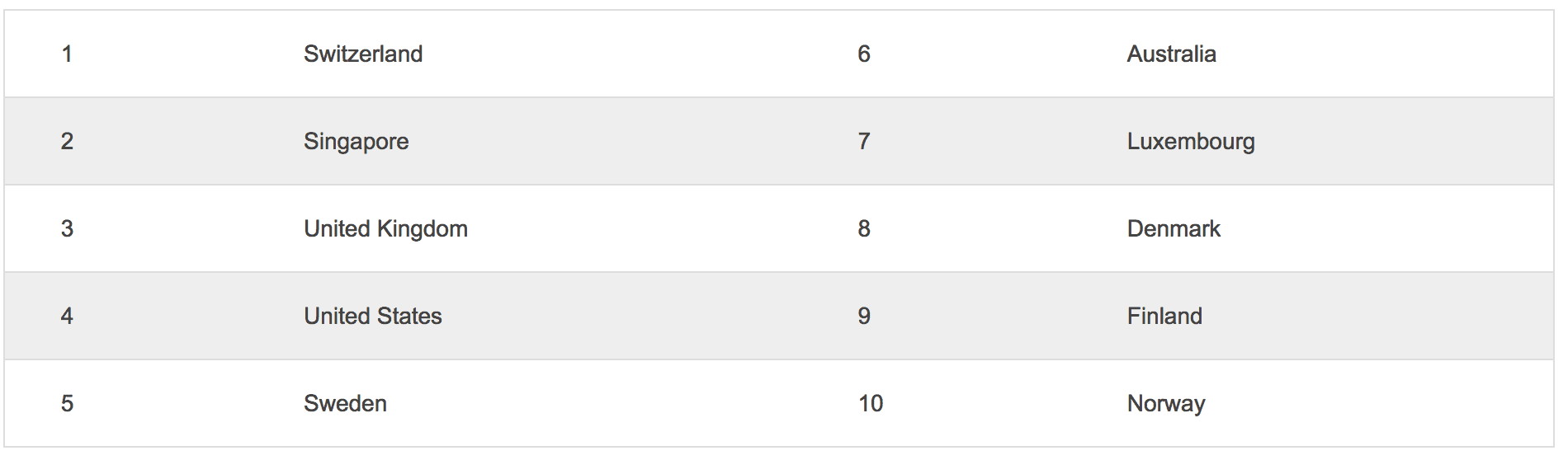
This is the data we’re after, and we have to scrape it and pull it into R.
To do this, we need to use a few tools from the
First, we’ll use
Next, you’ll see that we use the magrittr pipe
#============
# SCRAPE DATA
#============
html.global_talent <- read_html("https://www.insead.edu/news/2017-global-talent-competitiveness-index-davos")
df.global_talent_RAW <- html.global_talent %>%
html_nodes("table") %>%
extract2(1) %>%
html_table()
Data manipulation: split and recombine into long-form dataframe
If you inspect the data, you’ll notice that the ranks are split up between two columns. The country names are also split between two columns.
print(df.global_talent_RAW) # X1 X2 X3 X4 # 1 Switzerland 6 Australia # 2 Singapore 7 Luxembourg # 3 United Kingdom 8 Denmark # 4 United States 9 Finland # 5 Sweden 10 Norway
This is an improper structure for the data, so we need to restructure it. Specifically, we need all of the ranks in one column and all of the countries in another column.
To do this we’re going to split
To split the data, we’ll just use
Notice that we also rename the columns using
#============================================= # SPLIT INTO 2 DATA FRAMES # - the data are split into 4 columns, whereas # we want all of the data in columns #============================================= df.global_talent_1 <- df.global_talent_RAW %>% select(X1, X2) %>% rename(rank = X1, country = X2) df.global_talent_2 <- df.global_talent_RAW %>% select(X3, X4) %>% rename(rank = X3, country = X4)
After splitting them, we’ll recombine them with
#=========== # RECOMBINE #=========== df.global_talent <- rbind(df.global_talent_1, df.global_talent_2) # INSPECT glimpse(df.global_talent) print(df.global_talent)
Data manipulation: trim excess whitespace
Now, we'll do some simple string manipulation to modify the country names.
Specifically, if you use
glimpse(df.global_talent) # Observations: 10 # Variables: 2 # $ rank" 1", " 2", " 3", " 4", " 5", " 6", " 7", " 8", " 9", " 10" # $ country " Switzerland", " Singapore", " United Kingdom", " United States", " Sw...
We need to remove these.
To do so, we'll use
#==========================
# STRIP LEADING WHITE SPACE
#==========================
df.global_talent <- df.global_talent %>% mutate(country = str_trim(country)
,rank = str_trim(rank)
)
Notice that we're doing this inside of
Now if we print out the data, it looks good.
# INSPECT print(df.global_talent) # rank country # 1 Switzerland # 2 Singapore # 3 United Kingdom # 4 United States # 5 Sweden # 6 Australia # 7 Luxembourg # 8 Denmark # 9 Finland # 10 Norway
All of the ranks are in one column, and the country names are in another column.
Get world map
Next, we're going to get a map of the world.
This is very straightforward. To do this, we'll use
#==============
# GET WORLD MAP
#==============
map.world <- map_data("world")
Recode country names
The next thing we need to do is join the global talent data,
To do this, we need to use a join operation. However, to join these two separate datasets together, we'll need the country names to be exactly the same. The problem, is that the country names are not all exactly the same in the two different datasets.
For the time being, I'll set aside how to detect these dissimilarities between country names. Suffice it to say, the country names in
That being the case, we'll need to recode the names that don't match. Specifically, out of the 10 countries in
We'll recode them with
#===========================================
# RECODE NAMES
# - Two names in the 'global talent' data
# are not the same as the names in the
# map
# - We need to re-name these so they match
# - If they don't match, we won't be able to
# join the datasets
#===========================================
# INSPECT
as.factor(df.global_talent$country) %>% levels()
# RECODE NAMES
df.global_talent$country <- recode(df.global_talent$country
,'United States' = 'USA'
,'United Kingdom' = 'UK'
)
This is fairly straightforward. The
If we take a quick look after executing this, you'll see that
# INSPECT print(df.global_talent) # rank country # 1 Switzerland # 2 Singapore # 3 UK # 4 USA # 5 Sweden # 6 Australia # 7 Luxembourg # 8 Denmark # 9 Finland # 10 Norway
Join 2 datasets together
Next, we'll join together
#================================
# JOIN
# - join the 'global talent' data
# to the world map
#================================
# LEFT JOIN
map.world_joined <- left_join(map.world, df.global_talent, by = c('region' = 'country'))
If you're familiar with joins, this is fairly straightforward. Of course, if you don't use joins often, this might not make sense.
Essentially, we're using
Take a look at the dataset
head(map.world)
It contains essentially all of the countries of the world, as well as information that's required to plot those countries as polygons. That being the case, it contains information on over 100 countries.
On the other hand,
The objective right now is to join them together, trying to "join" the two datasets by looking for a match on the country name.
If the join operation finds a match, then great. It's a match, and it will combine the records from the two different datasets.
But what if there's not a match? For example, "Brazil" is in
How these cases of "match" and "no match" are handled is the critical feature of different join types.
In the case of a "left join" we'll keep everything in the "left hand" dataset. Which is the "left hand" dataset? Don't overthink it. It's the dataset that's syntactically on the left in the following line of code:
That is,
In a left join, the operation will keep everything in the left hand dataset, even if there's not a match. Moreover, when there is a match, it will attach the data in the "right hand" dataset.
This is important, because we want to plot all of the countries in the world (so we need to keep everything in
Create "flag" to highlight specific countries
Even though we're going to plot the entire world map, the point of this map is to highlight the top ten countries with the highest talent competitiveness. That being the case, we need a way to distinguish those countries in the newly merged data.
There are a few ways to do this, but we'll do it by using
Basically, if
#=================================================== # CREATE FLAG # - in the map, we're going to highlight # the countries with high 'talent competitiveness' # - Here, we'll create a flag that will # indicate whether or not we want to # "fill in" a particular country # on the map #=================================================== map.world_joined <- map.world_joined %>% mutate(fill_flg = ifelse(is.na(rank),F,T)) head(map.world_joined)
This will give us an indicator variable that we can use to highlight the countries with high talent competitiveness.
Create point locations for Singapore and Luxembourg
One last thing before we plot the map.
Two of the countries with high talent competitiveness, Singapore and Luxembourg, are very small. This makes them quite difficult to see on a map.
To make them more visible, we're going to plot them as points.
To do this, we need to create a separate dataset that contains the latitude and longitude data for the center of these countries.
We'll simply create a new dataset
Finally, we'll use
#=======================================================
# CREATE POINT LOCATIONS FOR SINGAPORE AND LUXEMBOURG
# - Luxembourg and Singapore are countries with
# high 'talent competitiveness'
# - But, they are both small on the map, and hard to see
# - We'll create points for each of these countries
# so they are easier to see on the map
#=======================================================
df.country_points <- data.frame(country = c("Singapore","Luxembourg"),stringsAsFactors = F)
glimpse(df.country_points)
#--------
# GEOCODE
#--------
geocode.country_points <- geocode(df.country_points$country)
df.country_points <- cbind(df.country_points,geocode.country_points)
# INSPECT
print(df.country_points)
# country lon lat
# Singapore 103.819836 1.352083
# Luxembourg 6.129583 49.815273
When we finally inspect the data, we see that this dataset now has the names of those two countries, and the lat/long data that we need in order to plot them as points.
Plot the map using ggplot2
Here we go. Everything is ready. We can plot.
#=======
# MAP
#=======
ggplot() +
geom_polygon(data = map.world_joined, aes(x = long, y = lat, group = group, fill = fill_flg)) +
geom_point(data = df.country_points, aes(x = lon, y = lat), color = "#e60000") +
scale_fill_manual(values = c("#CCCCCC","#e60000")) +
labs(title = 'Countries with highest "talent competitiveness"'
,subtitle = "source: INSEAD, https://www.insead.edu/news/2017-global-talent-competitiveness-index-davos") +
theme(text = element_text(family = "Gill Sans", color = "#FFFFFF")
,panel.background = element_rect(fill = "#444444")
,plot.background = element_rect(fill = "#444444")
,panel.grid = element_blank()
,plot.title = element_text(size = 30)
,plot.subtitle = element_text(size = 10)
,axis.text = element_blank()
,axis.title = element_blank()
,axis.ticks = element_blank()
,legend.position = "none"
)
Here's what the ggplot code produces:
Let's break this down a little.
You'll notice that we're plotting the whole world map. We're able to do this because we used the
Now take a look at the highlighted countries. These are the 10 countries in the data that we scraped. How did we highlight them? We used the "flag" variable that we created,
One more thing to point out. We used 2 distinct layers in this map: the country map (given by
To do this, you mostly just need the foundations
Loyal Sharp Sight readers and talented data scientists will know the drill: learn the foundations.
ggplot2 dplyr tools, especiallymutate() - a few tools from base R like
cbind ,rbind ,ifelse() - a few tools from
stringr
If you're a beginner, the full code in this blog post might look complicated, but you need to realize that there are only a couple dozen core tools that we're using here. That's it.
That's why I strongly recommend that you master the foundations first. If you can master a few dozen critical, high-frequency tools, a whole world of possibilities will open up. I repeat: if you want to master data science, master the basics.
Sign up to learn data science
People who know data science will have massive opportunities in the age of big data.
Sign up now to get our free Data Science Crash Course, where you'll learn:
- a step-by-step data science learning plan
- the 1 programming language you need to learn
- 3 essential data visualizations
- how to do data manipulation in R
- how to get started with machine learning
- and more ...
Most exciting to me. Thank you very much
thanks. after the USA plots, I was looking forward to a post with data manipulation + plotting with explanations. this is great.
I stuck in the step
df.global_talent_RAW %
html_nodes(“table”) %>%
extract2(1) %>%
html_table()
with the folliwng message
Error in utils::type.convert(out[, i], as.is = TRUE, dec = dec) :
invalid multibyte string at ”
How could I get rid of it? Please advise. Thanks.
I follow the tutorial instruction, and do generate a map. However, the original map is shown in the default plot window, which is a square, and the map looks awkward. Is there a way to show the map in the plot window with a right ratio between width and height?
Hi there,
Great blog!
I am trying to do something similar with world map focusing on Europe.
I managed to get points on the map using ggmap func.
But I also am trying to color different countries according to refugees acceptance-rejection ratio (accepted/rejected).
Here is what I did:
refDF <- read.csv("C:/…/Refugees acceptance.csv", stringsAsFactors = FALSE)
refDF$X<- factor(refDF$X)
colnames(refDF) <- c("region")
mapdata <- map_data("world")
mapdata <- left_join(mapdata, refDF, by="region")
and that takes forever to complete the join.
The refDF looks like
region, acceptance rejection ratio
Germany 100000 1000 100
Russia 200000 5000 40
etc'
What could be the problem?
I'm waiting for very long time (last night I terminated after more than an hour)..
Just came across this article which has helped me a ton and signed up for your crash course. I’m working on a similar map. I’d like the color of the country to change based on the rank. How would I go about doing that? Thank you!
When you call
ggplot(), you’ll want to use thefill=parameter insidegeom_polygon().The syntax will looks something like …
But to get this to work right, you’ll need to do some additional data wrangling, and you’ll have to change the
scale_fill_function.