This tutorial will show you how to use the Pandas head technique to get the first few rows of a Pandas dataframe.
Here, I’ll explain what the technique does, explain the syntax, and show you a few clear examples of how to use it.
If you need something specific, you can click on any of these following links, and it will take you to the appropriate section in the tutorial.
Table of Contents:
A Quick Introduction to the Pandas ‘head’ Technique
So what does the head() method do?
The Pandas head() method is very simple.
The head() method returns the first few rows of a Pandas dataframe.
To help you understand that though, I’ll explain a few things about Pandas and give you a quick refresher on Pandas dataframes.
Pandas is a Data Manipulation Toolkit for Python
Let’s quickly review Pandas, since understanding Pandas is important for understanding the Pandas head technique.
Pandas is a data manipulation package for the Python programming language.
We use Pandas tools to “wrangle” or manipulate data.
But specifically, we typically use Pandas to work with data that exists within a particular data structures.
Pandas works with Dataframes and Structured Data
Pandas has two primary data structures. There’s the Pandas Dataframe and there’s the Pandas Series object. (In this tutorial, we’ll mostly be talking about the Pandas dataframe.)
Pandas dataframes have a row-and-column structure.
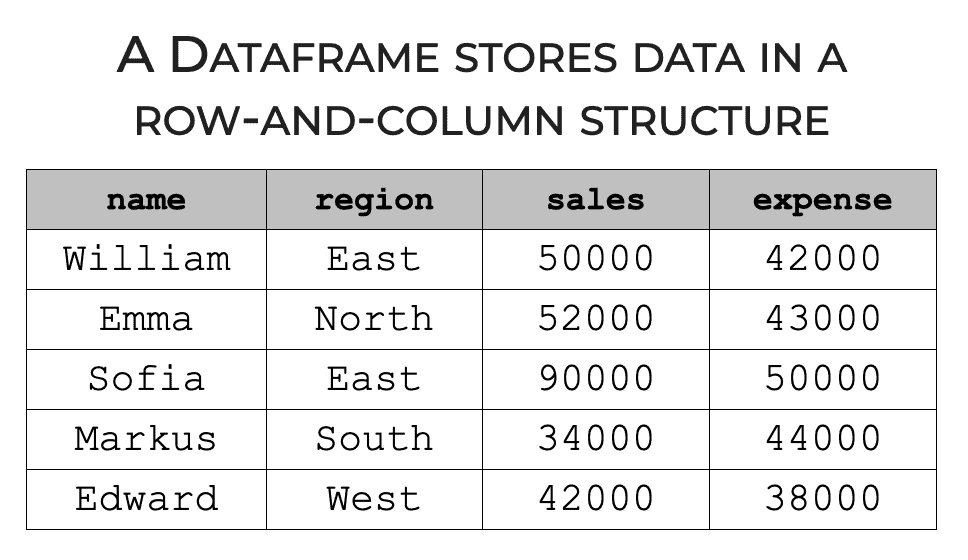
In this sense, dataframes are similar to Excel spreadsheets. They have rows of data (i.e., data records) and columns (i.e., variables).
Pandas has Tools for Working with Dataframes
Pandas has several tools for creating these dataframes, but also tools for inspecting, reshaping, and manipulating these dataframes.
For example, you can use the Pandas DataFrame() function to create a dataframe from raw data.
You can use the Pandas assign method to add new variables to a dataframe.
And there are several tools to inspect the contents of a dataframe.
That’s where the Pandas head() method comes in.
The Pandas ‘head’ method retrieves the first few rows of data
The Pandas head() method is very simple. It retrieves the first few rows of data from a Pandas dataframe.
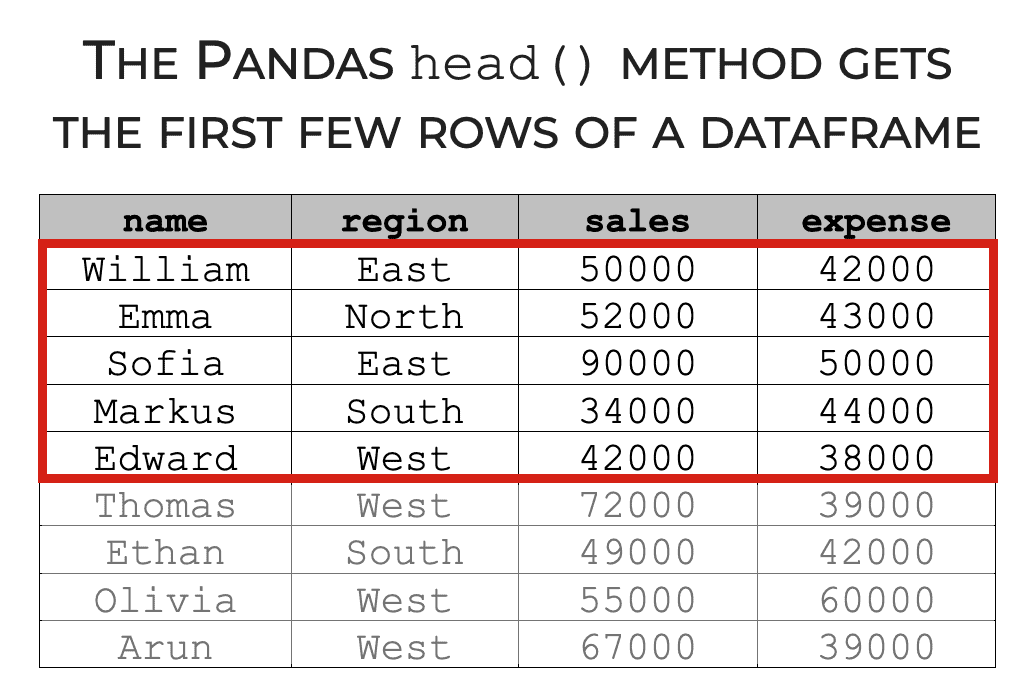
We often use this method for simple data inspection and as part of the data analysis workflow. In many instances, we need to look at our data to see what it contains, and the head() method is one of our primary tools for getting that information.
Having said that, we can change the syntax slightly to change exactly how the method works.
So with that in mind, let’s look at the syntax.
The syntax of Pandas dataframe.head
Here, I’ll walk you through the syntax of the Pandas head() method.
Keep in mind that the explanation that follows assumes that you already have a Pandas dataframe that you’re working with. You can see an example of how to create a Pandas dataframe in the examples section.
dataframe.head syntax
Ok. Let’s look at the syntax for the dataframe.head method.
Essentially, you start by typing the name of your dataframe. Here, for the sake of simplicity, we’ll assume that the dataframe is called your_dataframe.
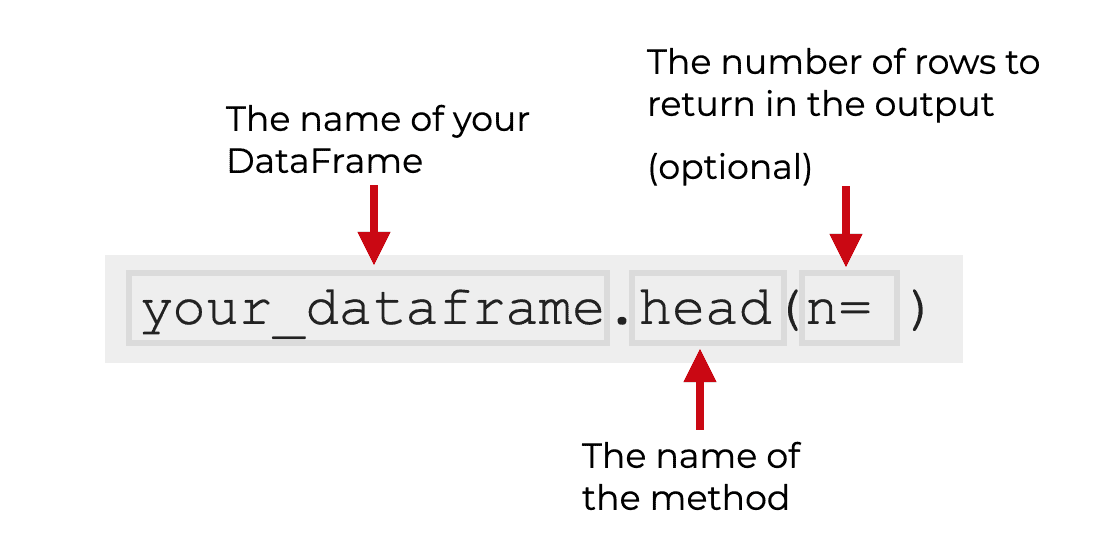
Once you type the name of your dataframe, you use so-called “dot” notation to call the head() method. That is, you type the name of the dataframe, then a ‘dot’, and then the method name, head().
That’s typically all there is to it.
Having said that, there is one optional parameter that can help you change the behavior of the head() method slightly.
The parameters of Pandas dataframe.head
The Pandas head() has only one parameter, and that’s the n parameter.
Let’s take a look at that.
n (optional)
The n parameter enables you to specify how many rows to return.
By default, this is set to n = 5, so by default, the head() method will return the first 5 rows of data.
Obviously though, you can use this parameter explicitly to specify a different number of rows.
So for example, if you set n = 3, the head() method will return the first 3 rows of data.
That being said, let’s take a look at some examples so you see how this technique actually works.
Examples: How to get the first few rows of a Pandas dataframe
Here, I’ll show you a few examples of how to use the Pandas head() method.
You can click on either of the links, and it will take you to the appropriate example.
Examples:
Run this code first
Before you run the examples, you actually need to do two things: you need to import Pandas, and you need to create the dataframe that we’ll be working with.
Import Pandas
First, you’ll simply need to import Pandas.
If you’re reading this blog post, you’ve probably already done this and know how to do it …
But just in case, you can import Pandas with the following code:
import pandas as pd
Once we do this, we’ll be able to call Pandas functions with the prefix ‘pd‘.
Create Dataframe
Next, we’ll create the dataframe that we’re going to work with.
To do this, we’re going to use the Pandas DataFrame() method to create a dataset called sales_data.
sales_data = pd.DataFrame({"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
And let’s print it out so you can see the contents.
print(sales_data)
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
3 Markus South 34000 44000
4 Edward West 42000 38000
5 Thomas West 72000 39000
6 Ethan South 49000 42000
7 Olivia West 55000 60000
8 Arun West 67000 39000
9 Anika East 65000 44000
10 Paulo South 67000 45000
As you can see, sales_data contains 11 rows of data with information about revenues (i.e., sales) and expenses.
EXAMPLE 1: How to return the first 5 rows of data (default)
Now that we have our data, let’s use the head() method to retrieve the first few rows of data.
Here, we’re going to use the head() method with the default settings.
Let’s take a look.
sales_data.head()
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
3 Markus South 34000 44000
4 Edward West 42000 38000
Explanation
Here, we called the head() method with the default settings. That is, we didn’t use any parameters.
By default, the n parameter is set to n = 5, so by default, the head() method has retrieved the first 5 rows.
Notice also that we called the method just like we call all methods in Python. We typed the name of the object (sales_data), then a ‘dot’, and then the name of the method, head().
This is as simple as it gets.
EXAMPLE 2: How to specify a specific number of rows
For the second and final example, we’ll modify things a little bit.
In the previous example, we used the default settings, which caused the head() method to retrieve 5 rows of data.
Here, we’ll change that slightly.
We’ll use the n parameter so that the head method returns only 3 rows.
Let’s take a look.
sales_data.head(n = 3)
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
Explanation
This is actually very simple.
Here, we set the n parameter to n = 3. This caused Pandas head() to return the first 3 rows of data.
Obviously, we can set the argument to almost any value we want. For example, if we had a larger dataset, we could set n = 10, and it would return 10 rows. We could set n = 20, and it would return 20 rows. And so on.
Having said that, since we often use the Pandas head method for simple data inspection, we’ll typically set n to somewhere between 3 and 10.
Typically, when we use this technique, we just want to get a quick view of what the data looks like. If we set n to a large value, it can sometimes show too much data, and can make the output hard to understand at a glance.
You can experiment though and try different values. Different datasets sometimes need more or less data inspection.
Leave your other questions in the comments below
Do you have questions about the Pandas head technique?
Is there something we didn’t cover?
If so, leave your questions in the comments section near the bottom of the page.
If you want to master Pandas, join our course
In this tutorial, I’ve explained how to use the head method, but we’ve really just scratched the surface of what Pandas can do. If you want to master data wrangling in Pandas, you’ll need to learn a lot more.
That said, if you’re serious about learning and mastering Pandas, you should join our premium online course, Pandas Mastery.
Pandas Mastery is our online course that will teach you everything you need to know about data manipulation with the Pandas package.
Inside the course, you’ll learn all of the essential techniques, like:
- how to create dataframes
- inspecting dataframes
- subsetting dataframes
- filtering data by logical conditions
- adding new variables
- reshaping data
- working with Pandas indexes
- and much more …
Additionally, you’ll discover our unique practice system that will enable you to memorize all of the syntax you learn. If you practice like we show you, you’ll memorize the syntax in only a few weeks!
You can find out more here: