In this tutorial, I’ll show you how to use the Pandas sum technique. The sum() technique sums up the numeric values in a Pandas dataframe or Pandas series.
So in the tutorial, I’ll explain how we use the technique, how the syntax works, and I’ll show you step-by-step examples.
If you need something specific, just click on any of the following links.
Table of Contents:
Ok. Let’s start with an introduction to Pandas sum.
A quick introduction to Pandas Sum
The Pandas sum technique is a tool for data exploration and data manipulation in Python.
We use the sum technique to sum up the values in a Pandas dataframe or Series.

Although it’s most common to use this technique on a single dataframe column, the Pandas sum technique works on:
- whole Pandas dataframes
- Pandas Series objects
- individual dataframe columns
As I mentioned previously, we typically use the sum() technique for data exploration. But it’s often used for data analysis as well. There are many instances where we need to compute aggregate metrics for a variable or subset of variables. When we do this, summing up a numeric value is extremely common.
There are even instances when you’ll group your data by a categorical variable, and then sum it up by the grouping variable.
I’ll show you examples of these applications in the examples section.
Before we look at examples though, we need to understand the syntax.
With that in mind, let’s look at the syntax of the Pandas sum technique.
The syntax of Pandas sum
There are actually a couple different ways to use the Pandas sum technique, so I’ll cover:
- dataframe syntax
- Series syntax
- column syntax (inside dataframes)
A quick note
Before we look at the syntax, I need to point out that all of the syntax explanations assume that you’ve already imported Pandas and that you have a dataframe created.
You can import pandas with the following code:
import pandas as pd
And if you need a review of Pandas dataframes, you can read our introduction to Python dataframes.
Dataframe Syntax
First, let’s start with the syntax for using sum() on a dataframe.
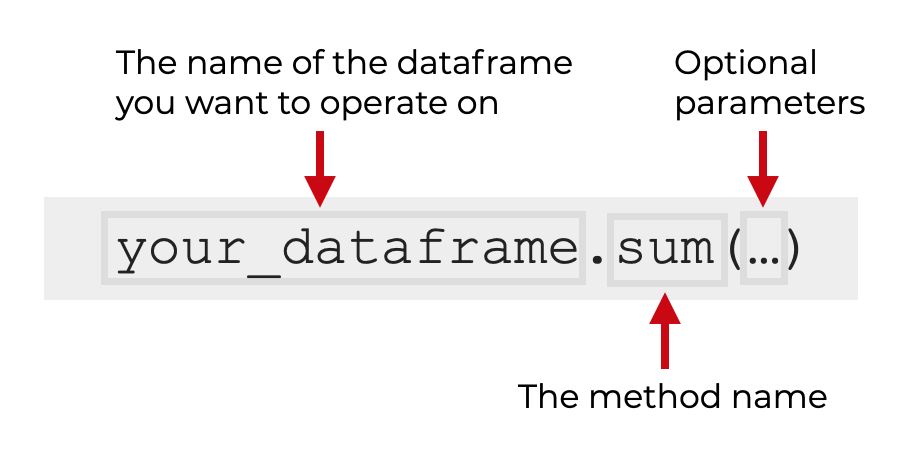
You call the sum() method like you call all Pandas dataframe methods.
First you type the name of the dataframe, and then .sum().
That’s really it!
When you use sum() on a dataframe, it will operate on all of the columns by default. It will sum up numeric variables, but the output for other variable types (like strings) make look like nonsense. So, it’s not always best to use sum() on a full dataframe.
Note that there are also some optional parameters that you can use to modify the output slightly. I’ll explain those in the parameters section.
Series Syntax
Next, let’s look at the syntax for a Pandas Series.
The syntax for using Pandas sum on a Series is very similar to the syntax for a dataframe.
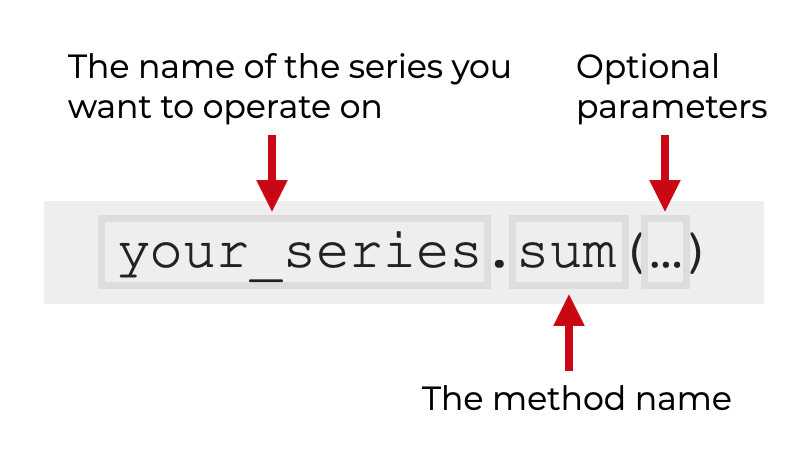
You’ll simply call the name of the Series, and then .sum().
Again, there are some additional parameters that you can use to modify the output. I’ll explain those in the parameters section.
Dataframe Column Syntax
You can also call the sum() method on single columns inside of a dataframe.
Remember that dataframe columns are actually Pandas Series objects.
That being the case, using sum() on a column requires two steps:
- retrieve the column using dot syntax
- call the
sum()method
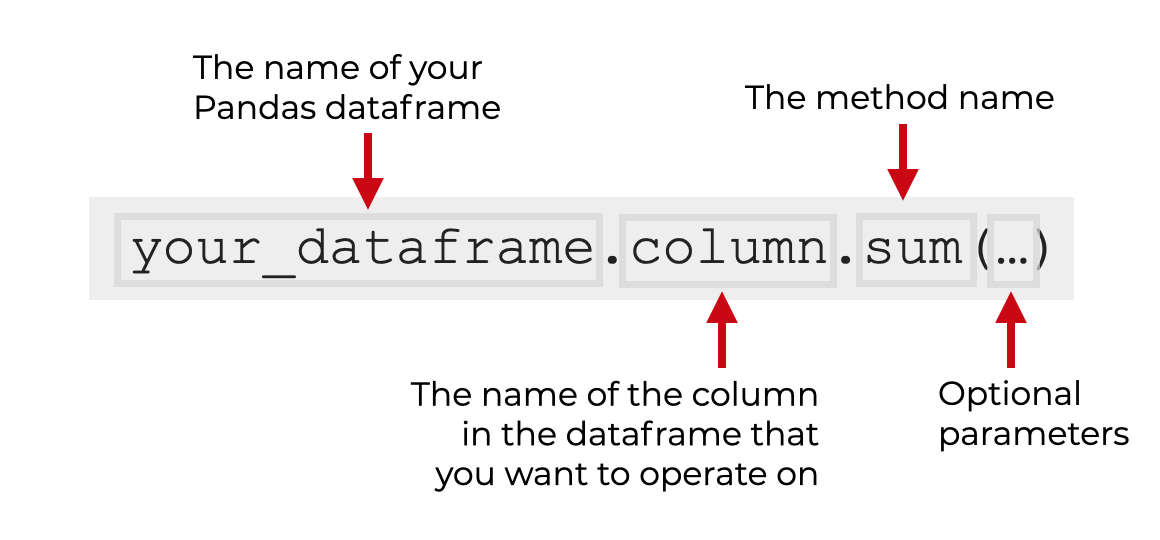
So if your dataframe is name your_dataframe, and the column is named column, you’ll use the code your_dataframe.column.sum() to sum up the values of that column.
Once again, there are some additional parameters that you can use to modify the output. I’ll explain those in the parameters section.
Let’s take a look at those parameters.
The parameters of Pandas sum
There are several parameters that can change how the Pandas sum method works, but there’s only one that I think you should know: numeric_only.
There are some additional parameters, like axis, skipna, level, and min_count, but these parameters are confusing, rarely used, and there are better ways that enable the same effect. That being the case, I’m not going to discuss those extra parameters.
Ok, let’s look at numeric_only.
numeric_only
If you set numeric_only = True, sum() will operate only on int, float, and bool data types (i.e. numeric data or data that can be directly coerced to numeric, in the case of boolean data).
By default, this is set to numeric_only = None. In this case, sum() attempts to sum all variables. This can lead to some strange or nonsensical output. It’s often better to set numeric_only = True, or to use sum() on a single dataframe column.
This parameter is only available when you use sum() on a whole dataframe.
Examples: how to sum records in a Pandas dataframe or Pandas series
Ok. Now that we’ve looked at the syntax, let’s take a look at some examples.
Examples:
- Sum a single dataframe column
- Use sum on an entire dataframe
- Sum up only numeric variables
- Compute sums, grouped by a categorical variable
Run this code first
Before you run these examples, you’ll need to run some preliminary code.
In particular, you need to:
- Import necessary packages
- Create a dataframe
Let’s do those one at a time.
Import Packages
First, let’s just import Pandas.
import pandas as pd import seaborn as sns
We need to import Pandas because the sum() method is part of Pandas.
Create sales_data dataframe
Next, let’s create a dataframe called sales_data.
sales_data = pd.DataFrame({"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East",np.nan,"East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,np.nan,42000,72000,49000,np.nan,67000,65000,67000]
,"expenses":[42000,43000,np.nan,44000,38000,39000,42000,np.nan,39000,44000,45000]})
And let’s print it out:
print(sales_data)
OUT:
name region sales expenses
0 William East 50000.0 42000.0
1 Emma NaN 52000.0 43000.0
2 Sofia East 90000.0 NaN
3 Markus South NaN 44000.0
4 Edward West 42000.0 38000.0
5 Thomas West 72000.0 39000.0
6 Ethan South 49000.0 42000.0
7 Olivia West NaN NaN
8 Arun West 67000.0 39000.0
9 Anika East 65000.0 44000.0
10 Paulo South 67000.0 45000.0
As you can see, this is a Python dataframe with 4 variables: name, region, sales, and expenses.
We’ll be able to sum up at least two of these variables.
EXAMPLE 1: Sum a single dataframe column
Let’s start simple.
Here, we’ll sum the values from the sales variable.
Let’s run the code, and then I’ll explain:
sales_data.sales.sum()
OUT:
554000.0
Explanation
Here, we summed up the values of the sales column in our dataframe.
Doing this is a two step process:
- retrieve the column from the dataframe
- call the
sum()method
So when we use the syntax sales_data.sales, this retrieves the sales variable from the sales_data dataframe.
Remember though, that individual dataframe columns are actually Pandas series objects.
So by calling .sum() after that, we’re actually using the “Series syntax” for the Pandas sum.
EXAMPLE 2: Use sum on an entire dataframe
Next, let’s use sum on a whole dataframe.
sales_data.sum()
OUT:
name WilliamEmmaSofiaMarkusEdwardThomasEthanOliviaA... sales 554000 expenses 376000 dtype: object
Explanation
Here, use called the sum() method on the whole sales_data dataframe.
As you can see, it automatically summed up both sales and expenses – the two numeric variables in the dataframe.
But it also operated on the name variable, which produces some strange output. For name variable, the method is actually concatenating the values. The output actually makes no sense, so it’s of little value.
Additionally, notice that it excluded the region variable from the output. That’s because it’s a string variable that has a NaN value.
EXAMPLE 3: Sum only the numeric variables of a dataframe
Next, let’s use the sum method on only the numeric variables.
In the previous example, we used sum() on a dataframe, but it attempted to operate on all variables, including the non-numeric variables. This produced some strange output.
So here, we’ll use the numeric_only parameter to operate on the numeric variables:
sales_data.sum(numeric_only = True)
OUT:
sales 554000.0 expenses 376000.0 dtype: float64
Explanation
This is pretty straight-forward.
The sales and expenses variables are the only two numeric variables in the dataframe.
When we use sum on a dataframe and set numeric_only = True, the method only operates on the numeric variables.
This can be a quick way to evaluate the numeric variables of a dataset.
EXAMPLE 4: Compute sums, grouped by a categorical variable
Finally, let’s calculate a “grouped” sum.
Here, we’re going to group our data by a categorical variable, and then sum up a numeric variable.
Specifically, we’ll group by region and sum up sales:
(sales_data .groupby(['region']) .sales .sum() )
OUT:
region East 205000.0 South 116000.0 West 181000.0 Name: sales, dtype: float64
Explanation
Here, we calculated the total sales, by region.
To do this, we actually needed to use multiple steps. We:
- grouped the data by
regionusinggroupby() - retrieved the
salesvariable - called the
sum()method
Notice as well that the whole expression is enclosed inside of parenthesis. This is an uncommon syntax that you’re unlikely to see elsewhere but it’s extremely useful for data cleaning and data analysis with Pandas. We can apply this syntax to use multiple Pandas methods in a “chain.”
Again: calculating grouped sum() like this is very important for data analysis. And it’s possible to do things that are even more complex and useful, if you really understand the details of Pandas.
Leave your other questions in the comments below
Do you have other questions about the Pandas sum technique?
Is there something that I haven’t covered here, that you’re still confused about?
If so, leave your question in the comments section below.
To learn more about Pandas, sign up for our email list
This tutorial should have helped you understand the Pandas sum technique, and how it works.
But if you want to master data wrangling and data exploration with Pandas, there’s a lot more to learn.
There’s even more to learn if you want to learn data science in Python.
That said, if you’re ready to learn more about Pandas and data science in Python, then sign up for our email list.
When you sign up, you’ll get free tutorials on:
- Base Python
- NumPy
- Pandas
- Scikit learn
- Machine learning
- Deep learning
- … and more.
We publish free data science tutorials every week. When you sign up for our email list, we’ll deliver these free tutorials directly to your inbox.