In this blog post, I’ll show you how to rename columns in R.
This is pretty straightforward if you know how to do it properly, but there are also some little challenges in renaming variables.
So very briefly, I’ll explain why renaming variables in a dataframe can be a little confusing in R.
Then, I’ll show you the “best” way to rename variables in R.
Towards the end of the post, I’ll show you a few other ways to rename variables in R … although I strongly prefer only one of these methods.
The major challenge with renaming columns in R
The major challenge with renaming columns in R is that there is several different ways to do it.
The old ways to rename variables in R are a little awkward
If you’re relatively new to R, you need to understand that R is sort of an old programming language. R first appeared in 1993.
With due respect to the people who initially created the language and developed it in its early stages, the structure of the initial parts of the language has some quirks. Syntactically, many tools and functions from “early R” are poorly named. And many methods of doing things are a little syntactically awkward. Renaming variables is no exception.
R has several different ways to rename variables in a dataframe
Moreover, R has several different ways to rename variables in a dataframe.
Because R is open source, and because the language is relatively old, several different ways to rename variables have come about. If you just do a quick google search, you’ll find several different ways to rename the columns of an R dataframe. In particular, if you search how to do this on Stack Overflow, you’ll typically find 3 to 5 different suggestions for how to do this.
The problem is that many of those suggestions are several years out of date. Stack Overflow has suggestions dating to 2011 or earlier that explain how to rename variables, but since then, new techniques have been developed. In particular, tools from dplyr have made simple data manipulation tasks much easier.
Performing simple tasks like renaming variables or adding columns to a dataframe have become dramatically easier in the last few years. And it’s not just that they are easier to do, but they are easier to remember. The syntax for accomplishing these tasks has been simplified.
So when you are trying to learn how to do something simple like rename a variable in R, the major challenge isn’t finding a way to do it … it’s easy to find a variety of ways.
The major challenge is finding the best way … the way that will be syntactically easy to write, easy to read, and easy to remember.
The best way to rename columns in R
In my opinion, the best way to rename variables in R is by using the rename() function from dplyr.
As I’ve written about several times, dplyr and several other packages from R’s Tidyverse (like tidyr and stringr), have the best tools for core data manipulation tasks.
Like I just mentioned, R almost always has several different ways to do things, but dplyr and the Tidyverse have provided tools that are easy to use, easy to read, and easy to remember. Whether you’re adding a new column to a dataframe, creating substrings, filtering your dataframe, or performing some other critical data manipulation, dplyr and the Tidyverse almost always have the best solution now.
Having said all of that, let’s talk about rename().
How to use the rename() function
To show you how rename() works, let’s create a simple dummy dataset with slightly messed up variable names.
library(tidyverse)
df <- tibble(
OriginalNumericVar = 1:3
,Original.Character.Var = c('A', 'B', 'Z')
)
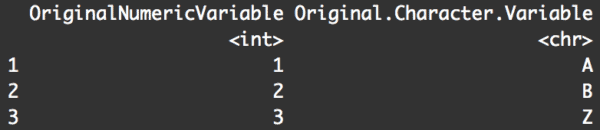
Here, we've used the tibble() function to create our dataframe, df. Note that the dataframe has two variables, a numeric variable and a character variable.
Notice as well that the names are a little messed up. This of course is sort of a matter of style and taste, but there are a few things "wrong" with these. First, the naming conventions are not consistent. OriginalNumericVar is using "camel case" and Original.Character.Var is using dots to separate words. Moreover, they both start with capital letters (generally, there's not a good reason to start variable names with capital letters).
Personally, I strongly prefer "snake case" where words in a variable name are separated by underscores ("_"). I just think snake case is easier to read.
So, we're going to rename these variables and transform the names from their existing state to snake case.
We can do this with the rename() function.
Let's start by just renaming one variable:
rename(df, numeric_var = OriginalNumericVar)
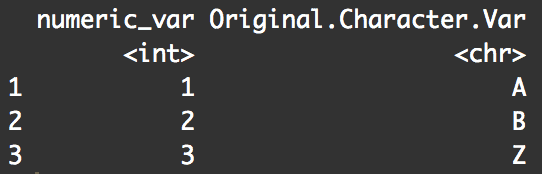
You can see that the operation changed the name of OriginalNumericVar to numeric_var.
So how did this work? You can see that we're calling the rename() function, and the first argument of the function is just the name of the dataframe that we want to modify (the dataframe with the variables we want to rename).
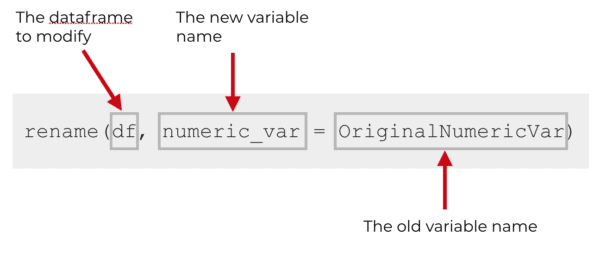
The second argument is actually an expression with a pair of variable names: the new name and the old name. So the left hand side of the second argument is the new name, numeric_var, and the right hand side of the expression is the old name, OriginalNumericVar.
That's all there really is to it. You just need to use the rename() function and supply the new names and old names with the structure new_name = old_name.
Having said that, let's take a look at a few other details so you understand how to use the rename function properly.
How to rename multiple variables with the rename function
Renaming multiple variables with rename() is extremely easy.
Basically, you just need to supply all of the pairs of new and old variables, separated by commas. Here's an example using our dummy dataframe, df.
rename(df, numeric_var = OriginalNumericVar
, character_var = Original.Character.Var
)
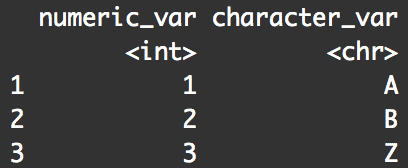
Structurally, this is almost exactly the same as the syntax where we renamed only one variable. The only difference is that in this case we have two "pairs" of new/old names separated by a comma. Notice that they are on different lines here, but they don't need to be ... I just typically put them on separate lines for enhanced readability.
Using the rename function with pipes
One of the advantages of working with the Tidyverse (the set of R packages including dplyr, ggplot2, stringr, and tidyr) is that you can perform data manipulation in a "waterfall" pattern by using the pipe operator, %>%.
If you're new to the Tidyverse and you don't know about the pipe operator, I highly recommend that you learn it and start to use it. It's a game changer in terms of data science workflow.
I won't explain all of the details of how it works, but I want to show you a simple example of how you can use rename() with the pipe operator to perform more complex data manipulation.
df %>%
rename(numeric_var = OriginalNumericVar
,character_var = Original.Character.Var) %>%
mutate(exponential_var = exp(numeric_var))
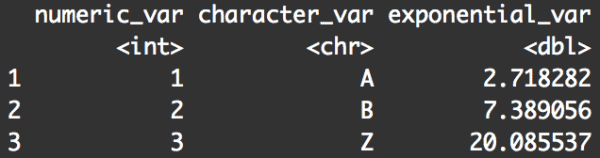
The first few lines of this example are very similar to the previous example where we renamed both variables in the dataframe. The only difference is that we did not reference the dataframe, df, inside of the rename() function. Instead, I pulled df outside of the function and used the pipe operator to "pipe" the data into the rename() function.
Syntactically, this is slightly different, but functionally, it produces the same result.
You'll also see that after executing the rename() function, I used the pipe operator once more. I piped the output of rename() into the mutate() function. Inside of the mutate() function I'm creating a new variable, exponential_var.
Ultimately, these four lines of code produce a modified dataframe with renamed variables and one new variable.
This is an example of using several tools in series to quickly perform data manipulation. Although it's true that you could perform the two operations separately without pipes, the piped version is cleaner. It's also very easy to understand once you understand how the pipe operator works. Moreover, this piping-methodology helps facilitate proper data manipulation workflow. Data manipulation is typically performed in a sequential fashion, like a waterfall, and the pipe operator syntax reflects this. It enables you to modify a dataset sequentially, step-by-step downward, like a waterfall.
I'll leave my complete thoughts on the pipe operator for a future post. But I wanted to show you a quick example and explain that I think the piped version of the syntax. I also want you to understand that the piped syntax is excellent for data manipulation workflow. You should start using it.
A quick reminder: rename() does not change the original dataframe
Just a quick reminder to you, if you don't have a lot of experience with dplyr and the Tidyverse.
The rename() function does not change the original dataframe.
To illustrate this, let's take a look at our initial example:
df <- tibble(
OriginalNumericVar = 1:3
,Original.Character.Var = c('A', 'B', 'Z')
)
rename(df, numeric_var = OriginalNumericVar)
This renamed our variable OriginalNumericVar to the new variable name numeric_var, right?
Yes, but maybe not in the way that you think.
This example does not change the original dataframe df.
To see this, just print out df after you've run the rename() code.
print(df)
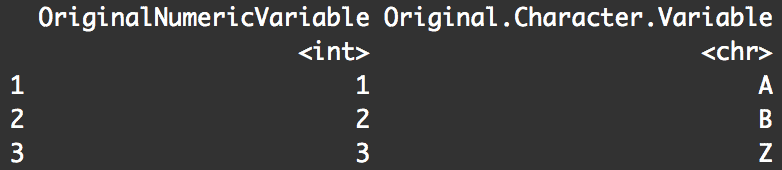
You can see, the variable name is unchanged. What the hell?
The problem is that rename() does not change the original dataframe. In fact, essentially none of the dplyr functions directly modify the original dataframe. They only produce a new dataframe as an output. If you don't save that output, then it's just sent directly to the terminal (i.e., your screen). Then it's lost and gone forever.
If you want to keep the changes produced by rename(), you need to use the assignment operator (<-) and save the output of rename() to a dataframe name. Here's an example.
df_renamed <- rename(df, numeric_var = OriginalNumericVar)
Here, I've renamed the new daframe df_renamed. You could also use the original dataframe name, df. That would look like this:
df <- rename(df, numeric_var = OriginalNumericVar)
Just remember ... if you do it this way, you will overwrite your data. Here in this example above, I've just over-written the dataframe df. So if you do this, you need to make sure that your code is absolutely correct. I recommend that you test your code a few times and make sure it works properly before you save the output to the original dataframe name and overwrite the data.
A few other ways to rename columns in R
There are a few other ways to rename columns in R.
As I mentioned at the beginning of this blog post, I really don't recommend these. I think all of them are inadequate in some way, and rename() is almost always a better option.
Having said that, I'll quickly show you a couple, just so you know them when you see them.
Rename columns with the select() function
You can actually use the select() function from dplyr to rename variables.
Here's an example of how:
df <- tibble(
OriginalNumericVar = 1:3
,Original.Character.Var = c('A', 'B', 'Z')
)
select(df, numeric_var = OriginalNumericVar)
Syntactically, this is almost exactly the same as our code using rename(). We just supply the dataframe and the pair of variable names – the new variable name and the old variable name.
Here's the problem. When you rename a variable using the select() function, it only keeps the variable that you've renamed:
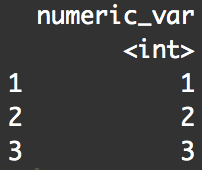
Notice that the other variable (Original.Character.Var) is gone. That's because we did not "select" it ... we didn't indicate that we wanted to keep it or rename it inside of the select() function.
Because of this, I typically think that dplyr::rename() is a better tool for renaming variables in R.
Rename columns with the colnames() function
You can also rename variables with the colnames() function.
Here's an example:
df <- tibble(
OriginalNumericVar = 1:3
,Original.Character.Var = c('A', 'B', 'Z')
)
colnames(df) <- c('numeric_var', 'character_var')
Here, we're using the colnames() function to specify new column names. To do this, we're supplying a vector of new variable names: c('numeric_var', 'character_var'). We're using the assignment operator to assign that vector of names as the new "column names."
The issue with this way of doing it is that you need to supply names for all of the columns.
There's also a way to rename columns one at a time using the colnames() function, but it's syntactically a lot more complicated. It's unnecessarily complicated. It's complicated enough that I won't even bother to show it to you .... you should just use the dplyr rename() function.
There are even more ways to rename columns in R ...
In this post, I've shown you a few ways to rename variables.
As it turns out, there are even more ways to rename a column in R. Many of those ways are "old fashioned" ways to rename columns. They rely on using syntax from base R. Unfortunately, they are syntactically more complicated. This makes them harder to learn, harder to use, harder to read, and harder to debug.
I'll just say it once more: if you need to rename variables in R, just use the rename() function. If you're a beginner, it's the best method and the easiest to learn. For more advanced users, it's still the best tool for the job, 95% of the time.
Sign up now for free data science tutorials
Don't try to learn data science on your own.
When you're learning data science, there are lots of tools and techniques that are a waste of time. Much like with renaming variables, there's often many ways to accomplish a given task.
If you want to rapidly master data science, you should focus on the "best" tools and forget the rest. This will save you massive amounts of time.
If you want to learn the right tools, and learn how to master them quickly, then sign up for our email list.
Sharp Sight teaches data science. Moreover, we will show you how to master data science faster than you though possible, by teaching you the best tools and showing you how to practice them.
If you sign up now, you'll get weekly data science tutorials delivered to your inbox. These will include tutorials about data science syntax. They will also include tutorials about learning tips and strategies that will accelerate your progress.
Additionally, by signing up for our email list, you'll also get immediate access to our Data Science Crash Course.
important realization for me! “none of the dplyr functions directly modify the original dataframe.”
we hope some lessons on on linear regression. logistic, decision tree for non-statistical students like me . Lot of content related to this subject are available on the net- but not in a “simple to understand” method
Regards
Ramachandran
Agreed … a lot of articles on ML are hard to understand.
I plan to write several blog posts on regression, trees, and ML sometime soon.
myDataFrame$newVarName <- myDataFrame$oldVarName
myDataFrame$oldVarName <- NULL
Using this old-fashioned “$” syntax is bad practice, and if you don’t understand why you should be using the Tidyverse tools instead, you have a lot to learn.
As a beginner in R, this article was an eye-opener in many ways.
Good to hear that it helped