In this tutorial, I’ll show you how to use the Sklearn Fit method to “fit” a machine learning model in Python.
So I’ll quickly review what the method does, I’ll explain the syntax, and I’ll show you a step-by-step example of how to use the technique.
If you need something specific, just click on any of the following links. The link will take you to the appropriate section in the tutorial.
Table of Contents:
A Quick Introduction to Model Fitting with Sklearn Fit
To understand what the sklearn fit function does, you need to know a little bit about the machine learning process.
Typically, when we build a machine learning model, we have a machine learning algorithm and a training data set.
Remember that a machine learning algorithm is type of algorithm that learns as we expose it to data. To paraphrase Tom Mitchel: a machine learning algorithm is an algorithm that improves performance on a task as it is exposed to data.
So in order for a machine learning algorithm to learn, it must be exposed to some data.
We need to ‘train’ a machine learning algorithm with data
That’s where we use the training data.
The training dataset is an input that we use to enable the machine learning algorithm to “learn”, so it can improve its performance on the task.
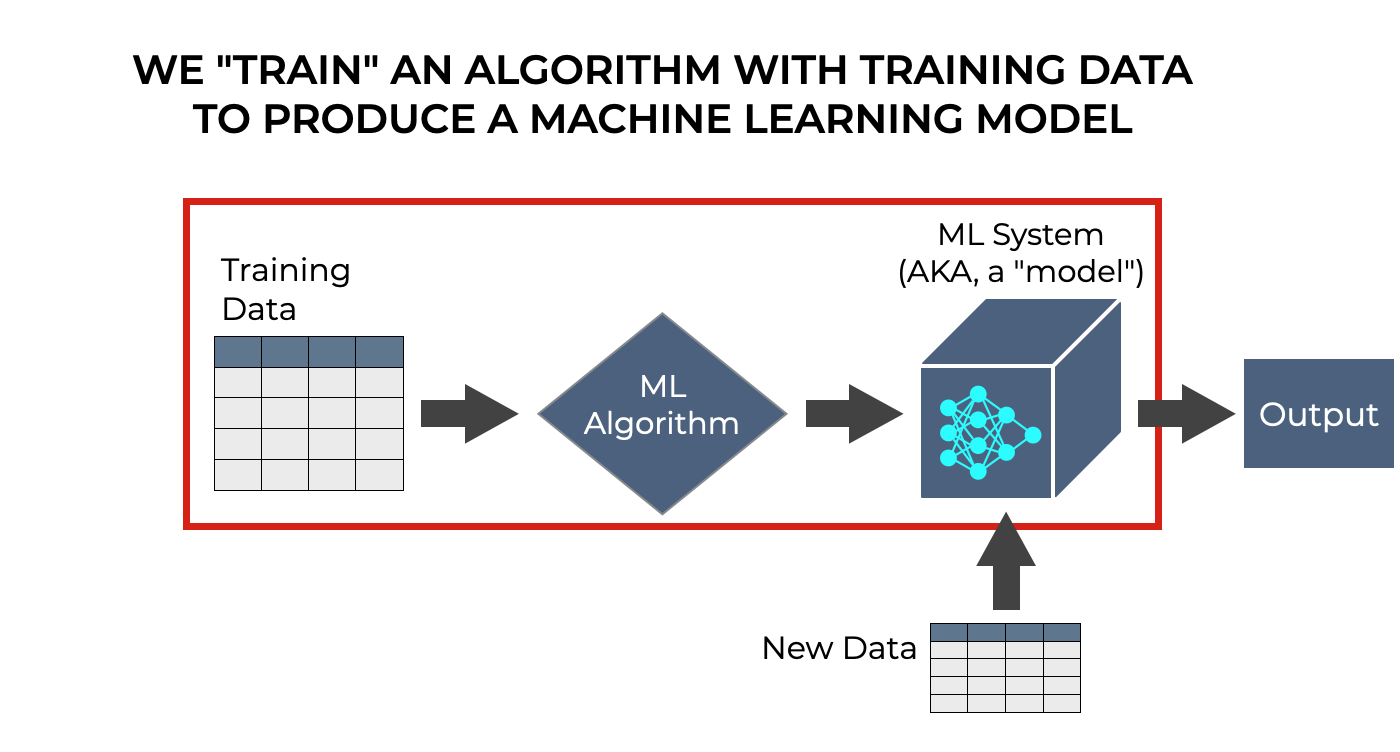
So we have our training data, we feed it into the machine learning algorithm, and the algorithm “learns” how to improve its performance on the basis of that training data.
Later, once the model is “trained” then we can use it to do things, like make predictions.
The Sklearn Fit Method ‘Trains’ the Model
So now that we’ve reviewed the machine learning process at a high level, let’s bring this back to scikit learn.
Scikit learn is a machine learning toolkit for Python. As such, it has tools for performing steps of the machine learning process, like training a model.
The scikit learn ‘fit’ method is one of those tools. The ‘fit’ method trains the algorithm on the training data, after the model is initialized. That’s really all it does.
So the sklearn fit method uses the training data as an input to train the machine learning model.
Then once it’s trained, we can use other scikit learn methods – like predict and score – to continue with the machine learning process.
The Syntax of the Sklearn Fit Method
Now that we’ve reviewed what the sklearn fit method does, let’s look at the syntax.
Keep in mind that the syntax explanation here assumes that you’ve imported scikit-learn and you already have a model initialized, such as LinearRegression, RandomForestRegressor, etc.
‘Fit’ syntax
Ok. Let’s look at the syntax.
When we call the fit method, we need to call it from an existing instance of a machine learning model (for example, LinearRegression, LogisticRegression, DecisionTreeRegressor, SVM).
Once you’ve initialized an instance of a model, then you can call the method.

Then, inside the parenthesis, you provide the features and the target vector (or label vector) of the training dataset. These datasets are sometimes called X_train and y_train.
So for example, if you’re doing linear regression with an instance of the LinearRegression model called my_linear_regressor, you might have the code:
my_linear_regressor.fit(X_train, y_train)
For the most part, that’s all there is to it.
The format of the input data
The X-input to the fit() method, X_train, needs to be in a 2-dimensional format, such as a 2-dimensional numpy array.
If X_train is not in a 2D format, you might get an error. In that case, you’ll need to reshape the X_test data to 2 dimensions.
(I’ll show you this in the upcoming examples section.)
Calling the sklearn fit method more than once
One last note.
If you call the sklearn fit method more than once, then the second time you call the fit method will overwrite anything that was learned the first time you called the method.
Sometimes, you will intentionally want to do this, but be careful. Training a model can take a lot of time and computer processing. Calling the fit method multiple times may be expensive in terms of time and resources. And at the very least, it will remove anything learned by the algorithm in the past.
Example: How to Use Sklearn Fit
Now that we’ve looked at the syntax, let’s look at an example of how to use sklearn fit.
Here, I’ll show you an example of how to use the sklearn fit method to train a model.
There are several things you need to do in the example, including running some setup code, and then fitting the model.
Steps:
Run Setup Code
Before you fit the model, you’ll need to do a few things.
We need to:
- import scikit-learn and other packages
- create some training data
- initialize a model
Let’s quickly do each of those.
Import Scikit Learn and other packages
First, let’s import the packages that we’ll use
We’re going to import scikit learn.
And we’ll also import Numpy and Seaborn. We’ll use Numpy to create some dummy training data, and we’ll use Seaborn to plot the data.
You can import these packages with the following code:
import sklearn import numpy as np import seaborn as sns
Create Training Data
Next, we’ll create some training data.
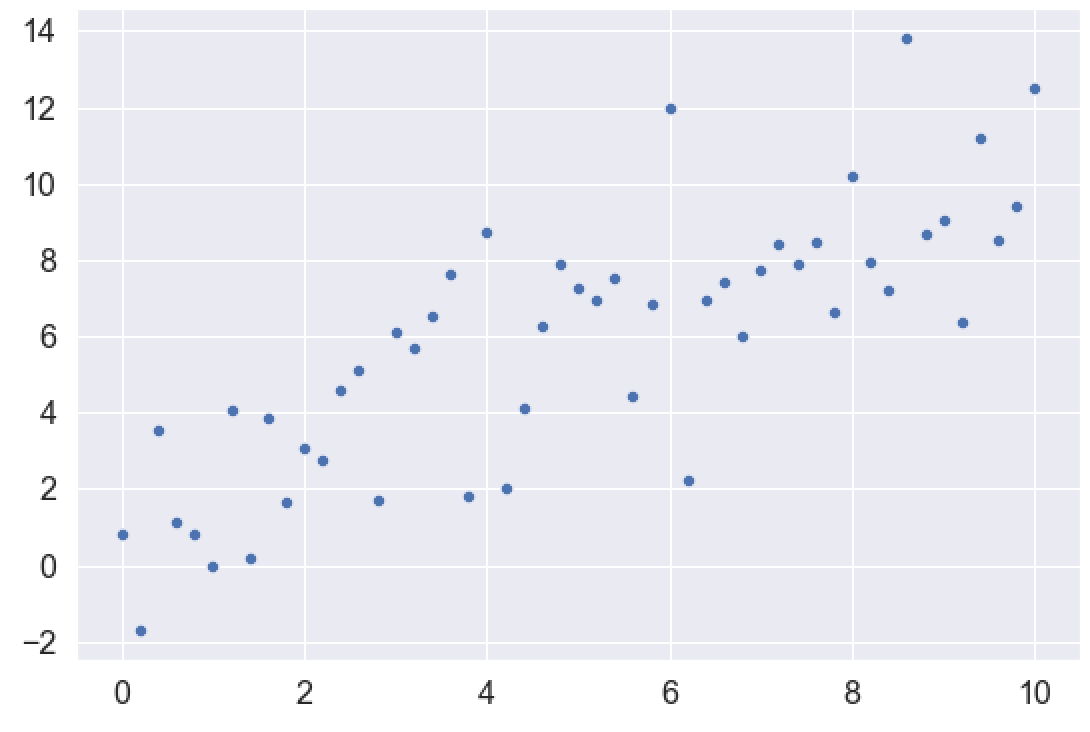
Specifically, we’re going to create some data that’s roughly linear, with a little noise built in.
To do this, we’ll:
- create 51 evenly spaced numbers for the x-axis variable
- create a y-axis variable that’s linearly related to the x-axis variable, with some normally distributed noise
So here, we’ll use Numpy linspace and Numpy random normal to create our variables x_var and y_var.
observation_count = 51 x_var = np.linspace(start = 0, stop = 10, num = observation_count) np.random.seed(22) y_var = x_var + np.random.normal(size = observation_count, loc = 1, scale = 2)
Notice that we’re also using Numpy random seed, to set the seed for Numpy’s pseudo-random number generator, which is used by np.random.normal.
Let’s also plot the data with Seaborn:
sns.scatterplot(x = x_var, y = y_var)
OUT:
Split data
We’ll also split the dataset, using the train-test split function from scikit learn.
from sklearn.model_selection import train_test_split (X_train, X_test, y_train, y_test) = train_test_split(x_var, y_var, test_size = .2)
This gives us 4 datasets:
- training features (X_train)
- training target (y_train)
- test features (X_test)
- test target (y_test)
Initialize Model
Now, we’ll initialize a model object.
Here, we’ll use DummyRegressor for the sake of simplicity.
from sklearn.dummy import DummyRegressor dummy_regressor = DummyRegressor()
Once you run this, dummy_regressor is an sklearn model object, from which we can call the fit method.
Fit the Model
Now, we’ll fit the model:
dummy_regressor.fit(X_train.reshape(-1,1), y_train)
Here, we’re fitting the model with X_train and y_train. As you can see, the first argument to fit is X_train and the second argument is y_train.
That’s typically what we do when we fit a machine learning model. We commonly fit the model with the “training” data.
Note that X_train has been reshaped into a 2-dimensional format.
Predict
Commonly, after we fit a model, we then predict new output values, based on the test features (X_test). (Note that X_test needs to be in a 2D format, so we’ll reshape it with Numpy reshape.)
Let’s quickly do that:
dummy_regressor.predict(X_test.reshape(-1,1))
OUT:
array([5.5831811, 5.5831811, 5.5831811, 5.5831811, 5.5831811, 5.5831811,
5.5831811, 5.5831811, 5.5831811, 5.5831811, 5.5831811])
Here, the model predicts the value 5.5831811 for any input, which may seem strange. That’s because we’re using the DummyRegressor model, for which the prediction is the average of the training y values (the mean of y_train).
Again: this might seem strange, but it’s useful to use as a baseline, against which you can judge the performance of other machine learning models.
And in this case, it’s simply a simple example that we can use when trying to learn how to fit a model with sklearn fit.
Leave your other questions in the comments below
Do you have other questions about the sklearn fit method?
Is there something that I’ve missed?
If so, leave your questions in the comments section near the bottom of the page.
For more machine learning tutorials, sign up for our email list
In this tutorial, I’ve shown you how to use the sklearn fit method.
But if you want to master machine learning in Python, there’s a lot more to learn.
That said, if you want to master scikit learn and machine learning in Python, then sign up for our email list.
When you sign up, you’ll get free tutorials on:
- Scikit learn
- Machine learning
- Deep learning
- … as well as tutorials about Numpy, Pandas, Seaborn, and more
We publish tutorials for FREE every week, and when you sign up for our email list, they’ll be delivered directly to your inbox.
Very good tutorial. Could you please write tutorial on web traffic datasets preprocessing?. Thank you.
Where are you getting the dataset?
It’s impossible for me to create a tutorial if you only give me vague details of what you’re looking for.
good explanation, awesome how everything is abstracted nowadays
????????????
why do we do 2D for training data and how does it work?
I’m really not sure what you’re asking here …