An important principle in analyzing data is “overview first, zoom and filter, then details on demand” (quote: Ben Shneiderman)
In practice, this typically means starting at a high level with a single chart, and then “zooming into” the data by replicating that chart for specific subsets of the dataset.
And, even more valuable is being able to compare these multiple subsetted charts against each other.
This is where the “small multiple” design comes into play. (This is also known as the “trellis chart,” “lattice chart”).
Small Multiples: Comparing data across groups
As Hadley Wickham points out in his book ggplot2, the small multiples technique facilitates comparison by creating the same chart for multiple subsets of your data.
Tufte as well notes in Envisioning Information:
At the heart of quantitative reasoning is a single question: Compared to what? Small multiple designs, multivariate and data bountiful, answer directly by visually enforcing comparisons of changes, of the differences among objects, of the scope of alternatives. For a wide range of problems in data presentation, small multiples are the best design solution.”
The small multiples technique is a powerful data visualization method for comparing across groups or comparing over time.
In my mind, this is a vastly under-used technique, if for no other reason than the small multiples design is difficult to implement with most tools like Excel, SAS, and even Tableau.
In contrast, R’s GGPlot2 package makes small multiples extraordinarily easy to create.
Small Multiples in R (i.e., Faceting)
In R’s
To illustrate the faceting technique in R, let’s imagine the following scenario:
You have 12 months of sales data for 3 separate sales regions and you want to do some data exploration.
You could start out by creating a line chart:
library(ggplot2)
df.facet_data <- read.csv(url("https://www.sharpsightlabs.com/wp-content/uploads/2014/12/facet_dummy_data.csv"))
df.facet_data$month <- factor(df.facet_data$month, levels=month.abb)
ggplot(data=df.facet_data, aes(x=df.facet_data$month,y=sales, group=region)) +
geom_line()
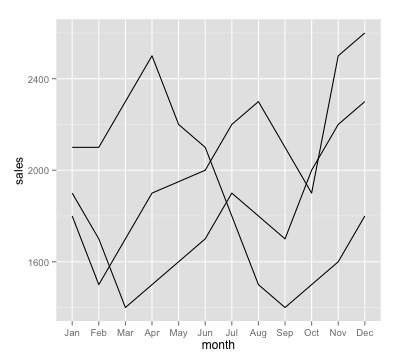
This is ugly.
The chart only has 3 lines on it, yet it's difficult to read. Granted, we could add color to differentiate the lines, but I'm not a big fan of that solution; line charts get uglier the more lines you add (for a good example, see the line chart that Phil Simon criticized in a recent blog post).
A better solution is to create small multiples.
To demonstrate, we'll look at
facet_grid()
Let's take a look at the code:
ggplot(data=df.facet_data, aes(x=month,y=sales, group=1)) + geom_line() + facet_grid(region ~ .)
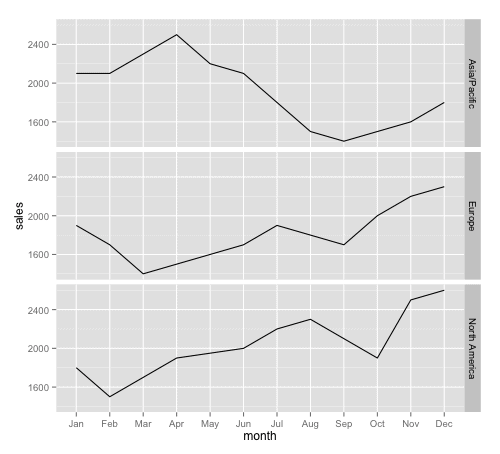
Here, we're specifying that we want to make a line chart. Notice that the code is exactly the same as the code to create a basic line chart, but with the addition of one new line of code:
Inside of the
So we can read the line of code
- create a small multiples chart
- with 1 small multiple chart for each region
- and lay out one small multiple chart on a separate row.
facet_wrap()
Ggplot also allows you to wrap your small multiples charts using
What
Here's a quick example of
ggplot(data=df.facet_data, aes(x=region,y=sales)) +
geom_bar(stat="identity") +
facet_wrap(~month) +
ggtitle("Small Multiples in R") +
theme(plot.title = element_text(family="Trebuchet MS", face="bold", size=20, hjust=0, color="#555555")) +
theme(axis.text.x = element_text(angle=90))
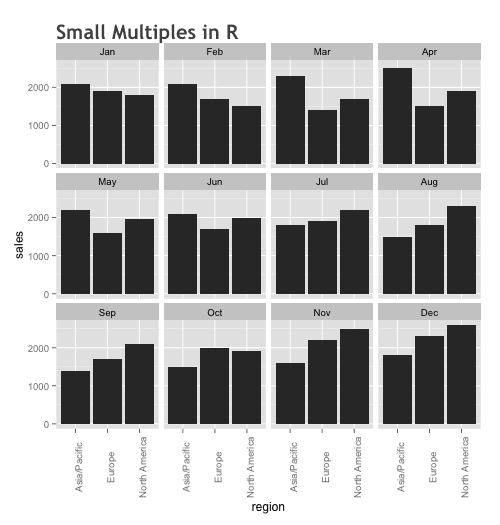
Notice what's happening here.
The first few lines of code are essentially the same as the code for a simple bar chart:
ggplot(data=df.facet_data, aes(x=region,y=sales)) + geom_bar(stat="identity")
The main difference is we've added
We can also choose the number of columns in our layout using the
For example, we could modify our layout to have 6 charts per row (
ggplot(data=df.facet_data, aes(x=region,y=sales)) + geom_bar(stat="identity") + facet_wrap(~month, ncol=6) + theme(axis.text.x = element_text(angle=90))
(note: again, we've also flipped the axis labels 90 degrees, for readability)
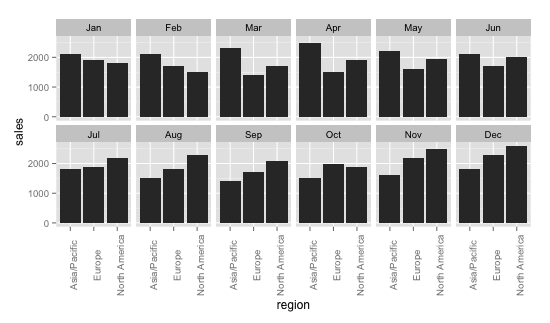
The above examples will allow you to create basic small multiples charts, but the full options in
Why the small multiples technique is important (and how to use it)
If you're learning data science, you really need to learn the small multiples technique.
A large part of your job will involve data exploration. Whether your end goal is a report consisting exclusively of data visualizations, or a model (i.e., a machine learning algorithm) you'll need to explore your data visually.
As the datasets you work with get larger and more complicated, you'll be working with more variables. You'll need tools to explore these datasets: datasets with large numbers of variables and thousands of rows (possibly millions or tens of millions of rows).
Said differently, exploring big data requires a powerful toolset.
And when you're exploring big datasets visually, the small multiples design is an excellent tool in your toolbox.
As seen above, two uses for the small multiples design are for time series analysis (compairing across time) and also comparing across categories.
Time series analysis
As seen in our
In that particular example, we were comparing across months.
However, if your dataset has variables for 'year,' 'month,' or 'day,' you can also facet your data on those time variables to see how your data changes over time.
One example of this is the analysis of Philadelphia crime data. In that analysis, we faceted our geospatial visualization by year, allowing us to see subtle changes in crime patterns over a set of years.
Categorical comparisons
Also seen above in the
Here's another example using the 'diamonds' dataset that comes with the
library(ggplot2) ggplot(data=diamonds, aes(x=price)) + geom_histogram() + facet_wrap(~cut)
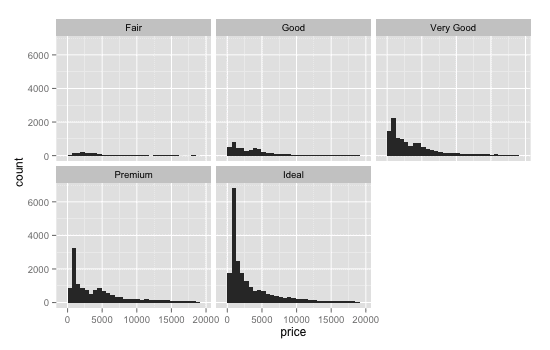
Here we're using the code for a simple histogram and then faceting on the 'cut' variable.
Histograms allow us to examine the distribution of our data. By then faceting on 'cut' we can look at the relative price distributions for different cuts of diamonds.
Similarly, when you have some metric you want to examine for different values of a categorical variable, the small multiples design will be very useful.
Multivariate Visual Analysis
Ultimately, what we're doing is multivariate visual analysis.
This is what makes faceting (aka, trellising, small multiples) so powerful. You can use facets to add another dimension to your analysis. For example, you can build a scatterplot, mapping two variables to the x-axis and y-axis respectively, then possibly map more variables to the size and color of your points to create a "bubble chart." This, in and of itself would be a multivariate visual analysis.
But, using facets, you can extend that even further by breaking out the data into separate facets.
Said differently, when you use the small multiples design in concert with sophisticated charts that already visualize multiple variables, you have a powerful tool for multivariate visual analysis.
Small Multiples Examples
Here are some excellent examples of small multiples in practice:
Juice Analytics
Flowing Data
They show just how powerful the technique can be when applied to geospatial visualizations, area charts, and well-designed versions of bars, lines, and scatters.