If you want to be a data scientist, you need to master core data manipulation tools.
One particular skill you’ll need to master is string manipulation. You need to be able to work with strings (i.e. character data) in order to clean, modify, or reshape them.
In this blog post, you’ll learn one specific string manipulation skill: how to create a substring in R.
Creating substrings in R is fairly straight forward, but you need to know a few details about how R represents strings. You also need to know a little about the particular syntax to create a substring using the stringr package or similar tool.
Here, I’ll quickly review how strings work in R, and how to use the str_sub() function from stringr.
Also, at the end of the post, I’ll show you another way to create a substring in R using one of the older functions from R, substr().
A quick introduction to ‘strings’ in R
Before I discuss substrings, let’s quickly review strings in R.
“Strings” are just character data
First things first… what the hell is a string?
Technically speaking, R strings are sequences of character data.
To be clear, “string” is a bit of a colloquial term in the R programming language. Properly speaking, in R, “strings” are data of the “character” data type. Having said that, even though the term “string” is a colloquial term, we’ll use the term “string” interchangeably with “character data.”
The structure of a string in R
As I mentioned, strings are structured as sequences of characters (i.e., data of the character data type).
Let’s take a look at an example. An example will clarify how strings are structured.
dummy_string <- 'fluent in R'
dummy_string consists of a sequence of characters. A "string" of character data.
Importantly, each character in a string has an associated index value. That is, each character has an associated number that allows us to reference the character by position.
To clarify what that means, here's a representation of dummy_string with the associated index values for each character:
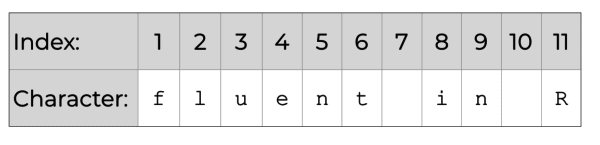
The structure of a string is important because when we create substrings, we will need to reference the index values of the individual characters.
To show you how this works, let's take a look at some examples.
Example: a simple substring using str_sub()
Let's take a look at an example of how to create a substring in R.
To create our substrings, we're going to use the str_sub() function from the stringr package.
Therefore, the first thing we'll need to do is load the stringr package itself.
library(stringr)
Now, let's print the contents of dummy_string, the string variable that we created previously in this post.
print(dummy_string) [1]"fluent in R"
When we print out the contents of dummy_string, you can see that it contains the string of characters "fluent in R".
Remember, each character in the string has an associated index value.
To create a substring, we need to reference the index values for the associated characters.
So let's say you want to extract the word "fluent" from dummy_string. The substring "fluent" is the subset of characters from index value 1 to index value 6.
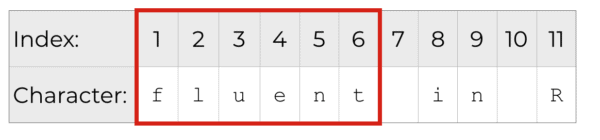
We'll use the str_sub() function to extract this substring.
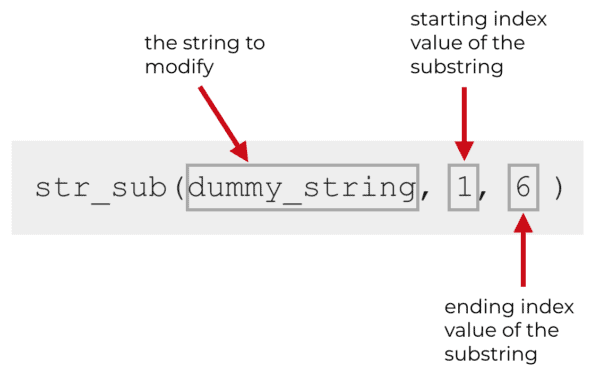
# RETRIEVE 'fluent' FROM STRING str_sub(dummy_string, 1, 6)
Notice how str_sub() works. We call the function, and the first argument is the string or the variable that we want to act upon. In this case, we've used the variable "dummy_string" (which contains the string we want to work with).
The second and third arguments are the index values of the characters we want to extract.
So when we use str_sub(), we simply provide those index values. The substring we want starts at index value 1 and ends at index value 6. The syntax reflects this:
Notice as well that when we use the index values, they are "inclusive." The substring will include the characters at both the start and the end index positions.
You can use string literals as well as variables
In the previous example, we extracted a substring from the variable dummy_string.
But, we could also use a literal string as well:
str_sub("fluent in R", 1, 6)
These two essentially work the same. The only difference is that the first version uses a variable name to reference the string whereas this second version works with a string literal.
Obviously, using variables has advantages when you're creating more complex scripts.
Example: a substring from the middle of the string
Let's take a look at another example.
Here, we'll retrieve a substring from the middle of the string. We'll retrieve the word "in" from dummy_string.
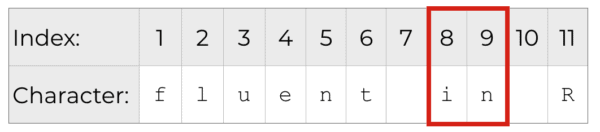
Doing this will be easy enough. Just like the prior example, we just need to reference the index positions of the start and end characters of the substring. In this case, we'll extract the substring from position 8 to position 9.
Here's the syntax:
# RETRIEVE 'in' FROM STRING str_sub(dummy_string, 8, 9)
This is almost exactly the same as the prior examples ... we're just using different index positions.
Having said that, once you know how str_sub() works, it's very easy to use.
Example: a substring from the end of the string
Even though str_sub() is easy to use, there are a few other things you can do that you might not expect.
In particular, there's actually a special hack to extract a substring from the end of the string.
Let's say we wanted to extract the very last character from dummy_string.
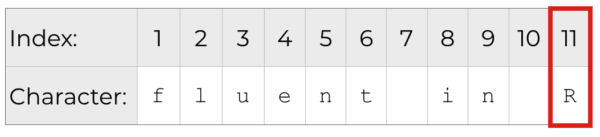
One way to do that would be to reference the exact start and end position of the substring, which in this case would both be '11.'
str_sub(dummy_string, 11, 11)
The problem with this is that sometimes you don't know the exact index of the end of the string. In other cases, you might be working with several strings of different lengths, and you want to take the last few characters from each of them. It's a pain in the ass to manually code different indexes for strings of different lengths when you just want to take the last X characters from the end of each one.
Thankfully, there's a solution to this.
Retrieving a substring using negative indexes
To take a substring from the end of a string, you can use negative index values.
So if we want to retrieve the last character from the string, we can use the index value -1.
# RETRIEVE LAST CHARACTER FROM STRING str_sub(dummy_string, -1, -1)
This retrieves exactly the string that we wanted:
Notice that because we're extracting a single character, the start index and end index are the same in this case.
There are other ways to create a substring in R
The last few examples should give you a strong foundation in how to create substrings using str_sub() from the stringr package.
At this point though, I want to point out that there are other ways to create substrings in R.
Let's quickly talk about one of them (and then I'll tell you why I still prefer to use stringr).
The substr() function
In many ways, the substr() function works like the str_sub() function.
For example, you can extract the substring "fluent" from dummy_string in a way that's almost exactly the same as how we did it with str_sub():
substr(dummy_string, 1, 6)
This will produce the substring "fluent."
However, if you want to take a substring from the end of the string like we did with str_sub(), it does not work.
substr(dummy_string, -1, -1)
Try it. This simply produces an empty string of length zero.
There are ways to get around this and use substr() to produce a correct result but they are a little convoluted and would be challenging for a beginner to understand.
Because of this, I strongly recommend that you skip the older ways to create a substring in R (like the substr() function) and just stick with str_sub().
Why you should learn stringr and the Tidyverse
This brings me to a broader point about data manipulation and data science in R.
For any given data science task – like creating substrings, visualizing data, etc – there is almost always more than one way to do it in R.
This is because R is a very old language and it's open source. Early versions of base R and early add-on packages provided tools to accomplish data science tasks, but many of those tools are imperfect in a lot of ways. Just like the substr() function fails when you try to take a substring from the end of a string, many older tools for performing data science tasks have some peculiarities and unexpected failure points.
Because of this, I strongly recommend that you learn the Tidyverse.
Learn the stringr package for string manipulation.
Learn dplyr for subsetting, filtering, and otherwise modifying your data.
Learn ggplot2 for data visualization.
These packages (and the other packages from the "Tidyverse" collection of R packages) are well designed and easy to use once you get the hang of them.
There's a bit of a learning curve (just like with all packages and programming languages) but using these tools will save you time and frustration in the end.
Sign up for our email list to learn more about stringr and the Tidyverse
Do you want to learn more about stringr?
Do you want to master the other packages of the Tidyverse, like ggplot2, dplyr, and tidyr?
Do you want to learn more about data science in R?
If you do, sign up now for our email list.
Here at Sharp Sight, we post free tutorials about data science in R using tools like stringr, dplyr, and ggplot2.
When you sign up, you'll be notified when we publish new blog posts.
You'll also be notified when we open our exclusive training course for data science in R. Only people on our mailing list are notified, so if you want to receive your exclusive invitation when it opens, sign up for the email list now.