In this tutorial, I’ll show you how to use the Pandas get dummies function to create dummy variables in Python.
I’ll explain what the function does, explain the syntax of pd.get_dummies, and show you step-by-step examples.
If you need something specific, just click on any of the following links.
Table of Contents:
Ok. Before we look at the syntax and examples, let’s look at a quick overview of what the function does.
A Quick Introduction to Pandas Get Dummies
The Pandas getdummies function creates dummy variables from Pandas objects in Python.
To understand this, let’s quickly review the basics of “dummy encoding.”
Dummy Variables Encode Categorical Information
So what exactly are dummy variables?
A dummy variable is a numeric variable that encodes categorical information.
Dummy variables have two possible values: 0 or 1.
In a dummy variable:
- A 1 encodes the presence of a category
- A 0 encodes the absence of a category
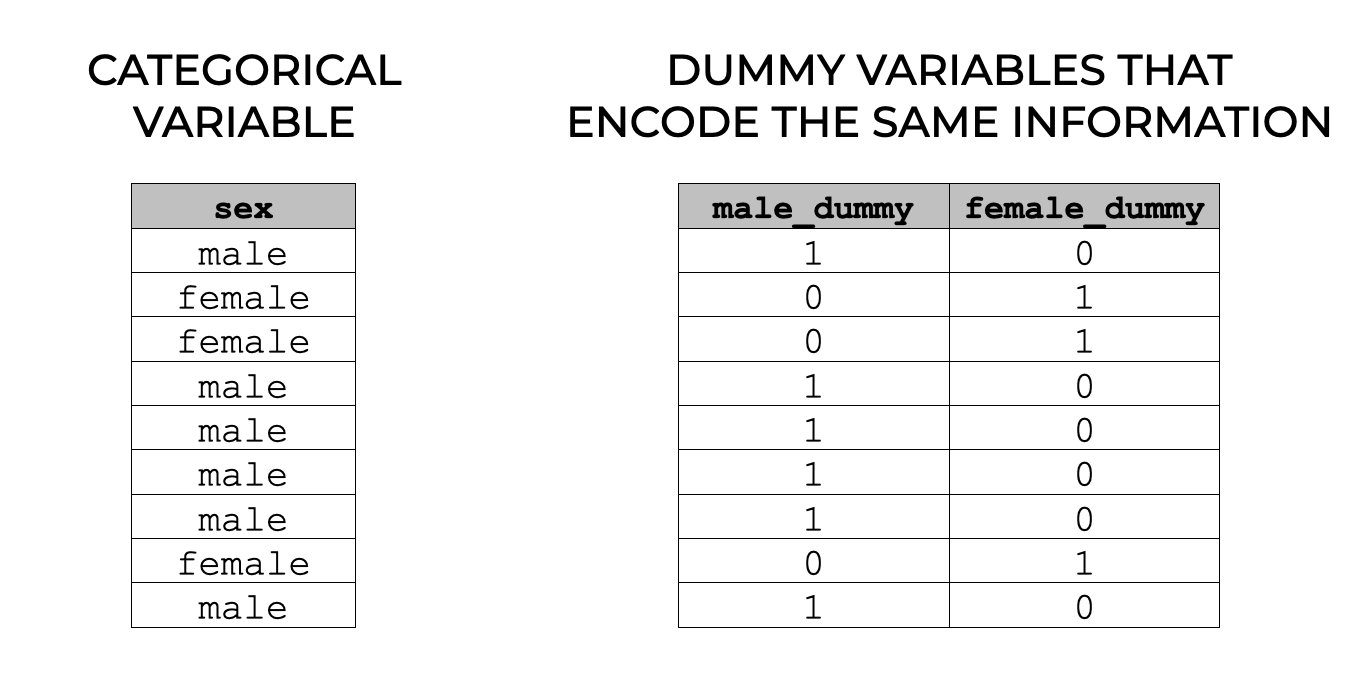
We frequently call these 0/1 variables “dummy” variables, but they are also sometimes called indicator variables. In machine learning, this is also sometimes referred to as “one-hot” encoding of categorical data.
Pandas Get Dummies Creates Dummy Variables from Categorical Data
Now that you understand what dummy variables are, let’s talk about the Pandas get_dummies function.
As you might guess, pd.get_dummies creates dummy variables.

Importantly, the pd.get_dummies can create dummy variables from a Pandas Series, or from a column or columns in a Pandas dataframe.
We’ll look at both of these in the examples section.
Dummy variables are important for Machine Learning
Before we look at the syntax of pd.get_dummies, I want to make a comment about why we need dummy variables.
Some data science tools will only work when the input data are numeric. This particularly true of machine learning. Many machine learning algorithms – like linear regression and logistic regression – strictly require numeric input data. If you try to use them with string-based categorical data, they will throw an error.
So before you use such tools, you need to encode your categorical data as numeric dummy variables.
To be honest, this is one of the data-cleaning steps that often frustrates data scientists and machine learning engineers.
But the good news is that the Pandas get dummies function makes it relatively easy to do.
Let’s take a look at the function.
The Syntax of Pandas Get Dummies
Here, we’ll look at the syntax of the Pandas get_dummies() function.
A quick reminder
Before we look at the syntax, I want to remind you this syntax explanation assumes that you’ve already imported Pandas.
You can import Pandas like this:
import pandas as pd
It also assumes that you have a Pandas Series or dataframe that you can use.
(We’ll actually create a dataframe and a Series in the examples section.)
Syntax of pd.get_dummies
The syntax of Pandas get dummies is very simple.
You call the function as pd.get_dummies().
Inside the parenthesis, the first argument is the object that you want to operate on. This will be either a Pandas dataframe or a Pandas Series.

There are also some optional parameters that you can use to change how the function works.
Let’s take a closer look at them.
The parameters of pd.get_dummies
The Pandas get dummies function has
data_objectcolumnsprefixprefix_sepdrop_firstdummy_nasparsedtype
Let’s take a look at those.
dtype (required)
The “data_object” parameter enables you to specify a data object that you want to operate on.
This can be a Pandas dataframe, a Pandas Series, or a list-like object (i.e., a list, etc).
Importantly, you use this parameter by position only. Pandas assumes that the first argument you pass to the function should correspond to this parameter.
columns
The columns parameter specifies the columns that you want to transform to dummy variables.
This column will only apply if you’re operating on a dataframe that has multiple columns.
prefix
The prefix parameter enables you to specify the prefix for the names of the new dummy variables.
By default, the prefix is the name of the variable(s) you’re transforming.
So if you’re operating on a variable named “sex“, the new dummy variables will start with the prefix “sex“.
You’ll see examples of this in the examples section.
prefix_sep
The prefix_sep parameter enables you to specify the separator between the prefix and the dummy category, in the name of the dummy variables.
By default, the separator is “_”.
So if you are encoding a dummy variable called sex, with the categories male and female, then by default, the output dummy variabels will be named sex_male and sex_female. (Notice the underscore character in these variable names.)
drop_first
The drop_first parameter specifies whether or not you want to drop the first category of the categorical variable you’re encoding.
By default, this is set to drop_first = False. This will cause get_dummies to create one dummy variable for every level of the input categorical variable.
If you set drop_first = True, then it will drop the first category. So if you have K categories, it will only produce K – 1 dummy variables.
dummy_na
The dummy_na parameter enables you to specify if get_dummies will create a separate dummy variable that encodes missing values.
By default, this parameter is set to dummy_na = False. In this case, get_dummies will not create a dummy variable for NA values.
If dummy_na = True, get_dummies will create a separate variable that contains a 1 if the input value is missing, and 0 otherwise.
This can be useful if your data has missing values, and you think that the missing value is informative in some way.
sparse
The sparse parameter specifies if the new dummy variables are backed by a SparceArray.
(This is somewhat rarely used.)
dtype
The dtype parameter specifies the data type of the new dummy variables.
By default, the datatype of the new dummy variables is np.uint8.
The output of pd.get_dummies
As an output, the Pandas get dummies function will return a dataframe that contains the new dummy variables.
Examples: How to Create Dummy Variables in Python using Pandas
Now that you’ve looked at the syntax for the Pandas get dummies function, let’s look at some examples of how to create dummy variables in Python.
Examples:
- Use Get dummies on a Series
- Use Get dummies on a Dataframe column
- Use Get dummies on a Dataframe column, and drop the first category
- Use Get dummies on a Dataframe column, and specify a prefix for the dummy variables
- Use Get dummies on a Dataframe column, and include NA values
Run this code first
Before you run the examples, you’ll need to run some preliminary code to:
- import necessary packages
- get the example dataframe
Let’s do each of those.
Import packages
First, let’s import Pandas and Numpy:
import pandas as pd import numpy as np
Obviously we’ll need Pandas to use the pd.get_dummies function.
But we’ll use Numpy when we create our data, in order to include NA values.
Create example dataframe
Next, we need to create a dataset that we can work with.
Here, we’re going to create some mock “sales data” using the pd.DataFrame function, with a dictionary of values that will become the columns.
sales_data = pd.DataFrame({"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"region":["East","North","East","South","West","West","South","West","West","East",np.nan]
}
)
Let’s print out the data to see the contents:
print(sales_data)
OUT:
name sales region
0 William 50000 East
1 Emma 52000 North
2 Sofia 90000 East
3 Markus 34000 South
4 Edward 42000 West
5 Thomas 72000 West
6 Ethan 49000 South
7 Olivia 55000 West
8 Arun 67000 West
9 Anika 65000 East
10 Paulo 67000 NaN
The region variable is a categorical variable that we’ll be able to transform into 0/1 dummy variables.
Also, notice that one of the values of region is np.nan (i.e., a missing value). This will be important in example 5.
Create Series
We’ll also create a Pandas Series called region.
region = sales_data.region
This variable contains the region categories that we created in our dataframe.
Now that we have some data, let’s work through some examples.
EXAMPLE 1: Use Getdummies on a Series
First, let’s just use the get dummies function on a Pandas Series.
We’ll use the function on the region Series that we created a little earlier.
Print data
First, let’s just print out the data, so we can see what’s in the Series.
print(region)
OUT:
0 East 1 North 2 East 3 South 4 West 5 West 6 South 7 West 8 West 9 East 10 NaN Name: region, dtype: object
As you can see, region contains string data organized into 4 categories (North, South, East, and West). There is also a missing value at the end of the series.
Use pd.get_dummies
Now, we’ll use the Pandas get_dummies function.
pd.get_dummies(region)
OUT:
East North South West
0 1 0 0 0
1 0 1 0 0
2 1 0 0 0
3 0 0 1 0
4 0 0 0 1
5 0 0 0 1
6 0 0 1 0
7 0 0 0 1
8 0 0 0 1
9 1 0 0 0
10 0 0 0 0
(Note: this output is actually a dataframe.)
Explanation
Notice what happened here.
The output of pd.get_dummies is a group of 4 new variables:
EastNorthSouthWest
There’s one new variable for every level of the original categorical variable.
Where the value was ‘East‘ in the original Series, the new East variable has a value of 1 (and the values for the other variables are 0).
Where the value was ‘North‘ in the original Series, the new North variable has a value of 1 (and the values for the other variables are 0).
And so on.
So the get_dummies function has recoded a single variable with 4 values, into 4 variables with 0 or 1 values. The new structure effectively contains the same information, but it’s represented in a different way.
EXAMPLE 2: Use Getdummies on a Dataframe column
Next, we’ll use pd.get_dummies on a column inside a dataframe.
Specifically, we’ll use Pandas get_dummies on the region variable inside the sales_data dataframe:
pd.get_dummies(sales_data, columns = ['region'])
OUT:
name sales region_East region_North region_South region_West
0 William 50000 1 0 0 0
1 Emma 52000 0 1 0 0
2 Sofia 90000 1 0 0 0
3 Markus 34000 0 0 1 0
4 Edward 42000 0 0 0 1
5 Thomas 72000 0 0 0 1
6 Ethan 49000 0 0 1 0
7 Olivia 55000 0 0 0 1
8 Arun 67000 0 0 0 1
9 Anika 65000 1 0 0 0
10 Paulo 67000 0 0 0 0
Explanation
First of all, note that the output of the operation is a new dataframe.
In this new dataframe, the old region variable is gone.
It has been replaced with 4 new variables:
region_Eastregion_Northregion_Southregion_West
By default, get_dummies used the name of the old variable (region) as a prefix to the new variable names.
Also notice how the new variables are coded.
- Where the value was ‘
East‘ in the original Series, the newregion_Eastvariable has a value of 1 (and the values for the other variables are 0) - Where the value was ‘
North‘ in the original Series, the newregion_Northvariable has a value of 1 (and the values for the other variables are 0) - Where the value was ‘
South‘ in the original Series, the newregion_Southvariable has a value of 1 (and the values for the other variables are 0) - Where the value was ‘
West‘ in the original Series, the newregion_Westvariable has a value of 1 (and the values for the other variables are 0)
So Pandas get_dummies has created a new 0/1 variable for every level of the original categorical variable.
This is very similar to example 1, but instead of performing this operation on an independent Pandas Series, we’ve performed the operation on a column that exists inside of a dataframe.
(Note that the output of this operation is a new dataframe.)
EXAMPLE 3: Use Getdummies on a Dataframe column, and drop the first category
Now, we’re going to use get_dummies, but we’ll use the drop_first parameter to drop the first level of the categorical variable that we’re operating on.
To do this, we’ll set drop_first = True.
pd.get_dummies(sales_data
,columns = ['region']
,drop_first = True
)
OUT:
name sales region_North region_South region_West
0 William 50000 0 0 0
1 Emma 52000 1 0 0
2 Sofia 90000 0 0 0
3 Markus 34000 0 1 0
4 Edward 42000 0 0 1
5 Thomas 72000 0 0 1
6 Ethan 49000 0 1 0
7 Olivia 55000 0 0 1
8 Arun 67000 0 0 1
9 Anika 65000 0 0 0
10 Paulo 67000 0 0 0
Explanation
Notice that the output only has 3 dummy variables now:
- region_North
- region_South
- region_West
The dummy variable for the ‘East‘ category is gone.
Why?
Setting drop_first = True causes get_dummies to exclude the dummy variable for the first category of the variable you’re operating on.
But why would we do it?
When you have a categorical variable with K mutually exclusive categories, you actually only need K – 1 new dummy variables to encode the same information.
This is because if all of the existing dummy variables equal 0, then we know that the value should be 1 for the remaining dummy variable.
So for example, if region_North == 0, and region_South == 0, and region_West == 0, then region_East must equal 1. This is implied by the existing 3 dummy variables, so we don’t need the 4th. The extra dummy variable literally contains redundant information.
So, it’s a common convention to drop the dummy variable for the first level of the categorical variable that you’re encoding.
(In fact, it’s frequently needed for some types of machine learning models. If you fail to drop the extra dummy variable, it can cause issues with your model.)
EXAMPLE 4: Use Getdummies on a Dataframe column, and specify a prefix for the dummy variables
Now, we’ll create dummy variables with a specific prefix.
Remember: by default, it uses the variable name as the prefix for the new dummy variables.
But here, we’ll set prefix = 'sales_region' to use a different prefix.
pd.get_dummies(sales_data
,columns = ['region']
,prefix = 'sales_region'
)
OUT:
name sales sales_region_East sales_region_North sales_region_South sales_region_West
0 William 50000 1 0 0 0
1 Emma 52000 0 1 0 0
2 Sofia 90000 1 0 0 0
3 Markus 34000 0 0 1 0
4 Edward 42000 0 0 0 1
5 Thomas 72000 0 0 0 1
6 Ethan 49000 0 0 1 0
7 Olivia 55000 0 0 0 1
8 Arun 67000 0 0 0 1
9 Anika 65000 1 0 0 0
10 Paulo 67000 0 0 0 0
Explanation
Notice that now, the prefix for all of the dummy variables is sales_region (instead of just region).
This is because we manually set the prefix with the prefix parameter.
Keep in mind, the prefix can be more complicated: you can provide a dictionary of prefix values that correspond to the new dummy variables. But, 98% of the time, you’ll just want to set a single prefix like we did here.
EXAMPLE 5: Use Getdummies on a Dataframe column, and include NA values
Finally, let’s look at how to create a dummy variable for the missing values.
You’ll notice that in our dataframe, sales_data, the region value is NaN for one of the rows (the row for Paulo). This is a missing value.
You’ll also notice that in the previous examples, for this row of data, the values for all of the newly created dummy variables was 0.
Here, we’re going to create one additional dummy variable that encodes a 1 for missing values.
To do this, we’ll set dummy_na = True.
pd.get_dummies(sales_data
,columns = ['region']
,dummy_na = True
)
OUT:
name sales region_East ... region_South region_West region_nan
0 William 50000 1 ... 0 0 0
1 Emma 52000 0 ... 0 0 0
2 Sofia 90000 1 ... 0 0 0
3 Markus 34000 0 ... 1 0 0
4 Edward 42000 0 ... 0 1 0
5 Thomas 72000 0 ... 0 1 0
6 Ethan 49000 0 ... 1 0 0
7 Olivia 55000 0 ... 0 1 0
8 Arun 67000 0 ... 0 1 0
9 Anika 65000 1 ... 0 0 0
10 Paulo 67000 0 ... 0 0 1
Explanation
You can see that in the output, in addition to creating the dummy variables for each category, get_dummies has also created a variable called region_nan.
This value only has a 1 where the value of the variable we operated on had a missing value (NaN). For all other values, region_nan has a 0.
This is useful when you have data that has missing values, and you want to encode that information about missing values in your new dummy variables.
Sometimes, this is useful. In machine learning, we sometimes call this “informative missingness.”
Frequently asked questions about Pandas Getdummies
Now that we’ve looked at some examples, let’s look at some common questions about the get_dummies() technique.
Frequently asked questions:
Question 1: I used get_dummies, but my data is unchanged. Why?
If you use the get_dummies function, you might notice that your original data remains unchanged after you call the function.
For example, in example 1, we used the following code:
pd.get_dummies(sales_data, columns = ['region'])
But if you check sales_data after you run the code, you’ll realize that the it still contains the original variables (and the dummy variables are not there.
That’s because when we run the get_dummies() function, it outputs a new object, and leaves the original object unchanged.
This is how most Pandas methods work.
By default, the output is sent to the console. We can see the output in the console, but to save it, we need to store it with a name.
For example, you could store the output like this:
sales_data_updated = pd.get_dummies(sales_data, columns = ['region'])
You can name the new output whatever you want. You could even name it with the original name sales_data.
But be careful. If you reassign the output of get_dummies to the dataset name, it will overwrite your original dataset. Make sure that you check your code so it works properly before you do this.
Leave your other questions in the comments below
Do you have any other questions about the Pandas get_dummies method?
Is there something else that you need to know that I haven’t covered here?
If so, leave your question in the comments section below.
Discover how to become ‘fluent’ in Pandas
This tutorial showed you how to use the Pandas get_dummies method, but if you want to master data wrangling with Pandas, there’s a lot more to learn.
So if you want to master data wrangling in Python, and become ‘fluent’ in Pandas, then you should join our course, Pandas Mastery.
Pandas Mastery is our online course that will teach you these critical data manipulation tools, show you how to memorize the syntax, and show you how to put it all together.
You can find out more here:
Thank you for this really valuable post. It solved a few problems that I was trying to solve during dataframe shaping.
You’re welcome.
Good to hear that it was helpful.
If you leave out one level of a categorical variable you cannot distinguish between that base level an NA value. In both cases the other dummy variables are 0. Is it right? How to solve it?
If I’m understanding you correctly, you need to handle your missing values *before* you use
get_dummies.Thanks Bruh
YW bruh