Welcome to our deep dive into one of the foundations of machine learning: Training, Validation, and Test Sets.
In this blog post, I’ll explain the purpose of having these different machine learning datasets, explaining their roles, and discuss a few of the main strategies for data splitting.
If you need something specific, just click on any of the following links.
Table of Contents:
- Machine Learning Dataset Basics
- Why we need training, validation and test sets
- What are the Training, Validation, and Test Sets
- Basic Data Splitting Strategies
- Frequently Asked Questions
Having said that, this blog post is intended to be read top to bottom, since many of the concepts build on each other.
With all that said, let’s jump in.
Machine Learning Dataset Basics
In the field of machine learning, the dataset is the bedrock upon which algorithms are built and refined.
A dataset is a collection of data examples that have been collected for the purpose of training a machine learning model and testing that model’s performance.
The examples in a dataset can take various forms – from numerical values in a table to images or text. Although the data in a dataset is almost always derived from observations and measurements of real world phenomena. Examples in a tabular dataset might be sales data from a business, with which we could build a sales forecasting model. Or the examples in a text dataset could be textual data from books, which could be used in a natural language application, like a large language model (LLM).
Most of the examples that I just suggested are examples of supervised learning. In supervised learning, which is one of the most common forms of machine learning, datasets play a pivotal role.
In a supervised learning dataset, every example consists of an input-output pair, where the “input” is the data fed into the model (with the various features), and the output is the desired prediction or classification.
For example, one could imagine a supervised learning model designed to identify cats in images (a model that I’ve previously called “The Cat Detector”). In a dataset used to train and evaluate such a model, the input/output pair would consist of an image (i.e., of a cat) and the label associated with that image (i.e., cat).
But, there’s a bit more detail about how such a dataset is used, because in supervised learning, we need to both “train” the model, but also “evaluate” the model. So there are training and evaluation steps.
There’s also frequently a “validation” step, which is typically performed between training and evaluation.
Each of these steps requires a separate dataset, which leads us to the concept of training, validation, and test sets.
Why we need training, validation and test sets
When we train a model, we typically need multiple data sets.
There are a few reasons for this.
The Problem of Overfitting
First, when we train a model, there’s a problem of overfitting. Overfitting is when an algorithm matches the training set too closely. In the worst case, the algorithm will match the training dataset perfectly.
You might be asking … “Why is that a problem? Don’t we want to the model to match the data perfectly?”
Not exactly.
We want a machine learning model to perform well on previously unseen data.
What can happen is that during the training process, the model can match the data perfectly. Too perfectly. In the worst case, the algorithms “memorizes” all of the training datapoints.
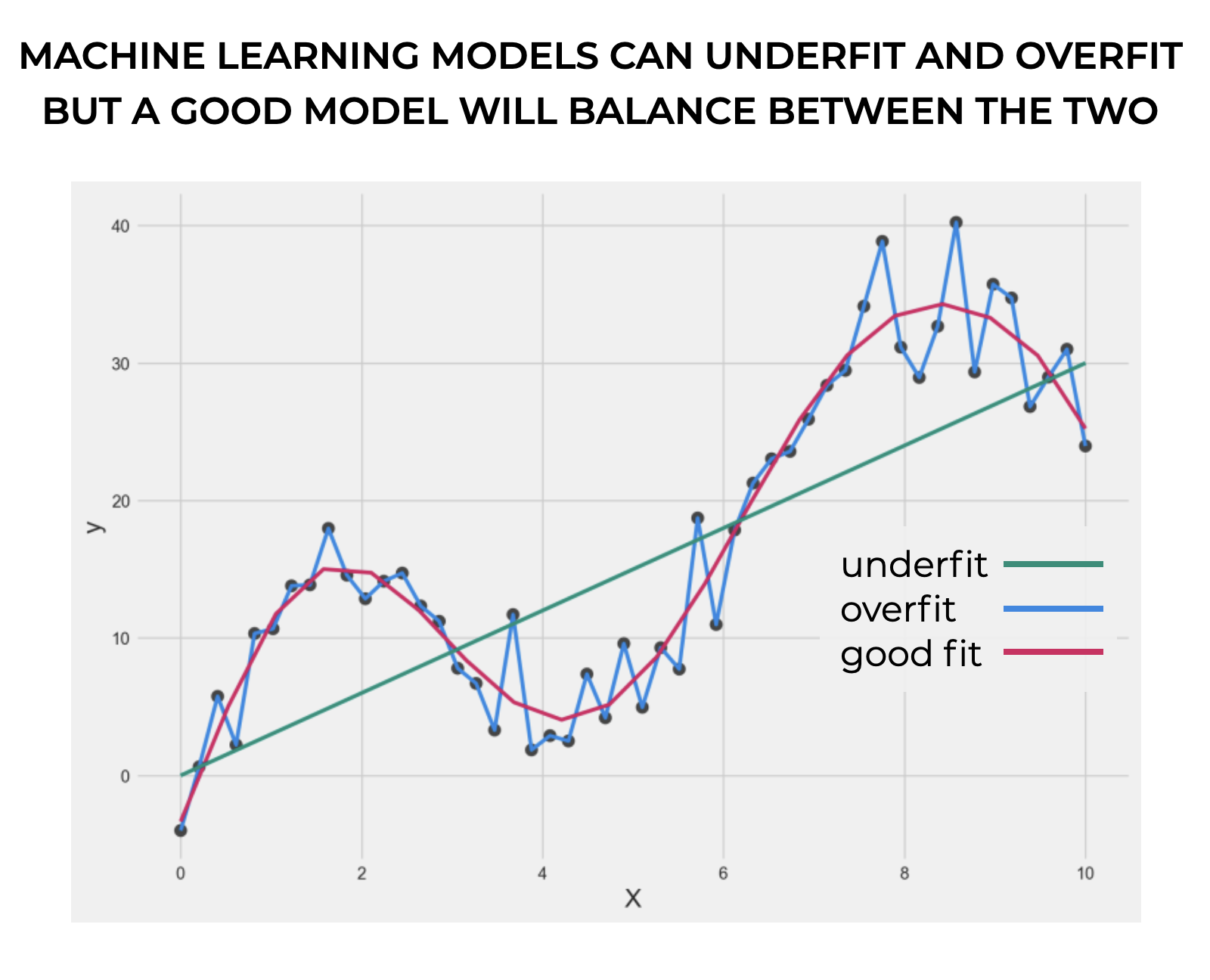
But the problem arrises when we give it new data to work with. If it “memorized” the training data, it may actually underperform on the new, previously unseen data.
(Note that the problem of overfitting is complex, and I’ll address it more completely in a separate blog post on the topic of overfitting.)
The Problem of Parameter Selection
Second, we often need to select the right values for model hyperparameters.
In many algorithms, like boosted trees, random forests, deep neural networks, and many more, there are what we call hyperparameters.
Unlike model parameters, which are learned from the data, hyperparameters are like higher-level setting for the algorithm that specify details of how the algorithm should operate. It’s sort of like a piece of equipment, like a TV. A TV has various settings that specify how it should work, like the volume, brightness, contrast, etcetera. You can modify those settings and they will modify how the TV will work.
Similarly, hyperparameters are model setting that you, as the data scientist, can set. Different hyperparameter settings can affect model performance, the speed of training, and more. Modifying the values for these hyperparameters to find the best settings is called model “tuning.”
Now, let’s bring it back to why this is a problem for machine learning model training.
To put it simply: it’s bad to set the model hyperparameters on the same dataset that you use to train the model.
Why?
Again, it comes back to overfitting.
When you tune hyperparameters only on the training data, you end up optimizing the hyperparameter values for that training dataset. This in turn can make it harder for the model to generalize to new data examples.
So, when we train a model and set the hyperparameters, we begin to run into problems … specifically problems with overfitting.
That’s why, we need to split our data into multiple datasets.
What are the Training, Validation, and Test Sets
To overcome the general problem of overfitting, and the specific problem of overfitting when selecting model hyperparameters, we typically need 2 or 3 datasets.
These typically come from a single dataset that we split into 2 or 3 pieces, the training, validation, and test set.
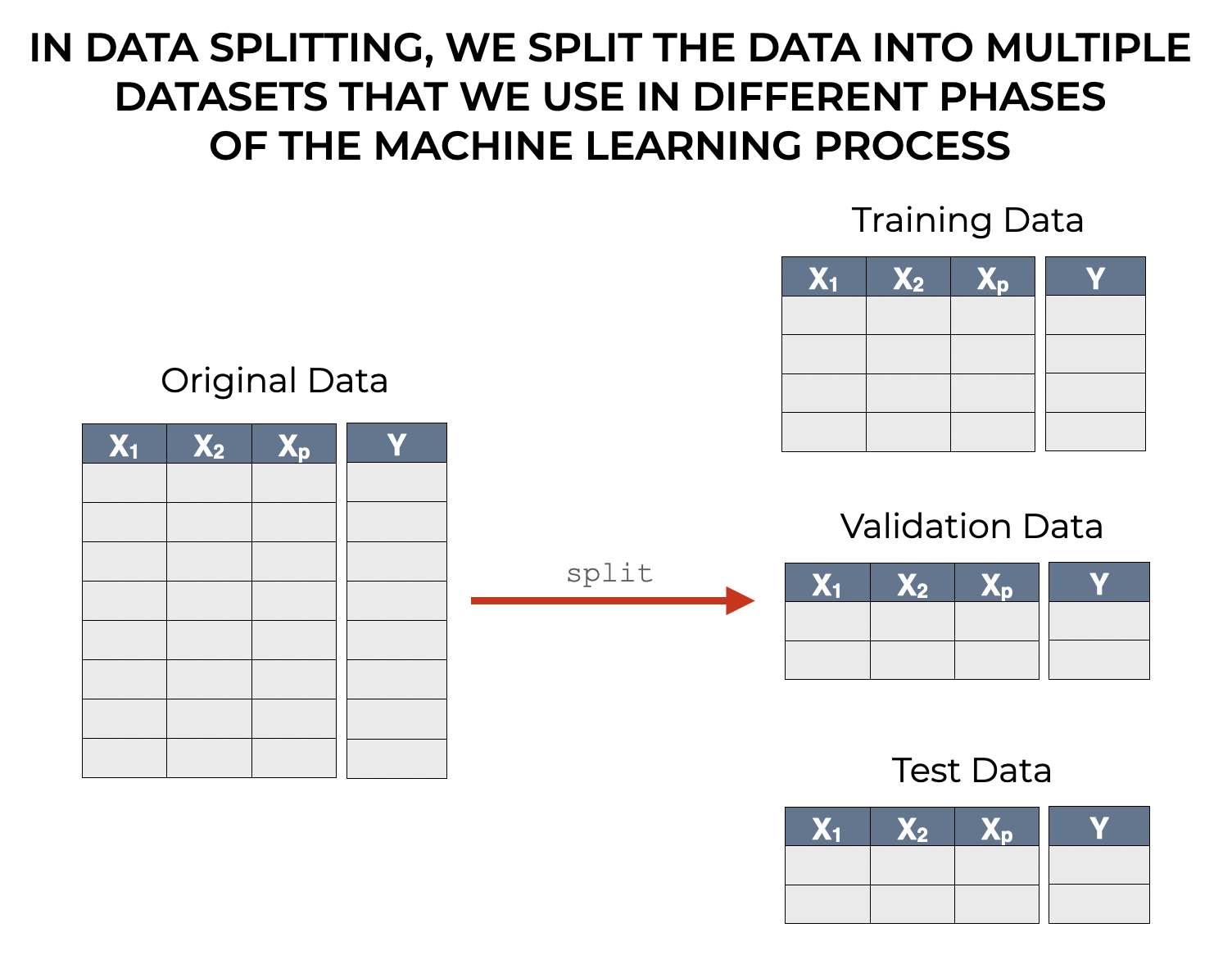
I’ll talk more about data splitting tactics later, but when we generate the training, validation, and test set, we literally take the data that we intend to use to build the model, and we split it into several pieces.
Let’s talk about these 3 datasets, one at a time.
The Training Set
The training set is the primary dataset that we use to train the algorithm so that it can learn the correct parameters (note: the correct parameters … the hyperparameters are different, and are optimized elsewhere).
So, the main purpose of the training set is to provide enough data examples and sufficient information in the individual features that will enable the algorithm to “learn” the relationship between the features and the target.
For example, let’s take a neural network. When we train a neural network with the training set, the algorithm will “learn” the relationship between the features and the target by adjusting the neural network weights (e.g., updating the weights with backpropogation).
So when we train a neural net, we feed the network examples consisting features/target pairs. These examples are used by the algorithm to adjust the model weights, which allows the algorithm to learn how the features are related to the target. This in turn, allows the model to learn to “predict” the target on the basis of the input features.
Having said that, there are many fine-grained details that I’m leaving out here.
Things like the quantity of the training data, and the quality of the feature data (i.e., how the features have been preprocessed, whether or not we’ve done feature engineering or feature extraction to create new features, etc) … these things all strongly influence the level of success of model training.
Because those topics – data cleaning, feature engineering, feature extraction, preprocessing, training set size, etc – are all big topics in and of themselves, I’ll write more about them separately.
What you need to walk away with, at a high level, is that a machine learning algorithm uses the training dataset to learn the patterns in the data, and (in the case of supervised learning) learn the relationship between the features and the target.
The Validation Set
The validation set is another dataset that we use when we train a machine learning model, and the phase where we use the validation set is between when we use the “training” set and the “test” set.
Therefore, we use the validation set after we train the model in the training set.
The primary role of the validation set is to evaluate the performance of a model (and variations of the model) on a new dataset that the algorithms has yet to see. Said differently, we’re trying to see how well the model generalizes to new, previously unseen data.
More specifically though, the validation set typically plays a critical role in model selection and hyperparameter tuning.
Model selection and tuning (AKA, hyperparameter selection) are a complex topics that I will write more about in a future post. However, we can explain these in simple terms.
Model selection is selecting the “best” model among several possible models. In many cases, when we build a model, we actually build multiple different models with different algorithms. We might try decision trees, linear models, support vector machines, and neural networks (although the types of algorithms that we might try depend on the task). In such a case, we will try them all and see which one performs best on the task.
Hyperparameter tuning is related, but slightly different. In hyperparameter tuning, we search for and select the “best” settings for model hyperparameters.
As I mentioned above, hyperparameters are like setting on a machine, like a TV or an amplifier. Imagine an amplifier with knobs for the volume, gain, bass, treble, etc, and the different setting of those knobs will determine the performance of the amplifier (i.e., the quality of the sound).

As data scientists, we can change the values of these hyperparameters, and in turn, these changes can improve or degrade the performance of a model.
Ideally, you want to find the best settings for the hyperparameters.
Additionally, some algorithms have many different hypereparameters. So in practice, you often need to find the best combination of settings for many different hyperparameters.
To do this, you’ll often build multiple versions of a model with different hyperparameter settings. For example, with gradient boosted trees – which have hyperparamters for the number of branch splits, the learning rate, and the number of iterations with which to train the model – you’ll likely try out multiple versions of a gradient boosted tree with different combinations of values for those settings.
Now, as a side note, I’ll mention that doing this can be complicated. Sometimes, if there are multiple hyperparameters that you’re trying to tune, and you use multiple different values for every hyperparameter, you can get an “explosion” of different combinations. This can be very computationally expensive, so there are strategies for doing this while reducing computational load.
But, building multiple model versions with different values for hyperparameters is a critical part of model optimization.
Having said all of that, let’s bring it back to the validation set.
We need the validation set as a new dataset that we can use to evaluate all of those different model versions – both models made with different algorithms AND models build with the same algorithm but different hyperparameter settings.
We use the validation set to evaluate the performance of the different models and try to find the best one (while also avoiding overfitting).
The Test Set
The test set in machine learning allows us to perform a final test. It is the final gatekeeper in the model development process that helps us ensure that a trained and validated model performs well and generalizes on new, unseen data.
The test set is a subset of the original training data that we hold back held back and refrain from using during the training or validation phases. We set it aside until the end, after we’ve trained our models and validated them with the validation set.
Ultimately, the primary purpose of the test set is to simulate how the model will perform in real-world scenarios. It is there to provide an unbiased evaluation of the performance of the final trained, tuned, and selected model.
The unbiased nature of the test set is arguably its most critical aspect. Because the test set consists of data that’s never been seen by the model during training and validation, it serves as an honest benchmark for assessing the model’s ability to generalize.
This unbiased evaluation is crucial because it helps identify if the model has overfitted the training data, which, as I explained earlier, is a situation where the model performs well on data it has seen (the training and validation data), but performs poorly on new data (the test data).
How the Test Data is Different from the Validation Data
At this point, you might be wondering what the difference is between the test data and the validation data, since both of them are used to evaluate model performance.
The most important difference is that we use the test data only once, at the very end of the model development process.
This is in contrast to the validation set, which we use iteratively during model development to tune hyperparameters, evaluate multiple models, and ultimately select the best model.
So while the validation set guides our choices about which algorithm to use and how to set the various hyperparameters, the test set answers the final question: “How well does the model perform on data it has never seen before?”
Thus, the test set ensures that the final performance metrics that we compute actually truly reflect the model’s ability to generalize. This makes the test set critical for final model evaluation.
Basic Data Splitting Strategies
Now that we’ve discussed the different datasets that we use in machine learning model development, let’s briefly talk about some of the practical parts of data splitting.
I’ll talk briefly about data splitting proportions, and then about a few “styles” of splitting your data.
Data Split Proportions
Regarding splitting ratios, there’s not a one-size-fits-all rule.
Having said that, typical ratios include 70/15/15 or 80/10/10 for the training, validation, and test sets, respectively.
The choice of ratio depends on several factors, including the total size of the dataset and the complexity of the problem.
If you have a larger dataset, you’ll probably be able to afford a smaller proportion for training data, because given a larger overall dataset, there will still be enough examples in the training dataset.
On the other hand smaller datasets may require a proportionally larger training set to ensure that the algorithm has enough examples to train on so that the model learns effectively.
Similarly, for simpler models or tasks, you may need less data for validation and testing. Conversely, complex models or problems might require larger validation and testing datasets in order to thoroughly evaluate the performance of the model.
Different Model Splitting Strategies
And finally, let’s talk about a few common splitting strategies.
Splitting your data is typically a little more complicated than just taking your existing data “as is” and splitting the examples into 2 or 3 groups.
Instead, we may need to process the dataset as a whole through randomization or other techniques to guarantee that the different datasets will be appropriate for training, validation and testing generally, and also for our task specifically.
Here, I’ll briefly discuss 3 common strategies:
- Random splitting
- Stratified splitting
- Time-based splitting
Let’s talk about each of those in turn.
Random Splitting
The most common and most straightforward approach to splitting your data is randomized splitting.
In randomized splitting, we randomly assign every example to one of the machine learning datasets (training, validation, test).
To accomplish this technically, we can often just randomize the examples in the original data, and then split by taking a portion of rows, after they’ve been sorted, for each dataset. So if we had 1000 examples, we could sort the examples first, and then put 700 in the training set, 150 in the validation set, and 150 in the test set for a 70/15/15 split.
This data splitting method is simple and often effective, and works best when the dataset is large and broadly representative of the overall population.
But there are cases where purely randomized splitting can be problematic. For example, if you’re doing classification and some of the classes are over-represented or under-represented, a purely random splitting strategy can be insufficient, or lead to a model that generalizes poorly once it’s trained.
Stratified Splitting
In stratified splitting, we split the data such that the proportion of target values (i.e., classes) in the different datasets (training, validation, test), mirrors the proportion of target values in the full dataset.
This is most commonly used in classification. And in particular, this is used in classification tasks where some classes are under or over-represented.
Time-based Splitting
We can use time-based splitting for datasets where there are temporal dynamics in the data.
In this splitting strategy, we’ll ensure that the training data contains earlier data and the test set contains more recent data.
This method respects the time-based nature of the data and is critical in tasks where patterns change over time.
Wrapping Up
Data splitting is a critical part of the machine learning model building process, because we need to split our data both to train our models, and to properly evaluate them.
In this article, I’ve tried to explain the basic elements of model splitting, but it’s a complex topic, and just in the interest of time, I’ve left plenty of important details out.
That said, I’ll write more about some of the other aspects of data splitting in future blog posts.
But, if you want to read a little more now, you can read a related tutorial:
Leave your Questions Below
Do you still have questions about machine learning data splitting?
Is there something else you want to know about training, validation, and test sets?
I want to hear from you.
Leave your questions, concerns and comments in the comments section at the bottom of the page.
Sign up for our email list
If you want to learn more about machine learning and AI, then sign up for our email list.
Every week, we publish free long-form articles about a variety of topics in machine learning, AI, and data science, including:
- Machine Learning
- Deep Learning
- Scikit Learn
- Numpy
- Pandas
- Keras
- … and more
When you sign up for our email list, then we’ll deliver those tutorials to you, free, and direct to your inbox.
Thanks a lot!
You’re welcome.
Thanks for the great post!
I don’t get the exact difference between random and stratified splitting? If you have enough data and you split randomly then you get approximately the same proportion of class in the training, validation and test data. Is that right or I miss something?
When should one use the time-based splitting?
You mention when patterns change over time.
For example if I would like to build a churn model and the inflation rate among the calendar years is very different than I should split the data based on time? I don’t see then how would a good modell predict churns in a high inflation environment if it had been trained in a low inflation one.
If I left out the inflation rate as a explanatory variable then the model maybe would miss the most important factor.