If you want to build high-performing machine learning and AI systems, then simply training those systems is rarely enough.
You often need to build multiple models, often with multiple different algorithms, and then compare the different models to each other to see which is best.
And further, you often need to “tune” the settings of every different algorithm to get them to perform optimally (or close to it).
That’s right.
Most machine learning algorithms have “settings,” which we know in the industry as hyperparameters.
Working with hyperparameters is a big part of machine learning.
So in this blog post I want to introduce you to the high-level essentials of hyperparameters.
I’ll explain what they are, some of the common hyperparameters for popular machine learning algorithms, and I’ll briefly review some of the techniques that we use to select the best hyperparameter values.
If you need something specific, just click on any of the following links:
Table of Contents:
- Introduction
- Hyperparameters of Common ML Algorithms
- Hyperparameter Tuning Techniques
- Frequently Asked Questions
All that said, let’s get started.
A Quick Introduction to Model Hyperparameters
In machine learning and artificial intelligence, hyperparameters play a critical role in the construction and performance of models.
What is a Hyperparameter?
Let’s start off with a simple explanation of what hyperparameters are.
Hyperparameters are settings for a machine learning algorithm. These hyperparameters change how the algorithm works, and change the results of the training process.
But importantly, we need to distinguish hyperparameters from learned parameters.
Learned parameters are parameters that the machine learning algorithm learns as we expose it to training examples. These parameters are updated by the algorithm itself during the training process. For example, the neuron “weights” in a deep neural network are learned parameters.
In contrast, hyperparameters are parameters that the machine learning developer sets manually. Although there are a variety of ways of selecting the optimal values for hyperparameters, the important thing to understand is that the machine learning developer or data scientist chooses these settings, or at least, finds the optimal values.
In this sense, model hyperparameters are like the settings on a piece of equipment. For example, a guitar amplifier typically has multiple knobs and switches, such as knobs for volume, gain, bass, treble, and so on.

The knobs on a guitar amplifier are like the hyperparameters of a machine learning algorithm.
And just like how changing the setting on an amplifier will change how it performs (i.e., it will change the sound), changing the setting of machine learning hyperparameters will change how it performs. Changing hyperparameter setting will change how the algorithm learns and predicts.
Example: Neural Network Hyperparameters
Let’s look at a somewhat simple example from machine learning: a neural network.
A typical neural network has many different hyperparameters that you can tune including things like batch size, learning rate, and the type of optimizer. But those are a little abstract and hard to see.
On the other hand, neural networks have two hyperparameters that are very easy to see and understand: the number of hidden layers, and the number of nodes (i.e., neurons) per layer.
So let’s look at a visual example.
Here we have two neural networks:
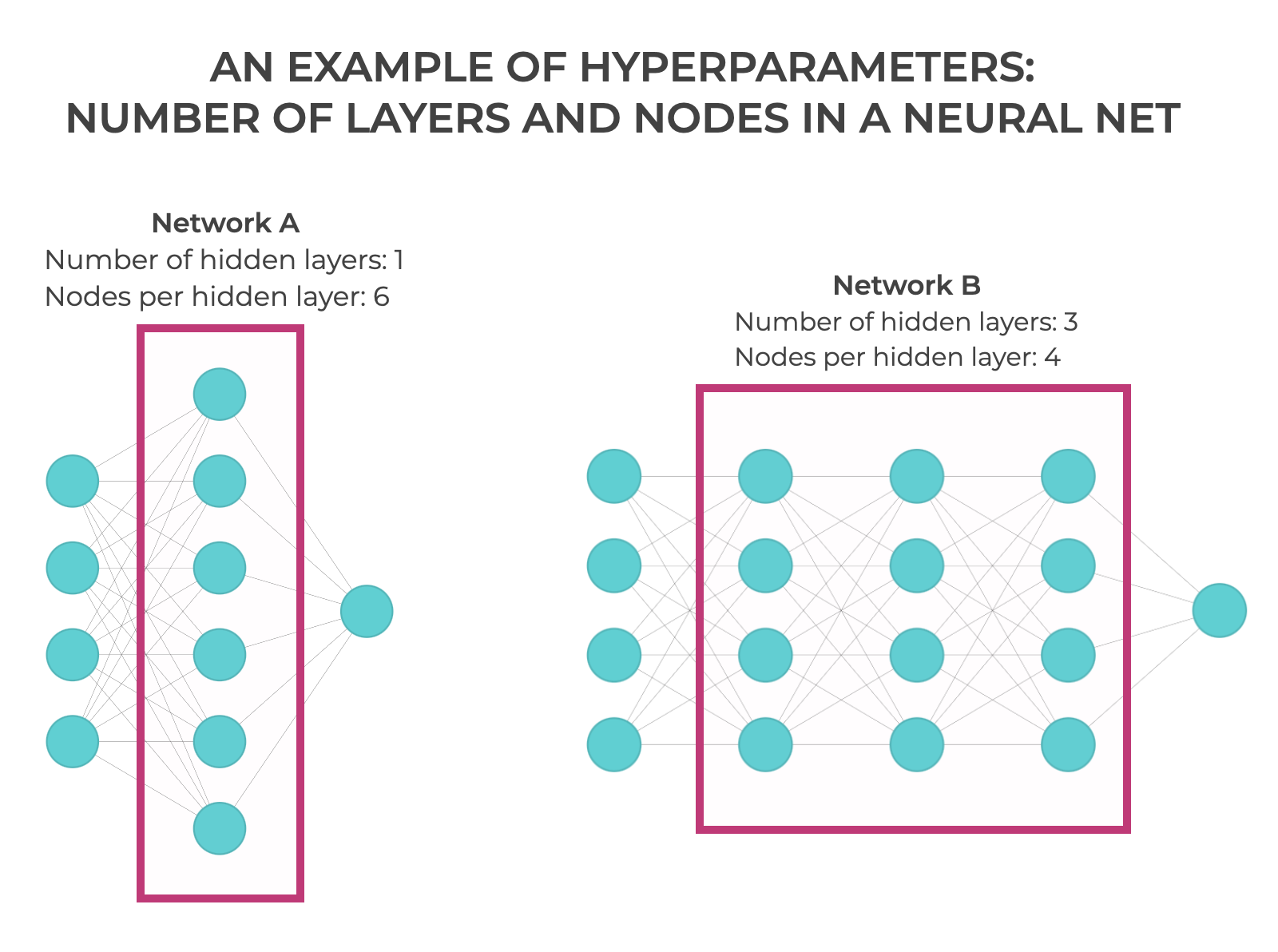
Note that in both, I’m treating the first layer as an input layer, as opposed to a “hidden” layer.
So in Network A on the left, there’s 1 hidden layer and it has 6 nodes.
And in Network B, on the right, there’s 3 hidden layers and they all have 4 nodes.
In these neural networks (and in all neural networks) the number of hidden layers and the number of nodes in each hidden layer are hyperparameters. You get to manually set them.
Of course, being able to choose the number of layers and the number of nodes per layer also means that you’re responsible for choosing good values.
In large part, building an effective machine learning model and optimizing its performance centers around finding good values for these hyperparameters.
Why Hyperparameters Matter in Machine Learning
Hyperparameters – particularly for complex model types, such as neural networks and boosted trees – are one of the primary determinants of both the efficiency and performance of a machine learning model.
They impact the model’s ability to learn from data and generalize to new, previously unseen data.
Moreover, properly chosen hyperparameter values can help you avoid common problems such as overfitting, where the model performs well on training data but poorly on new data, as well as underfitting, where the model is too simple to capture the underlying patterns in the data.
In many cases, hyperparameters determine the balance between underfitting and overfitting, and selecting good values helps you get a “good” fit enables a model to perform properly for the task.
Hyperparameters of Common Machine Learning Algorithms
Different machine learning algorithms have different hyperparameters (although some hyperparameters are used across a variety of ML algorithms, like learning rate).
That said, let’s look at some of the most important hyperparameters for some of the most important algorithms.
Deep Neural Networks
Deep networks have quite a few hyperparameters (this actually makes them hard to tune).
A few of the most important are:
- Learning Rate: This is the step size at each iteration while moving toward a minimum of the loss function. It’s critical in training neural networks as it affects the speed and quality of the learning process.
- Number of Layers and Neurons: These determine the depth and width of the network, respectively. More layers and neurons can capture more complex patterns but they also increase the risk of overfitting as well as computational expense.
- Activation Functions: Activation functions determine the type of output of individual neurons. Common activation functions are ReLU, sigmoid, and tanh, and each of these have pros and cons.
- Batch Size: Batch size influences how quickly the model converges convergence speed and also affects the ability of the model to generalize.
These are only a few of the most common hyperparameters for deep networks, generally. Other exist for specific deep learning architectures.
Random Forests
Random forests are one of the most flexible and best performing model types in machine learning, due to their nature as “ensemble” models.
But tuning them with good hyperparameter settings is critical.
A few of the most important hyperparameters of random forests are:
- Number of Trees: This is (as you might expect) the number of trees in the ensemble. More trees increase the risk of overfitting but also enhance the model’s complexity, enabling it to fit more intricate data patterns.
- Maximum Depth of Trees: Tree depth controls the depth of each tree in the ensemble. Deeper trees can model more complex patterns but may lead to overfitting.
- Minimum Samples for a Split: Determines the minimum number of samples required to split an internal node. A higher number can reduce the risk of overfitting.
Gradient Boosting Trees (including XGBoost, LightGBM, and CatBoost)
Gradient boosted trees – like random forests – are very flexible and powerful. Boosted trees are one of the favorite model types for Kaggle competitions, because they perform so well (particularly on tabular data).
And also like random forests, tuning the hyperparameters of boosted trees is critical for getting them to perform well.
The key hyperparameters of boosted trees are:
- Learning Rate: Learning rate dictates how quickly the model adapts to the problem. Learning rate in boosted trees is similar learning rate in neural networks. Smaller rates require more boosting rounds but can lead to better performance.
- Number of Iterations: Controls the number of sequential trees to be added to the model. Though more iterations typically yield more accurate models, there’s a higher risk of overfitting. This hyperparameter is somewhat similar to the number of “epochs” in neural nets.
- Max Depth of Trees: Similar to Random Forests, it determines the depth of each tree.
K-Nearest Neighbors
K-nearest neighbors (KNN) is a supervised learning technique used in both classification and regression that trains a model based on the “nearest neighbors” to a particular point in the data space.
The two hyperparameters of KNN are:
- Number of Neighbors (K): The most crucial hyperparameter that decides how many neighbors are voted to predict the label. Too few neighbors can make the model sensitive to noise, while too many can lead to misclassification.
- Distance Metric: The distance metric specifies how we compute distance between data points when we run the algorithm. Common options include Euclidean, Manhattan, and Minkowski distances. The choice of metric can significantly impact the performance of the algorithm.
Logistic Regression
Logistic regression is one of the simplest, but also most common algorithms for binary classification.
Two hyperparameters you should know for logistic regression are:
- Regularization (L1, L2, Elastic-Net): Regularization prevents overfitting by penalizing large coefficients. Different types of regularization options are L1 regularization (AKA, LASSO), L2 regularization (AKA, ridge), and Elastic-Net. The choice of regularization and its strength (lambda) can greatly influence model performance.
- Learning Rate: Learning rate is used in logistic regression implementations that use gradient descent, and can influence model performance as well as computational load.
Hyperparameter Tuning Techniques
Hyperparameter tuning involves selecting the optimal values for the hyperparameters of the specific learning algorithm that you’re using with the goal of maximizing the model’s performance.
Different tuning methods take different approaches to this task, each with its own advantages and limitations.
The 3 big ones are:
- Grid search
- Random search
- Bayesian Optimization
Let’s briefly look at each of these.
Grid Search
Grid search involves defining a grid of hyperparameter values and evaluating every combination of hyperparameters (i.e. positions in the grid).
For example, if you’re tuning two hyperparameters, and each hyperparameter has three different possible values, grid search would evaluate all 3×3=9 combinations.
- Pros: Grid search is thorough and it guarantees that the best combination in the grid will be found. It’s also simple to understand and relatively easy to implement.
- Cons: The main drawback of grid search is computational inefficiency, especially with large hyperparameter spaces or when dealing with complex models. It also scales poorly with the number of hyperparameters.
- Best Uses: Grid search is ideal for smaller datasets and fewer hyperparameter values. It’s a preferred method when computational resources are not a major constraint and when the hyperparameter space is not too large.
Random Search
Random search randomly selects combinations of hyperparameter values from a specified range.
Random search only evaluates a random subset of the total possible combinations of hyperparameter values. This is in contrast to grid search which tries all combinations.
- Pros: Random search is more efficient than grid search, especially in high-dimensional spaces. Random search can sometimes find a good combination of hyperparameters faster than grid search.
- Cons: It doesn’t guarantee finding the optimal combination, as only searches through a random subset of possible combinations.
- Best Uses: Useful when the hyperparameter space is large and computational resources are limited. It’s a good starting point for narrowing down the search space for further tuning.
Bayesian Optimization
Bayesian Optimization uses a probabilistic model to search for the best hyperparameters.
This method balances exploration (trying new hyperparameter combinations) and exploitation (using combinations known to perform well).
- Pros: Bayesian optimization is more efficient than Grid and Random Search, especially in high-dimensional spaces. It’s particularly effective when model training and validation are expensive.
- Cons: This method can be complex to implement and is often hard to understand. It also requires more sophisticated software tools.
- Best Scenarios: Bayesian optimization is ideal for optimizing complex models like deep learning networks, where every evaluation of the objective function is resource-intensive.
Wrapping Up
I have to be honest.
Machine learning hyperparameters and hyperparameter tuning are a huge topic. It’s almost impossible to cover everything in a single post.
I wanted to touch on the main points in this article, like what hyperparameters are, some of the common hyperparameters in machine learning models, and a few of the main techniques we use to optimize and select hyperparameters.
Having said that, since there’s so much more that I could write about these topics (especially hyperparameter tuning), I’m going to write more about them later, in future blog posts.
Leave your Questions Below
Are you still struggling to understand something about machine learning hyperparameters?
Is there something else that you want to know?
Tell me …
Leave your questions and comments in the comments section at the bottom of the page.
Sign up for our email list
If you want to learn more about machine learning and AI, then sign up for our email list.
Every week, we publish free long-form articles about a variety of topics in machine learning, AI, and data science, including:
- Machine Learning
- Deep Learning
- Scikit Learn
- Numpy
- Pandas
- Keras
- … and more
When you sign up for our email list, then we’ll deliver those tutorials to you, free, and direct to your inbox.