This tutorial will explain how to use the Numpy unique function.
It will explain what the np.unique function does, how the syntax works, and it will show you clear examples.
If you need something specific, you can click on any of the following links.
Table of Contents:
A Quick Introduction to Numpy Unique
The Numpy unique function is pretty straight forward: it identifies the unique values in a Numpy array.
So let’s say we have a Numpy array with repeated values. If we apply the np.unique function to this array, it will output the unique values.
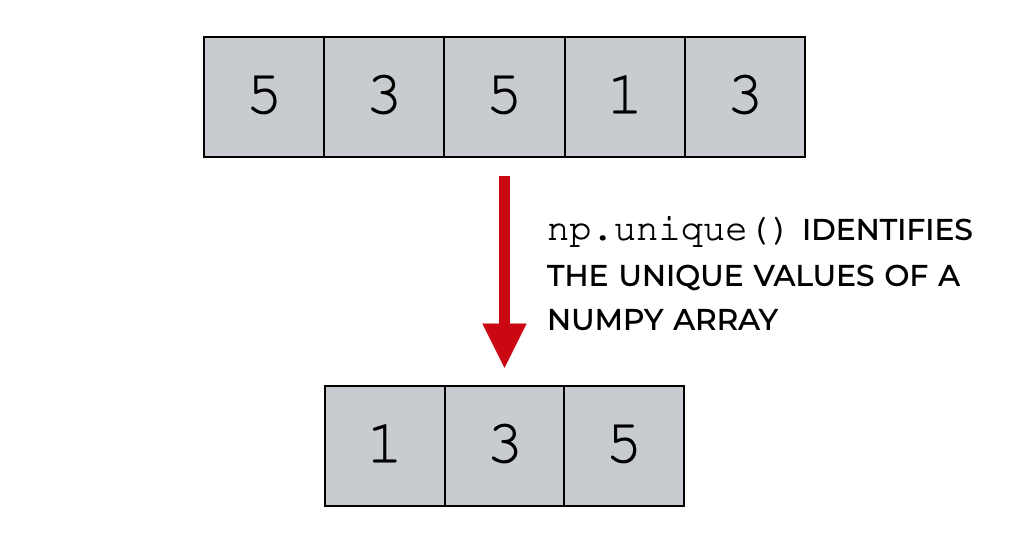
Additionally, the Numpy unique function can:
- identify the unique rows of a Numpy array
- identify the unique columns of a Numpy array
- compute the number of occurrences of the unique values
- identify the index of the first occurrence of the unique values
So the Numpy unique function identifies unique values, rows, and columns, but can also identify some other information about those unique values.
The syntax of np.unique
Now that I’ve briefly explained what the Numpy unique function does, let’s take a look at the syntax.
A quick note
On the syntax explanation here, and in the examples section below, I’m going to assume that you’ve imported Numpy with the following code:
import numpy as np
This is the common convention for importing Numpy. It’s important though, because the exact form of the syntax will depend on how we import Numpy.
np.unique syntax
The syntax is mostly straightforward.
We typically call the function as np.unique(), assuming that we’ve imported Numpy with the alias np.
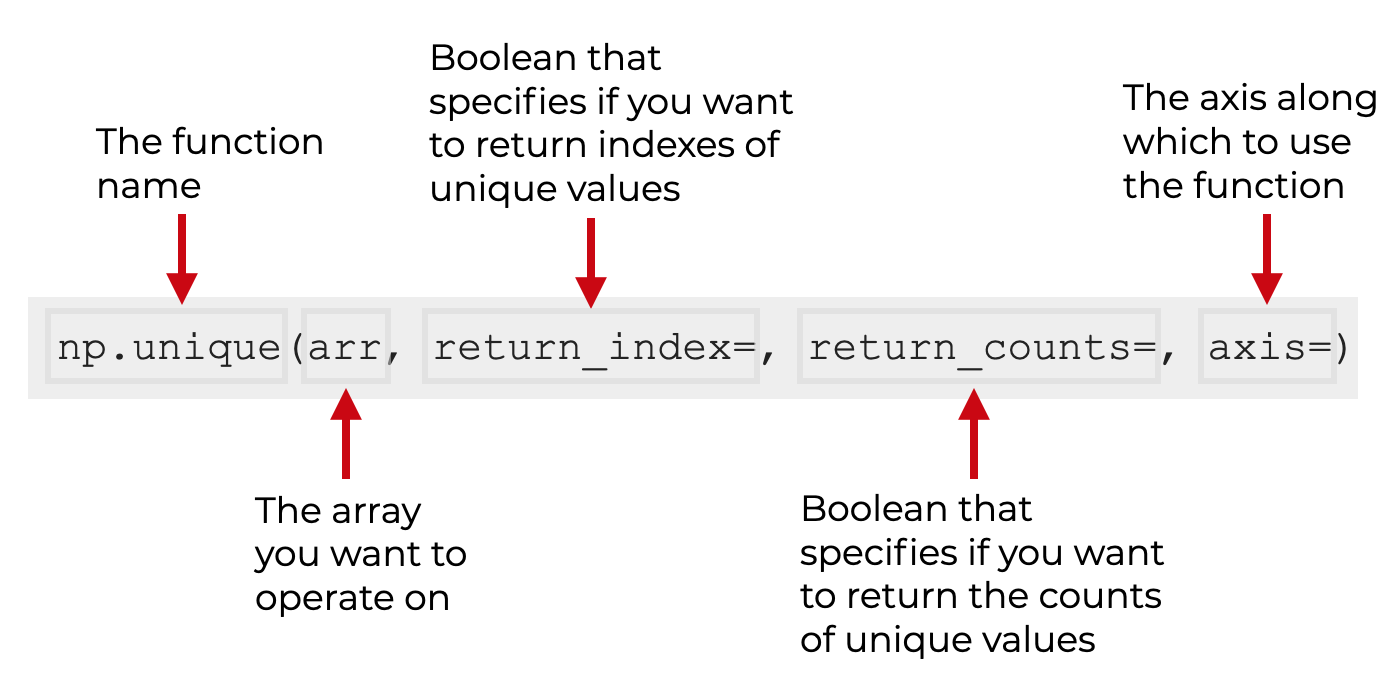
Inside the parenthesis, the first argument to the function will be the name of the array that you want to operate on.
In the above syntax, this is called arr, but here, you’ll actually use the name of your array. So if your array is called my_array, you’ll use the code np.unique(my_array).
This input array is required.
Additionally though, there are a set of optional parameters that you can use to modify the behavior of the function.
The parameters of np.unique
The np.unique function has four optional parameters:
return_indexreturn_countsaxisreturn_inverse
Let’s look at each of those.
return_index (optional)
When return_index = True, np.unique will return the index of the first occurrence of the unique value.
This parameter is optional.
By default, this is set to return_index = False.
return_counts (optional)
When return_counts = True, np.unique will return the number of times each unique value occurs in the input array.
This parameter is optional.
By default, this is set to return_counts = False.
axis (optional)
The axis parameter enables you to specify a direction along which to use the np.unique function.
If set to axis = None, the input array will be flattened before applying np.unique.
To learn more about the different axes (i.e., the “directions” along a Numpy array), you can read our tutorial about Numpy axes.
This parameter is optional.
By default, this is set to axis = None.
return_inverse (optional)
If return_inverse = True, np.unique will return the indices of the unique array. These index values can be used to reconstruct the original array.
This parameter is optional.
By default, this is set to return_inverse = False.
Examples of how to use Numpy Unique
Now that we’ve looked at the syntax of the np.unique function, let’s look at some examples.
Examples:
- Get unique values from a 1D Numpy array
- Identify index of first occurrence of unique values
- Get the counts of each unique value
- Get the unique rows and columns
Run this code first
Before you run any of these examples, you need to run some code to import Numpy and to create a dataset.
Import Numpy
To import Numpy, run this code:
import numpy as np
This will enable us to call Numpy functions with the prefix np.
Create Dataset
Now we’ll create a Numpy array.
Here, we’ll use the np.array function to create a 1-dimensional array.
array_with_duplicates = np.array([5,5,1,5,4,5,1,5,3,5,1,3])
As you can see, the array has several duplicated values.
EXAMPLE 1: Get unique values from a 1D Numpy array
First, let’s get get the unique values from our 1D array, array_with_duplicates.
# GET UNIQUE VALUES np.unique(array_with_duplicates)
OUT:
array([1, 3, 4, 5])
Explanation
This is pretty simple.
The input array, array_with_duplicates, has the values 1, 3, 4, and 5, but they are duplicated and organized in random order.
When we apply the np.unique() function, the output is a Numpy array of the unique values. These unique values are sorted in ascending order.
EXAMPLE 2: Identify index of first occurrence of unique values
Next, we’re going to get the unique values and also get the index of the first occurrence of each unique value.
To do this, we’ll use the return_index parameter.
# GET UNIQUE VALUES, WITH INDEX OF FIRST OCCURRENCE unique_values, first_occurrence_index = np.unique(array_with_duplicates, return_index = True)
Next, let’s print each of these output arrays.
print('These are the unique values:')
print(unique_values)
print('These are the indexes of the first occurrence:')
print(first_occurrence_index)
OUT:
These are the unique values: [1 3 4 5] These are the indexes of the first occurrence: [2 8 4 0]
Explanation
Here, we used the np.unique() on our input array, and we set parameter return_index = True.
This caused np.unique() to output two Numpy arrays:
- one array with the unique values (
unique_values) - another array with the index of the first occurrence of every unique value (
first_occurrence_index)
Just remember: when you set return_index = True, np.unique() will output two arrays!
EXAMPLE 3: Get the counts of each unique value
Now, we’ll get the unique values and get the count of the number of occurrences of each unique value.
To do this, we’ll use the return_counts parameter.
# GET UNIQUE VALUES, WITH COUNTS unique_values, value_count = np.unique(array_with_duplicates, return_counts = True)
Next, let’s print each of these output arrays.
print('These are the unique values:')
print(unique_values)
print('These are the counts of the unique values:')
print(value_count)
OUT:
These are the unique values: [1 3 4 5] These are the counts of the unique values: [3 2 1 6]
Explanation
Here, we used the np.unique() on our input array, and we set parameter return_counts = True.
This caused np.unique() to output two Numpy arrays:
- one array with the unique values (
unique_values) - another array with the count of the number of occurrences of every unique value (
value_count)
Again, when you set return_counts = True, np.unique() will output two arrays!
EXAMPLE 4: Get the unique rows and columns
Finally, let’s identify the unique rows and the unique columns of an array.
To do this, we’ll use the axis parameter.
Create 2D Array
To run this example, we first need to create a 2-dimensional array. So here, we’ll create a 2D array using the Numpy array function.
dupe_array_2d = np.array([[1,2,1],[2,2,2],[1,2,1]])
And now, let’s look at it with a print statement:
print(dupe_array_2d)
OUT:
[[1 2 1] [2 2 2] [1 2 1]]
So the array, dupe_array_2d, is a two dimensional array with 3 rows and 3 columns.
If you look carefully, you’ll notice that the 1st and 3rd rows are the same. The 1st and 3rd columns are also the same.
Get unique rows and columns
Now that we have our array, let’s get the unique rows and unique columns.
To get the unique rows, we set axis = 0, and to get the unique columns, we set axis = 1.
# GET UNIQUE ROWS
print('Unique rows:')
np.unique(dupe_array_3x4, axis = 0)
# GET UNIQUE COLUMNS
print('Unique columns:')
np.unique(dupe_array_3x4, axis = 1)
OUT:
Unique rows:
array([[1, 2, 1],
[2, 2, 2]])
Unique columns:
array([[1, 2],
[2, 2],
[1, 2]])
Explanation
This is somewhat straightforward, if you understand how axes work.
For a 2D array, axis-0 points downward and axis-1 points horizontally.
So when we set axis = 0, np.unique operates downward in the axis-0 direction. This causes it to identify the unique rows.
Similarly, when we set axis = 1, np.unique operates horizontally in the axis-1 direction. This causes it to identify the unique columns.
This is fairly simple once you understand how Numpy axes work. Having said that, many people are confused by Numpy axes. If you need help understanding how axes work, read our explanation of Numpy array axes.
Leave your other questions in the comments below
Do you have other questions about the Numpy unique function?
If so, leave your questions in the comments section at the bottom of the page.
For more Python data science tutorials, sign up for our email list
This tutorial should have given you a good understanding of the Numpy unique function.
But to learn data science in Python, you’ll need to learn a lot more about Numpy. In fact, you’ll need to learn about Pandas, and several other data science topics.
So if you want to learn Python data science, you should sign up for our FREE email list.
When you sign up, you’ll get free tutorials on:
- NumPy
- Pandas
- Base Python
- Scikit learn
- Machine learning
- Deep learning
- … and more.
We publish new tutorials every week, and when you sign up for our free email list, these tutorials will be delivered directly to your inbox.
good
Hi my brother, Excellent and Excellent.
How to apply the np.unique() method on the multi-dimensional arrays(3D arrays and above)??
I read more than thousand blogs or Pages and recently visited on your page your pages about python is really a quality page.. Quality means a brief explanation of each and every syntax elements. I rarely make a comment i only make comment when something touch my heart. The words are so less about your way of expressing the content and make it simpler.
Thanks for your comment, Himanshu.