This tutorial will show you how to use the Pandas reset index method.
It will explain the syntax of reset_index, and it will also show you clear step-by-step examples of how to use reset_index to reset the index of a Pandas DataFrame.
The tutorial has several sections. You can click on one of the following links, and the link will take you to the appropriate section in the tutorial.
Table of Contents:
- A quick review of Pandas indexes
- Introduction to Pandas reset index
- The syntax of reset_index
- Reset index examples
- Reset index FAQ
Having said that, if you’re new to Pandas, or new to using Pandas DataFrame indexes, you should probably read the whole thing.
Ok … let’s get started.
A quick review of Pandas indexes
To understand the Pandas reset index method, you really need to understand Pandas DataFrame indexes. You really need to understand what an index is, why we need them, and how we set indexes in Pandas.
Once you know that, we’ll be ready to talk about the reset_index method.
With that in mind, let’s review Pandas DataFrames and DataFrame indexes.
A quick review of Pandas DataFrames
Briefly, let’s review DataFrames.
A Pandas DataFrame is a data structure in Python.
DataFrames have a row-and-column structure. Variables are along the columns, and observations (i.e., records) are down the rows.
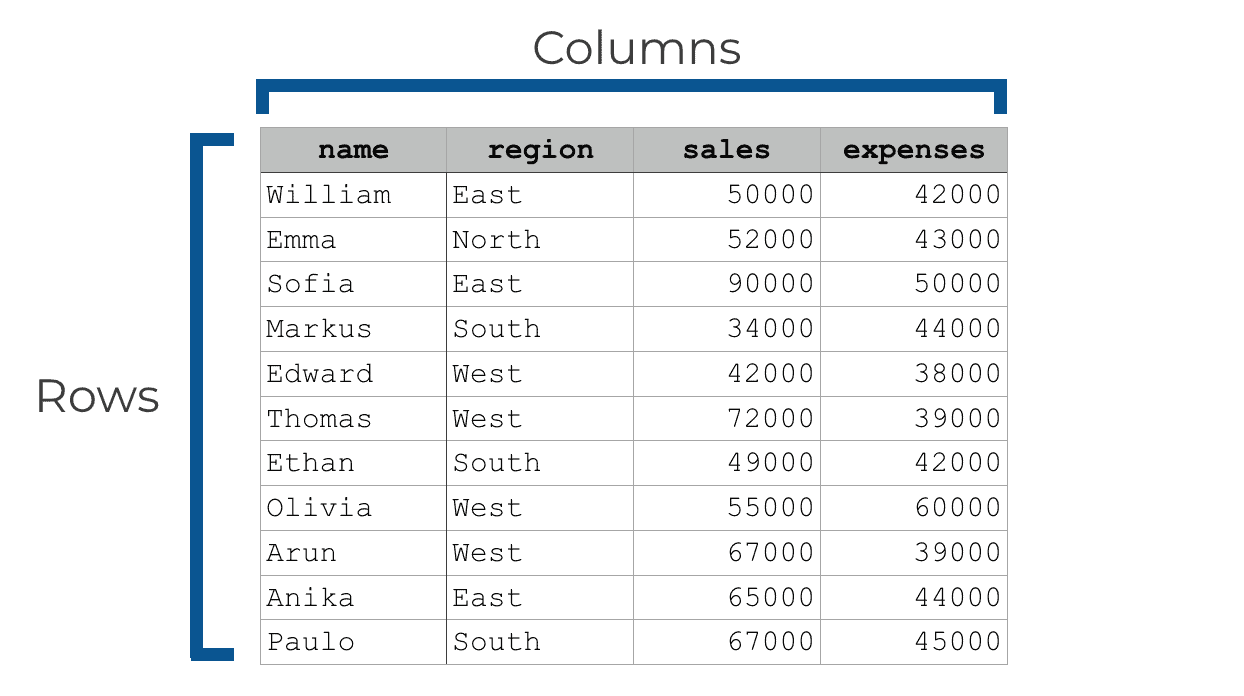
At a high level, a Pandas DataFrame is a lot like an Excel spreadsheet. It’s just a row-and-column structure that holds data and enables us to perform analyses on that data.
Pandas dataframes have an “index”
One important feature of the DataFrame is what we call the “index.”
Every Pandas DataFrame has a special column-like structure called the index. To be clear, an index is only sort of like a column, but properly speaking, it’s not actually one of the columns of a DataFrame.
If you print out a DataFrame, you’ll see the index on the far left hand side.
By default, if you don’t set any other index for the DataFrame, the index values will just be the integers starting from 0.
It looks something like this:
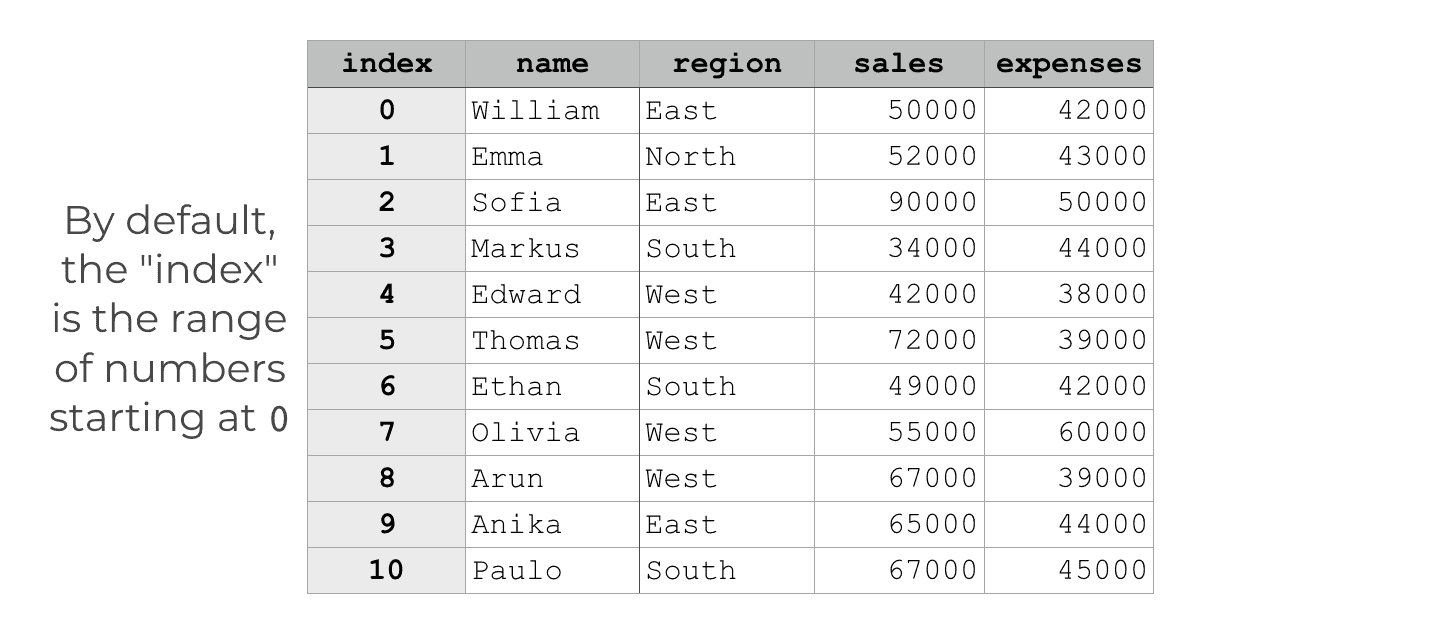
By default, every row will have an integer associated with it, starting with the number 0. We can use this integer index to retrieve rows by number using the Pandas iloc method.
We use indexes for data access and retrieval
The index is important.
A DataFrame index enables us to retrieve individual rows.
When we have a default numeric index, we can retrieve a row or a slice of rows by integer index. We typically do this with the Pandas iloc method.
The important thing to understand is that the index values act as sort of an “address” for the rows. So you can use techniques like Pandas iloc to retrieve or access specific rows.
You can set a new index for your Pandas DataFrame
Although Pandas DataFrames have a numeric index by default, you can also set a new index for a DataFrame.
There are a few ways to do this (including a way to set an index with pandas read_csv). But, the most common way to set a new index for a Pandas DataFrame is with the Pandas set index method.
When you use set_index, the function typically transforms a column into the DataFrame index.
So for example, if your DataFrame has a column called name, you can use the set_index method to set name as the index. This would allow you to select individual rows by the name of the person associated with the row.
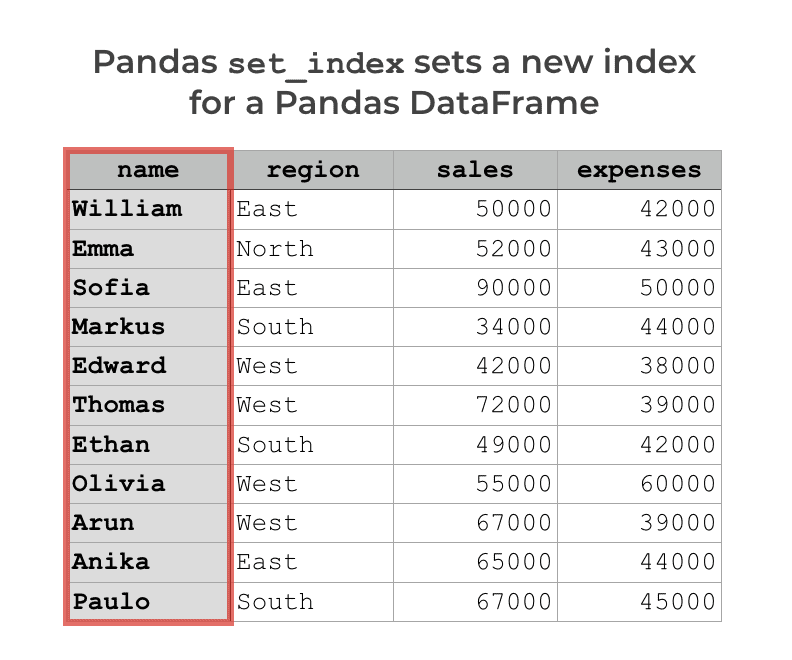
But let’s say that you’ve set an index. For example, in the image above, the DataFrame has the index “name“.
What do you do if you want to remove the index and “reset” the DataFrame index back to the default numeric index?
To do that, you use the Pandas reset index method.
A quick introduction to Pandas reset index
The Pandas reset index method “resets” the current index.
Effectively, it takes the index of a DataFrame and turns it back into a proper column.
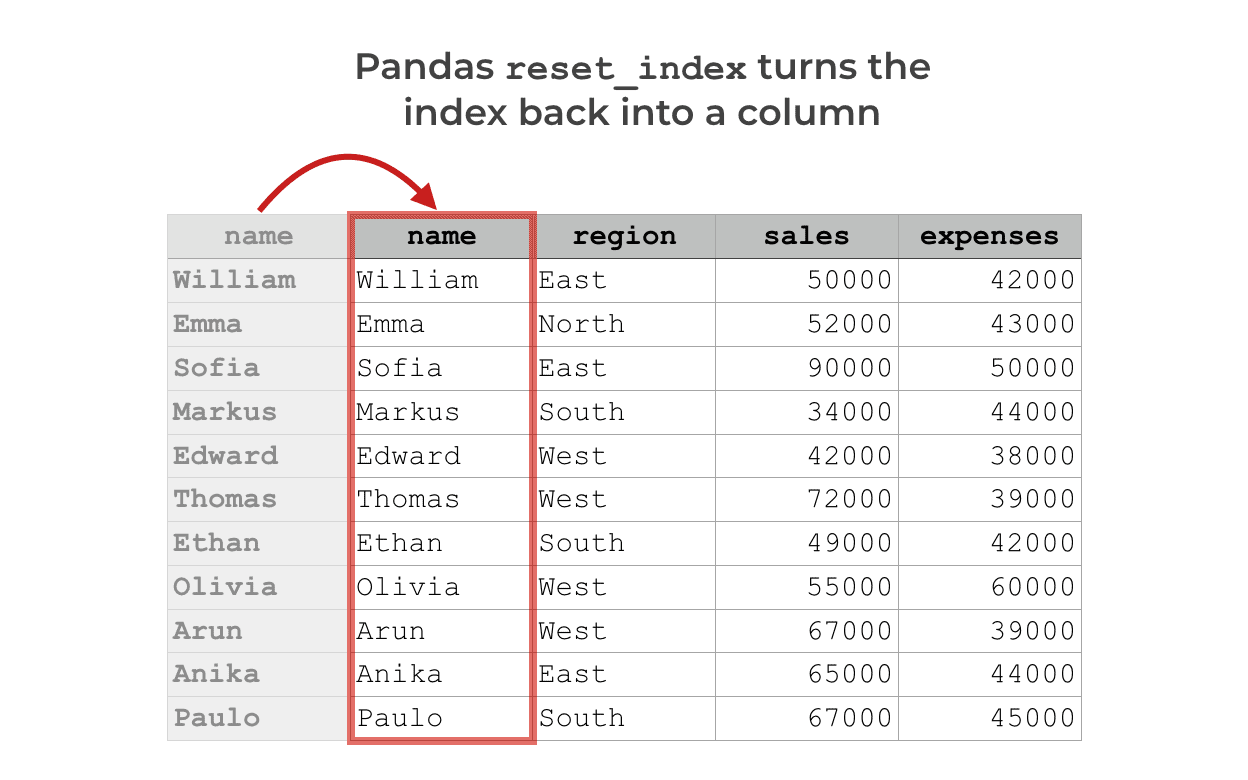
At the same time, it resets the index of the DataFrame back to the default integer index.
Having said that, there’s a little more to it. There are a few details of the method that are dictated by some details of the syntax.
With that being said, let’s look at the syntax of reset_index.
The syntax of Pandas reset_index
In the most basic case, the syntax of reset_index is fairly simple.
We simply type the name of the DataFrame, and then we use “dot syntax” to call the method.
Essentially, we type the name of the DataFrame, then a “dot”, and then reset_index().
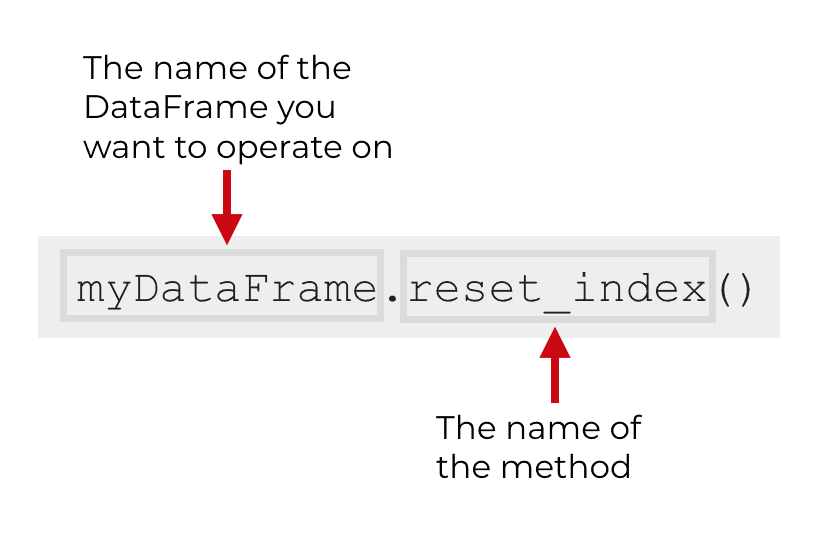
If we do this, the reset_index method will take the existing index (whatever it is) and will turn the index into a column of the DataFrame. At the same time, it will reset the index back to the default numeric index starting at 0.
Having said that, there are some parameters for reset_index that enable you to modify the behavior of the function.
Let’s take a look at those parameters.
The parameters of reset_index
The reset_index method has several parameters that enable you to modify the behavior of the method.
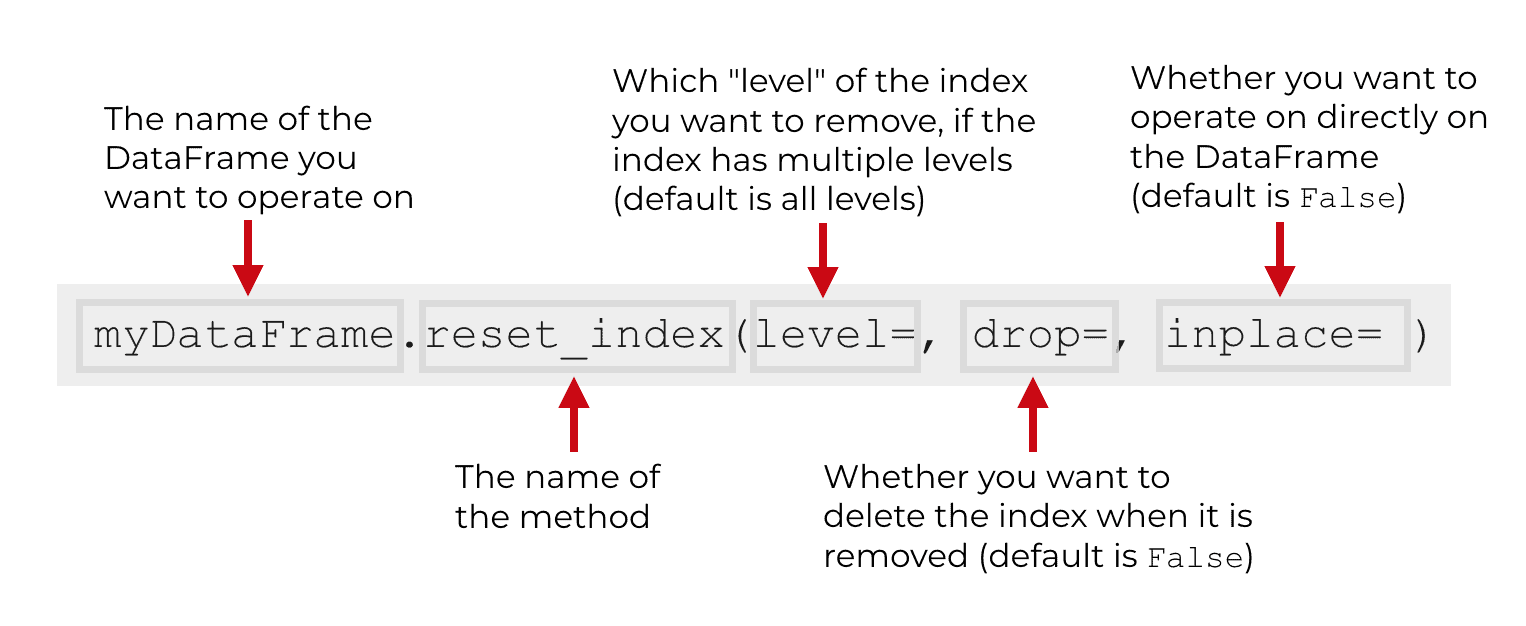
The specific parameters that we’ll focus on are:
leveldropinplace
The reset_index method also has parameters col_level, and col_fill. These are used less frequently, so we’re not going to cover them in this tutorial.
Having said that, let’s take a look at level, drop, and inplace.
level
The level parameter enables you to specify which level you want to “reset” and remove from the index.
This is applicable only if you have multiple levels in your index, which is sort of a special case.
You don’t need to provide any argument to this parameter. By default, it will simply remove all of the levels (and return all parts of the index back to the DataFrame).
I’ll show you an example of this in the examples section, so you understand how it works.
drop
The drop parameter enables you to specify whether or not you want to delete the index entirely from the DataFrame.
Recall what I mentioned above: the Pandas reset_index method takes the index and returns the index back to the columns.
That’s the default behavior. By default, the drop parameter is set to drop = False (even if you don’t explicitly use the drop parameter).
You can change this though. If you set drop = True, reset_index will delete the index instead of inserting it back into the columns of the DataFrame. If you set drop = True, the current index will be deleted entirely and the numeric index will replace it.
inplace
By default, the inplace parameter is set to inplace = False.
When inplace is set to False, the reset_index method will create an entirely new DataFrame as output. That means, when inplace is set to inplace = False (the default!), reset_index DOES NOT CHANGE THE ORIGINAL DATAFRAME.
This is important. Many people think that reset_index will operate directly on the original DataFrame that you’re referencing when you call the method. By default, it does not.
Instead, it simply creates a new DataFrame. Keep in mind, this new DataFrame will be sent to the console unless you assign it to a variable.
However, it is possible to have reset_index operate directly on the DataFrame.
To do this, you need to set inplace = True.
When you set inplace = True, the reset_index method will not create a new DataFrame. Instead, it will directly modify and overwrite your original DataFrame.
Sometimes that’s exactly what you want, but be careful! When you set inplace = True, reset_index will overwrite your data, so make sure that it’s working properly.
The output of reset_index
By default, the Pandas reset_index method creates a new DataFrame as output and leaves the original DataFrame unchanged.
As noted in the section above, you can change this by setting inplace = True. If you set , the reset_index method will not create a new DataFrame. Instead, it will directly modify and overwrite your original DataFrame.
Examples: how to reset the index of a Pandas DataFrame
Ok. Now that you’ve learned about the syntax of reset_index, let’s look at some examples of reset_index.
Examples:
- Reset the index of a DataFrame
- Delete the index completely
- Reset a specific level
- Reset the index in place
Run this code first
Before you run any of the examples, you need to import Pandas and create a DataFrame.
Let’s do both of those.
Import Pandas
Here, we’re just going to import the Pandas package.
You should know this, but Pandas is a data manipulation toolkit for Python. The reset_index method is one of the tools of Pandas.
To import Pandas into your working environment, you can run the following import statement:
import pandas as pd
This will import the Pandas package with the alias “pd“.
Create DataFrame
Next, we’re going to create a Pandas DataFrame with some “dummy” data.
To do this, we’ll use the pd.DataFrame() method to create a new DataFrame from a dictionary.
sales_data = pd.DataFrame({
"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
We’ve called this DataFrame sales_data. This contains dummy sales data for 11 people.
Let’s print the data and take a look.
print(sales_data)
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
3 Markus South 34000 44000
4 Edward West 42000 38000
5 Thomas West 72000 39000
6 Ethan South 49000 42000
7 Olivia West 55000 60000
8 Arun West 67000 39000
9 Anika East 65000 44000
10 Paulo South 67000 45000
As you can see, there are 11 rows and 4 columns (name, region, sales, and expenses).
Notice one thing.
On the far left hand side of the DataFrame is a column of integers starting at 0. This is the default index.
If you want, you can actually examine the index with this code:
print(sales_data.index)
OUT:
RangeIndex(start=0, stop=11, step=1)
The default index is something called a RangeIndex. Don’t let this confuse you … that just means that the index is the “range” of integers starting at 0 and ending at 11 (excluding 11).
Ok. Now we’re ready for some examples.
EXAMPLE 1: Reset the index of a DataFrame
In this example, we’re going to reset the index of our Pandas DataFrame.
But before we do that, we’re going to set the index first.
Set index
Here, we’re going to set the index to the name variable.
We’ll do this with the Pandas set index method.
sales_data.set_index('name', inplace = True)
And let’s print out the data:
print(sales_data)
OUT:
region sales expenses
name
William East 50000 42000
Emma North 52000 43000
Sofia East 90000 50000
Markus South 34000 44000
Edward West 42000 38000
Thomas West 72000 39000
Ethan South 49000 42000
Olivia West 55000 60000
Arun West 67000 39000
Anika East 65000 44000
Paulo South 67000 45000
Notice that in the printout above, the “name” column is actually set off to the side, separate from the regular columns. That’ because name is now the “index” of the DataFrame.
We can also manually look at the index by accessing the index attribute:
print(sales_data.index)
OUT:
Index(['William', 'Emma', 'Sofia', 'Markus', 'Edward', 'Thomas', 'Ethan',
'Olivia', 'Arun', 'Anika', 'Paulo'],
dtype='object', name='name')
As you can see, the index values are the “names” now.
Ok. Next, we’ll use reset_index to undo that operation.
Reset the index
Now, we’ll use reset_index to reset the index.
sales_data.reset_index()
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
3 Markus South 34000 44000
4 Edward West 42000 38000
5 Thomas West 72000 39000
6 Ethan South 49000 42000
7 Olivia West 55000 60000
8 Arun West 67000 39000
9 Anika East 65000 44000
10 Paulo South 67000 45000
Notice that in the output, name has been returned to the columns.
name is no longer the index in this output.
Instead, the output shows the range of integers starting at 0 as the new index.
Note: the original dataframe has not been changed
Before we move on, I want to make one other point. If you print out the sales_data DataFrame, you’ll notice that it still has name as the index.
Why? Didn’t we just use reset_index to undo the index?
Remember that by default, the inplace parameter is set to inplace = False. As I explained earlier in the syntax section, this means that by default, reset_index creates a new DataFrame. It does not change the original.
However, we can modify that behavior. I’ll show you how in another example.
EXAMPLE 2: Delete the index completely
Next, we’ll use the drop parameter to delete the index completely.
Before we do this, we’re going to recreate the DataFrame.
If you already have the DataFrame with name as the index, you can skip this part.
sales_data = pd.DataFrame({
"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
sales_data.set_index('name', inplace = True)
Ok. Now we’re going to reset the index and delete it altogether.
sales_data.reset_index(drop = True)
OUT:
region sales expenses 0 East 50000 42000 1 North 52000 43000 2 East 90000 50000 3 South 34000 44000 4 West 42000 38000 5 West 72000 39000 6 South 49000 42000 7 West 55000 60000 8 West 67000 39000 9 East 65000 44000 10 South 67000 45000
Notice that in the output, the index has been reset to the integer index.
Moreover, the name variable is completely gone.
By setting drop = True, we caused the reset_index method to “drop” (i.e., delete) the variable.
EXAMPLE 3: Reset a specific level
Next, we’ll reset a specific level of the index.
To do this, we’ll need a DataFrame with a multi-level index.
That being said, let’s first create our data.
sales_data = pd.DataFrame({
"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
And we’ll set the index with multiple variables, name and region:
sales_data.set_index(['name', 'region'], inplace = True)
And let’s print it:
sales_data.set_index(['name', 'region'], inplace = True)
OUT:
sales expenses
name region
William East 50000 42000
Emma North 52000 43000
Sofia East 90000 50000
Markus South 34000 44000
Edward West 42000 38000
Thomas West 72000 39000
Ethan South 49000 42000
Olivia West 55000 60000
Arun West 67000 39000
Anika East 65000 44000
Paulo South 67000 45000
Notice that this DataFrame has two index levels: name and region. You can also examine the index with print(sales_data.index).
Ok. Now that we have our DataFrame, let’s reset the region portion of the index. We’ll do this by setting level = 'region'.
sales_data.reset_index(level = 'region')
OUT:
region sales expenses
name
William East 50000 42000
Emma North 52000 43000
Sofia East 90000 50000
Markus South 34000 44000
Edward West 42000 38000
Thomas West 72000 39000
Ethan South 49000 42000
Olivia West 55000 60000
Arun West 67000 39000
Anika East 65000 44000
Paulo South 67000 45000
If you inspect the output (or print out the actual index), you’ll see that region has been “reset” to one of the columns. But, only the region variable has been reset. name is still in the index.
EXAMPLE 4: Reset the index in place
Finally, let’s reset the index “in place.”
Remember from earlier in the tutorial, when I explained the inplace parameter: by default, reset_index does not modify the original DataFrame. It simply creates a new dataframe.
But, we can change that behavior and cause reset_index to directly modify the original DataFrame by setting inplace = True.
Before we do that, let’s quickly re-create our data, so that it’s structured properly.
sales_data = pd.DataFrame({
"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
And we’ll set the index with multiple variables, name and region:
sales_data.set_index(['name', 'region'], inplace = True)
Now we have sales_data with name as the index.
Ok. Let’s reset the index “in place.”
sales_data.reset_index(inplace = True)
And let’s print it out:
print(sales_data)
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
3 Markus South 34000 44000
4 Edward West 42000 38000
5 Thomas West 72000 39000
6 Ethan South 49000 42000
7 Olivia West 55000 60000
8 Arun West 67000 39000
9 Anika East 65000 44000
10 Paulo South 67000 45000
When we print out sales_data, you can see that name is now one of the columns, and the index is the range of numbers from 0 to 10.
In this example, by setting inplace = True, we caused the Pandas reset_index method to directly modify the DataFrame in question.
Frequently asked questions about Pandas reset index
Now that you’ve learned about reset index and seen some examples, let’s review some frequently asked questions about the reset index method.
Frequently asked questions:
Question 1: Pandas reset index doesn’t seem to work? Why?
If you tried to use reset index and it didn’t change your DataFrame, you probably didn’t use inplace = True.
I explain this in the syntax section. By default, the inplace parameter is set to inplace = False. That causes reset_index to create a new DataFrame as an output. When inplace = False – which is the default behavior – the reset_index method will leave the original DataFrame unchanged.
To fix this behavior, and to directly modify the original DataFrame, you probably need to set inplace = True.
You can see an example of this in example 4.
Leave your other questions in the comments below
Do you have other questions about the reset index method in Python?
Leave your questions in the comments section below.
Join our course to learn more about Pandas
If you’re serious about learning Pandas, you should enroll in our premium Pandas course called Pandas Mastery.
Pandas Mastery will teach you everything you need to know about Pandas, including:
- How to subset your Python data
- Data aggregation with Pandas
- How to reshape your data
- and more …
Moreover, it will help you completely master the syntax within a few weeks. You’ll discover how to become “fluent” in writing Pandas code to manipulate your data.
Find out more here:
Very very nice explanation. I liked the way you explained with good examples. I appreciate your work. Keep it up.
Thanks Rishikesh.