This tutorial will show you how to use the Pandas query method to subset your data.
The tutorial will explain the syntax and also show you step-by-step examples of how to use the Pandas query method.
If you need something specific (like help with syntax, examples, etc), you can click on one of the following links and it will take you to the appropriate section.
Contents:
- A Quick Review of Pandas
- Introduction to Pandas Query
- The syntax of Pandas Query
- Pandas Query Examples
- Pandas Query FAQ
But if you’re new to Pandas, or new to data manipulation in Python, I recommend that you read the whole tutorial. Everything will make more sense that way.
Ok …. let’s get to it.
A Quick Review of Pandas
Very quickly, let’s review what Pandas is.
Pandas is a package for the Python programming language.
Specifically, Pandas is a toolkit for performing data manipulation in Python. It is a critical toolkit for doing data science in Python.
Pandas works with DataFrames
To get a little more specific, Pandas is a toolkit for creating and working with a data structure called a DataFrame.
A DataFrame is a structure that we use to store data.
DataFrames have a row-and-column structure, like this:
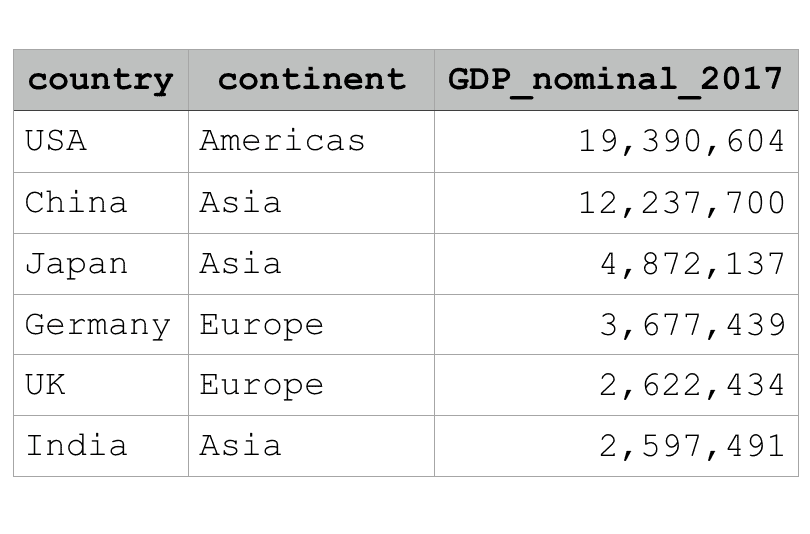
If you’ve worked with Microsoft Excel, you should be familiar with this structure. A Pandas DataFrame is very similar to an Excel spreadsheet, in that a DataFrame has rows, columns, and cells.
There are several ways to create a DataFrame, including importing data from an external file (like a CSV file); and creating DataFrames manually from raw data using the pandas.DataFrame() function.
For more information about DataFrames, check out our tutorial on Pandas DataFrames.
Pandas methods perform operations on DataFrames
Once you have your data inside of a dataframe, you’ll very commonly need to perform data manipulation.
If your data are a little “dirty,” you might need to use some tools to clean the data up: modifying missing values, changing string names, renaming variables, adding variables, etc.
Moreover, once your data are in the DataFrame structure and the data are “clean,” you’ll still need to use some “data manipulation” techniques to analyze your data. Here, I’m talking about things like subsetting, grouping, and aggregating.
Pandas has tools for performing all of these tasks. It is a comprehensive toolkit for working with data and performing data manipulation on DataFrames.
A quick introduction to Pandas query
Among the many tools for performing data manipulation on DataFrames is the Pandas query method.
What is .query() and what does it do?
Query is a tool for querying dataframes and retrieving subsets
At a very high level, the Pandas query method is a tool for generating subsets from a Pandas DataFrame.
For better or worse, there are actually several ways to generate subsets with Pandas.
The loc and iloc methods enable you to retrieve subsets based on row and column labels or by integer index of the rows and columns.
And Pandas has a bracket notation that enables you to use logical conditions to retrieve specific rows of data.
But both of those tools can be a little cumbersome syntactically. Moreover, they are hard to use in conjunction with other data manipulation methods in a smooth, organic way.
In many ways, the Pandas .query method solves those problems.
Query enables you to “query” a DataFrame and retrieve subsets based on logical conditions.
Moreover, the syntax is a little more streamlined than Pandas bracket notation.
Additionally, the Pandas query method can be used with other Pandas methods in a streamlined way that makes data manipulation smooth and straightforward. I’ll show you a little example of that later in the tutorial.
But before we get there, let’s first take a look at the syntax of Pandas query.
The syntax of the Pandas query method
The syntax of Pandas query is mostly straightforward.
In order to use this method though, you’ll need to have a Pandas DataFrame.
What that means is that you’ll need to import Pandas and use Pandas to create a DataFrame.
For more information about how to create DataFrames, you can read our introductory tutorial on Pandas DataFrames.
Pandas query syntax
Ok.
Assuming you have a DataFrame, you need to call .query() using “dot syntax”.
Basically, type the name of the DataFrame you want to subset, then type a “dot”, and then type the name of the method …. query().
Like this:
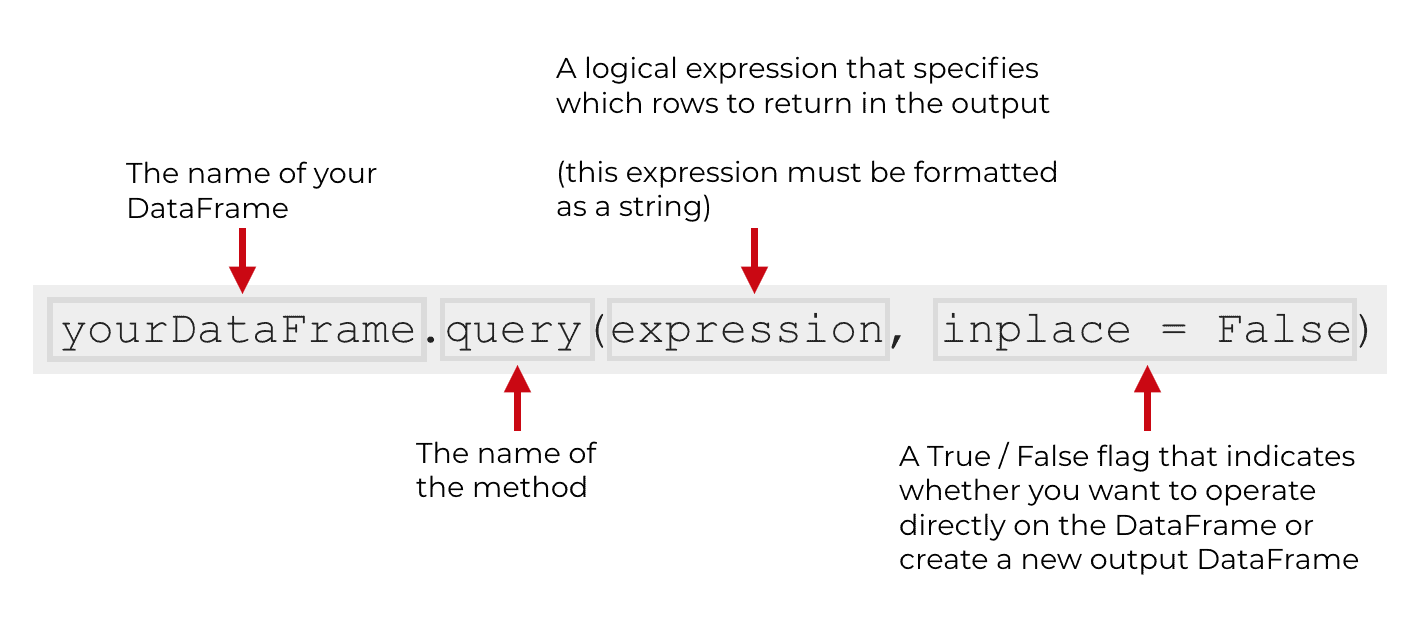
In the above syntax explanation, I’m assuming that you have a DataFrame named yourDataFrame.
Then, inside of the query method, there are a few parameters and arguments to the function.
Let’s walk through those.
The parameters of pandas query
Inside of the function, there are really only two arguments or parameters that you need to know about:
expressioninplace
Let’s talk about each of them individually.
expression (required)
Here, the expression is some sort of logical expression that describes which rows to return in the output.
If the expression is true for a particular row, the row will be included in the output. If the expression is false for a particular row, that row will be excluded from the output. I’ll show you several examples of these expressions in the examples section of this tutorial.
One note: the expression itself must be presented as a Python string. That means that the expression must be enclosed inside of quotations … either double quotations or single quotations.
Keep in mind, that you may also need to use strings inside of the expression itself. For example, if you need to reference a category called “Dog” inside of your logical expression, and you enclose that category inside of double quotation marks, you’ll need to enclose the overall expression inside of single quotes. If you’re not familiar with this, please review how strings work in Python, and review how to reference strings within strings.
inplace
The inplace parameter enables you to specify if you want to directly modify the DataFrame you’re working with.
Remember from the syntax section, when we use the .query() method, we need to type the name of the DataFrame that we want to subset. That DataFrame will serve as the input of the query method.
However, by default, the query method will produce a new DataFrame as the output, and will leave the original DataFrame unchanged.
That’s because by default, the inplace parameter is set to inplace = False. What that means is that query will not modify the original DataFrame “in place”. Instead it creates a new DataFrame. That is literally what the inplace parameter means.
But we can change that behavior by setting inplace = True.
If we override the default and set inplace = True, query will modify the original DataFrame “in place”.
But be careful … if you do this you will overwrite your original DataFrame. Make sure that your code is working the way you want it to!
Examples: how to use .query() to subset a Pandas dataframe
Ok, now that you’ve learned how the syntax works, let’s take a look at some examples.
Examples:
- Subset a pandas dataframe based on a numeric variable
- Select rows based on a categorical variable
- Subset a DataFrame by index
- Subset a pandas dataframe by comparing two columns
- Select rows based on multiple conditions
- Reference local variables inside of query
- Modify a DataFrame in Place
Run this code first
Before we actually work with the examples, we need to run some preliminary code.
We’re going to import Pandas and create a dataframe.
Import Pandas
First, let’s just import Pandas.
This is fairly straightforward, but if you’re a beginner, you might not be familiar with it.
To call any function from Pandas (or any other package), we need to first import the package. We import a package with the import statement.
Moreover, we can import a package with the original name (i.e., import pandas). But we also have the option of importing a package with a “nickname.” That’s a very common way of doing things, and that’s what we’re going to do here.
We’re going to import Pandas with the nickname “pd“.
import pandas as pd
Create Data Frame
We also need a dataframe to work with.
Here, we’ll use a create a DataFrame with some dummy sales data.
To do this, we’re just using the pd.DataFrame function from Pandas.
sales_data = pd.DataFrame({"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
And if we print it out, we can see the dataset.
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
3 Markus South 34000 44000
4 Edward West 42000 38000
5 Thomas West 72000 39000
6 Ethan South 49000 42000
7 Olivia West 55000 60000
8 Arun West 67000 39000
9 Anika East 65000 44000
10 Paulo South 67000 45000
Notice that the DataFrame has four variables: name, region, sales, and expenses.
We’re going to use these variables (and the row index) to subset our data with .query().
EXAMPLE 1: Subset a pandas dataframe based on a numeric variable
Let’s start with a very simple example.
Here, we’re going to subset the data on a numeric variable: sales.
We’re going to retrieve the rows in the DataFrame where sales is greater than 60000.
To do this, we’re simply providing a logical expression inside of the parenthesis: 'sales > 60000'.
Let’s run the code so you can see the output.
sales_data.query('sales > 60000')
OUT:
name region sales expenses
2 Sofia East 90000 50000
5 Thomas West 72000 39000
8 Arun West 67000 39000
9 Anika East 65000 44000
10 Paulo South 67000 45000
Notice that when we run the code, it returns 5 rows. The original DataFrame has 11 rows, but the output has 5.
Moreover, all of the rows of data in the output meet the criteria defined in the logical expression 'sales > 60000'. All of the records have sales greater than 60000.
This is really straightforward. The query method used the expression 'sales > 60000' as a sort of filtering criteria. If the criteria is true for a particular row, that row is included in the output. If the criteria is false for a particular row, it is excluded.
Now notice that in this simple example, we used the greater-than sign to filter on the sales variable. This is one thing to do, but we could also test for equivalence (==), test for greater-than-or-equal, lest-than, etc. Almost any comparison operator will work.
And as you’ll see in upcoming examples, we can combine expressions using logical operators to make more complex expressions.
EXAMPLE 2: Select rows based on a categorical variable
Next, we’re going to select a group of rows by filtering on a categorical variable.
We’re going to retrieve all of the rows where region is equal to East.
To do this, we’re going to call the .query() method using “dot notation.” We simply type the name of our DataFrame, sales_data, and then type the name of the method, .query().
Inside of the parenthesis of the query method, we have a logical expression: 'region == "East"'.
Let’s run the code and take a look at the output.
Here is the code:
sales_data.query('region == "East"')
And here is the output, which is a new dataframe:
name region sales
0 William East 50000
2 Sofia East 90000
9 Anika East 65000
Notice that the output DataFrame contains all of the records for the region East.
A few notes about this.
First, the logical expression is syntactically just a Python logical expression. Here, we’re using the equivalence operator from Python, the double equal sign (==).
Second, the whole logical expression is contained inside of single quotation marks. That is, we provide the logical expression to .query() in the form of a string. Query expects a string.
Third, we’re referencing "East", which is one of the unique values of the region variable. Notice that this value is actually contained inside of double quotation marks. This is because we treat string values of a DataFrame as strings, and as such, it needs to be inside of quotation marks. But since the overall expression is already inside of single quotes, we need to use double quotes for the value "East". If you don’t understand this, you need to review the rules for using quotes inside of quotes with Python.
EXAMPLE 3: Subset a DataFrame by index
Here, we’re going to reference the index of the DataFrame and subset the rows based on that index.
First, let’s just print out the DataFrame.
print(sales_data)
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
3 Markus South 34000 44000
4 Edward West 42000 38000
5 Thomas West 72000 39000
6 Ethan South 49000 42000
7 Olivia West 55000 60000
8 Arun West 67000 39000
9 Anika East 65000 44000
10 Paulo South 67000 45000
Notice that when we print out the DataFrame, each row has an integer associated with it on the left hand side, starting at zero.
This group of numbers is the index. By default, when we create a DataFrame, each row will be given a numeric index value like this (although, there are ways to change the index to something else).
We can reference these index values inside of query.
To do this, just use the word ‘index’.
Here’s an example. Here, we’re going to return the rows where index is less than 3. This will effectively return the first three rows.
sales_data.query('index < 3')
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
Notice that in this output, the index values (on the left side of the printout) are all less than 3.
You can also use mathematical operations inside of your expressions, and this can be a useful technique to subset your data in interesting ways.
For example, we can use the modulo operator (%) on index to retrieve the "odd" rows of our DataFrame:
sales_data.query('index%2 == 1')
OUT:
name region sales expenses
1 Emma North 52000 43000
3 Markus South 34000 44000
5 Thomas West 72000 39000
7 Olivia West 55000 60000
9 Anika East 65000 44000
Using index inside of your expressions for query is a good way of conditionally subsetting on the index.
EXAMPLE 4: Subset a pandas dataframe by comparing two columns
Now, let's make things a little more complicated.
Here, we're going to compare two variables – sales and expenses – and return the rows where sales is less than expenses.
sales_data.query('sales < expenses')
OUT:
name region sales expenses
3 Markus South 34000 44000
7 Olivia West 55000 60000
This is pretty straightforward. Our logical expression, 'sales < expenses', instructs the query method to return rows where sales is less than expenses. And that's what is in the output!
Keep in mind that we can use more than two variable in our expressions, or make the expressions more complicated with logical operators.
I'll show you an example of that in the next example.
EXAMPLE 5: Subset a pandas dataframe with multiple conditions
Here, we're going to subset the DataFrame based on a complex logical expression. The expression is composed of two smaller expressions that are being combined with the and operator.
We're going to return rows where sales is greater than 50000 AND region is either 'East' or 'West'.
Here's the code:
sales_data.query('(sales > 50000) and (region in ["East", "West"])')
And here's the output:
name region sales expenses
2 Sofia East 90000 50000
5 Thomas West 72000 39000
7 Olivia West 55000 60000
8 Arun West 67000 39000
9 Anika East 65000 44000
Notice which rows are actually in the output. The rows all have a region that's either 'East' or 'West'. Additionally, all of the rows have sales greater than 50000.
We did this by creating a compound logical expression using the and operator.
The overall expression inside of query is '(sales > 50000) and (region in ["East", "West"])'.
Notice that there are two parts. The first part is (sales > 50000). The second part is (region in ["East", "West"]). Both of these parts are small expressions themselves that will subset our DataFrame. But here, we're combining them together with the logical 'and' operator. This tells query to return rows where both parts are True.
If you want, you could also use the logical 'or' operator and the logical 'not' operator inside of your expressions. Essentially, you use the Python logical operators to create more complicated expressions and subset your data in more complex ways.
EXAMPLE 6: reference local variables inside of query
Now, let's do something a little different.
So far, we've been referencing variables that are actually inside of the DataFrame. We've been referencing the names of the columns, like sales and expenses.
Now, we're going to reference a variable outside of the dataframe.
Here, we're going to calculate the mean of the sales variable and store it as a separate variable outside of our DataFrame.
sales_mean = sales_data.sales.mean()
And let's take a look at the value:
print(sales_mean)
OUT:
58454.545
This variable, sales_mean, simply holds the value of the mean of our sales variable.
Next, we're going to reference that variable.
To do this, we're going to use the '@' character in front of the variable.
Let's look at the code:
sales_data.query('sales > @sales_mean')
And here is the output:
name region sales expenses
2 Sofia East 90000 50000
5 Thomas West 72000 39000
8 Arun West 67000 39000
9 Anika East 65000 44000
10 Paulo South 67000 45000
Notice that for all of the rows, sales is greater than 58454.545 (the mean of sales).
EXAMPLE 7: Modify a DataFrame in Place
Finally, let's do one more example.
Here, we're going to modify a DataFrame "in place".
That means that we're going to directly modify the DataFrame that we're operating on, instead of producing a new DataFrame.
Now keep in mind: modifying a DataFrame in place can be risky, because we will overwrite our data.
That being the case, I'm actually going to create a duplicate DataFrame first called sales_data_dupe. This way, when we modify the data, we'll overwrite the duplicate and keep our original intact.
sales_data_dupe = sales_data.copy()
Now, let's modify sales_data_dupe.
Here, we're going to select rows where 'index < 5', but we're going to modify the DataFrame directly by setting inplace = True.
sales_data_dupe.query('index < 5', inplace = True)
And let's print out the output:
print(sales_data_dupe)
OUT:
name region sales expenses
0 William East 50000 42000
1 Emma North 52000 43000
2 Sofia East 90000 50000
3 Markus South 34000 44000
4 Edward West 42000 38000
Notice that the rows in sales_data_dupe meet our criteria that the index must be less than 5. Moreover, notice that query modified the DataFrame directly (instead of producing a new DataFrame).
Frequently asked questions about Pandas query
Here are a few frequently asked questions about the Pandas query method.
Frequently asked questions:
What's the advantage of using .query() over brackets
In Python, there are many ways to select rows from a Pandas dataframe.
By far, the most common is to subset by using "bracket notation". Here's an example (note that we're using the DataFrame sales_data created above):
sales_data[sales_data['sales'] > 50000]
This is essentially equivalent to this code using query:
sales_data.query('sales > 50000')
Notice how much cleaner the code is when we use query. It's easier to read. The code looks more like "English" and less like jumbled computer syntax.
In the "bracket" version, we need to repeatedly type the name of the DataFrame. Just to reference a variable, we need to type the name of the DataFrame (i.e., sales_data['sales']).
In the query version though, we just type the name of the column.
Moreover, when we use the Pandas query method, we can use the method in a "chain" of Pandas methods, similar to how you use pipes in R's dplyr.
Ultimately, using the query method is easier to write, easier to read, and more powerful because you can use it in conjunction with other methods.
How does query in Pandas compare to SQL code
If you're coming from an SQL background, you might be trying to figure out how to re-write your SQL queries with Pandas.
If that's the case, you need to know how to translate SQL syntax into Pandas.
So if you were trying to translate SQL into Pandas, how does .query() fit in?
The query method is like a where statement in SQL.
You can use query to specify conditions that your rows must meet in order to be returned.
Leave your other questions in the comments below
Do you have more questions about the Pandas query method?
Leave your question in the comments section below.
Join our course to learn more about Pandas
If you're serious about learning Pandas, you should enroll in our premium Pandas course called Pandas Mastery.
Pandas Mastery will teach you everything you need to know about Pandas, including:
- How to subset your Python data
- Data aggregation with Pandas
- How to reshape your data
- and more ...
Moreover, it will help you completely master the syntax within a few weeks. You'll discover how to become "fluent" in writing Pandas code to manipulate your data.
Find out more here:
Nice tutorial on how to select rows. What would really be helpful is if a second article were written on how to select columns. Nobody does that.
We actually have one …
Check out this tutorial on the Pandas filter method.
That will show you how to select columns.
How do you use the Pandas query to select rows from one dataframe, data2 , based on the values of a column variable in another dataframe, data1, where data2 is a subset of data1
data2 = data1[[‘A’ , ‘B’ , ‘C’ , ‘D’ ]]
data3 = data.query(‘E > N’)
We need all the row from the dataframe data2 where ‘E > N’ and E is a column in data1 but Not in data2