When you’re working with classification and detection systems, you’ll commonly hear the term “False Negative.”
You might be asking, what is a False Negative?
And if you’re a serious machine learning practitioner, how do you fix them?
Well, if you’re asking yourself these questions, you’re in luck.
In this tutorial, I’m going to explain all of the essentials that you need to know about False Negatives. What they are, why they’re important (or dangerous) in classification systems, and how you can fix them.
If you need something specific, just click on any of the following links. The link will take you to the correct section of the blog post.
Table of Contents:
- What are False Negatives
- Why are False Negatives Important in Classification Systems
- How to Fix False Negatives
- Frequently Asked Questions
Having said that, although False Negatives may appear simple on the surface, the subject of FNs and how to deal with them is actually fairly nuanced. Because of that, it might be beneficial to read the whole article from top to bottom.
Ok. Let’s get into it …
What is a False Negative?
Let’s start by explaining what False Negatives are.
In the simplest terms, a False Negative (FN for short) is when an underlying case is actually positive, but a classification system incorrectly predicts that the example is negative.
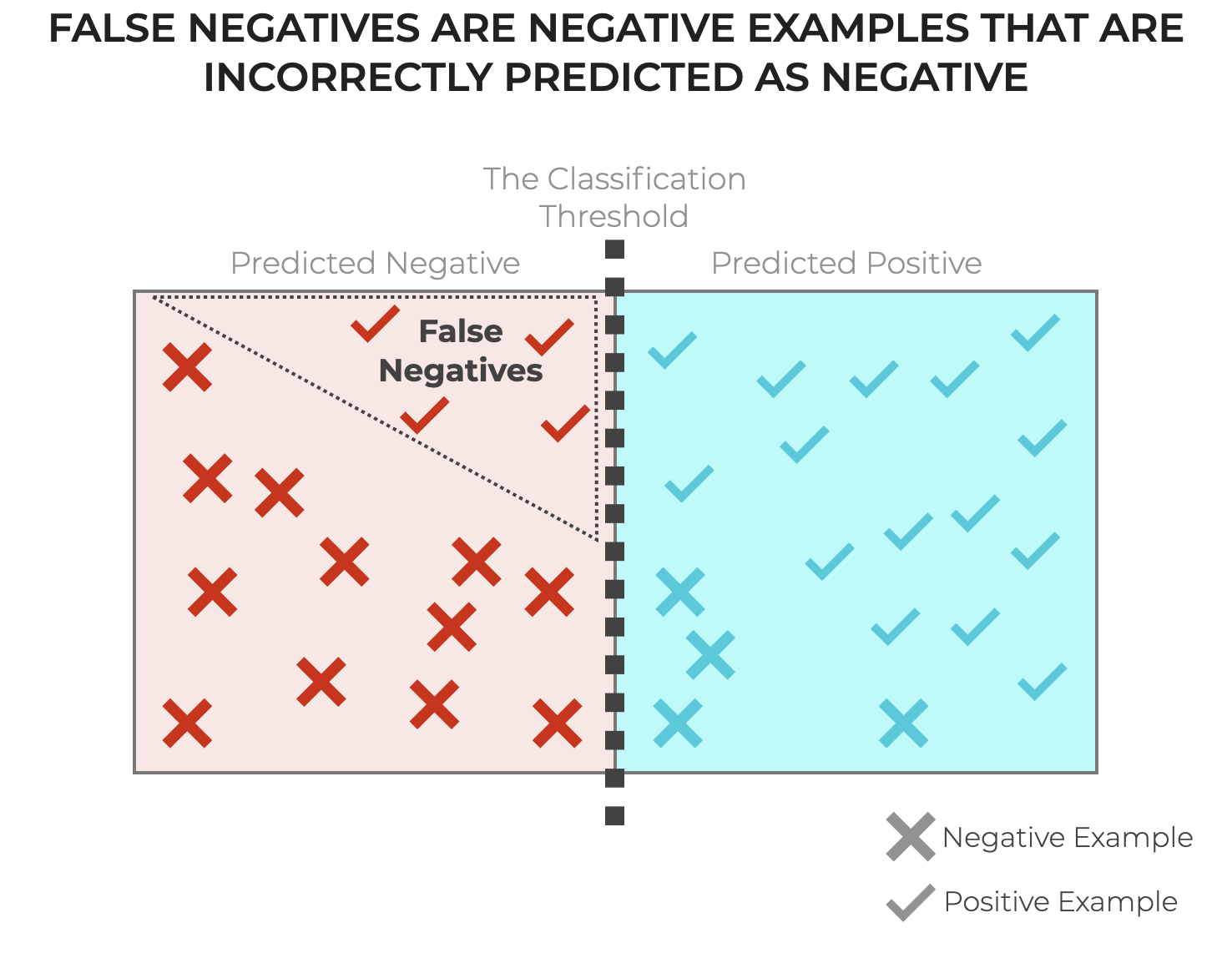
It’s one type of incorrect prediction by a classification system (with the other being False Positives).
To unpack this though, we’re going to quickly review the nature of classification systems. Understanding classifiers will lay the foundation for a more detailed explanation of what FNs are and how to fix them.
Classification Review: Classification Systems Predict Categorical Labels
Here, we’ll quickly review how classifiers (AKA, classification systems) work.
Classifiers (i.e., machine learning classification systems) predict categorical labels.
This is different from and in contrast to regression systems. Regression systems predict numbers.
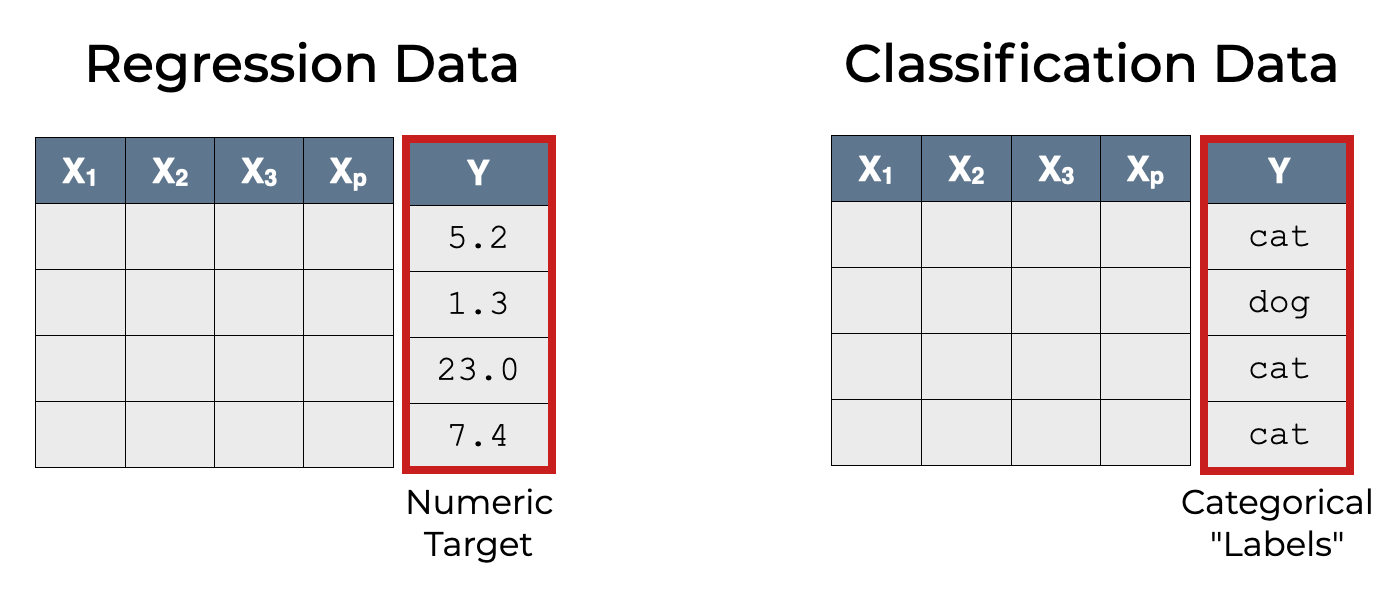
A special case of classification is binary classification, where there are only 2 possible categorical outputs for the classifier.
In binary classification, we commonly see outputs like:
True/FalseYes/No1/0
However, we can simplify all of these binary encodings into something more general.
Positive and Negative are General Binary Labels
Instead of the binary encodings shown above, we can use the general encoding of positive and negative.
Keep in mind that positive and negative don’t mean “good” and “bad”. Rather, they are simply general labels used to encode the possible binary outcomes. As mentioned above, you can think of them more like Yes/No or True/False.
The most important takeaway is that positive and negative are generalized labels that we can use for almost any binary classification task.
To further illustrate how this works, let’s look at a simple example.
Example: Spam Classification
Let’s take the case of a spam classification system.
Almost all modern email services, like Google’s Gmail, use a spam identification system.
You can think of these spam identification systems like binary classifiers that input emails and output a prediction.
So these spam filters classify incoming emails as follows:
- Predict
positiveif the system thinks that the email is “spam”. - Predict
negativeif the system thinks that the email is “not spam”.
It’s a simple but hopefully clear example of how we can use positive and negative to encode the possible outcomes of a binary classifier.
Classifiers Make Different Type of Correct and Incorrect Predictions
Now that I’ve explained the positive/negative encoding system, let’s discuss the types of correct and incorrect predictions that classifiers make. It relates directly to the encoding system we talked about.
And it’s important, because it’s where we finally encounter False Negatives.
Example: Correct and Incorrect Spam classification
Let’s go back to our spam classification system.
Remember: the spam classifier inputs emails, and outputs:
positiveif it thinks that the email is spam.negativeif it thinks that the email is not spam.
This sounds simple, but it get’s slightly more complicated if you remember that all classification systems make mistakes.
For example, imagine that the email is a job offer from a big Tech firm, offering you a highly-paid data science role. BUT, the spam classifier incorrectly flags this email as spam. A terrible mistake. It predicted positive, when the actual value is negative.
In fact, it’s one type of prediction. If we take the 2 possible labels for the actual value, and also the 2 possible labels for the predicted value, then there are 4 possible prediction types.
And each of these prediction types has a name, as follows:
And we can refer to them with names, as follows:
- True Positive: Predict
positivewhen the actual value is positive - True Negative: Predict
negativewhen the actual value is negative - False Positive: Predict
positivewhen the actual value is negative - False Negative: Predict
negativewhen the actual value is positive
So a False Negative is one of the two incorrect predictions, where the system predicts negative but the actual value is positive.
Why are False Negatives so Bad?
Now that I’ve explained what False Negatives are, let’s discuss the reasons that FNs are potentially bad.
Although False Negatives may seem like a minor issue, they can cause significant problems and negative consequences, particularly in some types of circumstances.
At a high level, the major negative impacts of FNs fall into a few categories:
- Impact on Health and Security
- Economic and Resource Implications
- Erosion of Trust
- Missed Opportunities
- Skewed Performance Metrics
Let’s look at each of these separately.
Impact on Health and Security
The impact of False Negatives on health and security could be disastrous.
Imagine a cancer detection system that’s supposed to identify cancer in medical patients. A False Negative would miss the cancer diagnosis, even though cancer was present. This could have fatal consequences for a patient.
Similarly, think of a security system set up to detect intruders. A FN would mean that an intruder is present, but the system predicts that one is not present (i.e., no threat). Again, this could be detrimental to health or personal security.
In these cases, FNs aren’t just abstract statistical errors. They translate into real-world threats to health and personal security.
Economic and Resource Implications
False Negatives can also have economic ramifications.
Consider a classification system designed to identify defects in some product, where positive means “defect” and negative means “no defect.” A False Negative would mean that a defect is actually present, but the system predicted negative, or, no defect. By missing a defect in the product, the FN could cause a situation where defective products are shipped to customers. This could in turn lead to expensive recalls, legal issues, and brand damage.
Alternatively, consider a cybersecurity threat detection system at a large bank. In this case, a FN would mean that the system predicts “no threat” when a threat is actually present. This could cause financial damage to the bank in question (not to mention reputational damage). And if there were a large scale cybersecurity attack (for example, one launched by a nation state), a FN could cause large-scale economic damage.
Erosion of Trust
Repeated instances of False Negatives can erode trust in a classification or detection system.
For example, imagine a medical diagnostic system (like the cancer detection system discussed above) that regularly produces FNs, that is, it regularly predicts “no cancer” when cancer is actually present. This would erode the trust of medical providers using the system, and potentially patient trust, if the information about FNs became public knowledge.
In a more public sphere, imagine a public extreme weather detection system, like a tornado detection system. A False Negative would mean that the system misses the presence or likelihood of a tornado. Repeated FNs could damage public trust in this system, as the public would come to believe that the detection system is incapable of properly identifying threats.
Missed Opportunities
False Negatives are not just about missing potential threats. An FN could mean a missed opportunity.
Consider a system designed to identify potential customers for a high-value product. A FN would mean that the person is in fact a good potential customer, but the system predicts that they are not suitable. This would represent a missed opportunity.
If such a system was being used for a very profitable product, or it was being used to classify a very large customer base, a large proportion of FNs could mean large missed opportunities, in the form of missed revenue or profit.
Skewed Performance Metrics
Perhaps the most important problem with False Negatives for machine learning specifically, is how FNs distort other performance metrics.
False Negatives are included in the calculation of several other machine learning metrics and diagnostic tools, such as:
An increase in False Negatives will decrease these metrics and otherwise diminish classification performance.
Having said that, the importance of the impact that FNs have on these metrics will depend on context.
In some tasks, we will prioritize recall (where False Negatives will have a direct impact) instead of precision (FNs are not included in the calculation of precision). Still in other cases, we may optimize for F1-score, and False Negatives impact F1 differently than precision or recall.
So the effects of FNs, both directly or indirectly on other performance metrics will depend on the the problem we’re trying to solve, the goal(s) of the system, and the importance of those metrics to the task.
Keep in mind also that the topic of classification performance metrics is a big one, and for the sake of brevity, I’m limiting my discussion of classification metrics somewhat. I’ll write more about these other classification metrics in separate articles.
How to Deal With False Negatives
As we’ve just discussed, False Negatives can have terrible consequences in the real-world, including economic and financial harm, threats to health and security, and loss of trust.
So in many cases, we want to limit False Negatives (although, again, whether or not limiting FNs is a priority depends on circumstances and task).
All that said, in this section, I’m going to review 7 ways to mitigate or fix False Negatives:
- Reassess Feature Selection and Engineering
- Adjust Classification Thresholds
- Resampling and Data Augmentation
- Algorithm Selection
- Ensemble Methods
- Cost-sensitive Learning
- Post-processing and Expert Review
Let’s review each of these, one at a time.
Reassess Feature Selection and Engineering
One of the most common ways to fix False Negatives is to change or transform the features that we use. This falls into two broad categories: feature selection and feature engineering.
Feature Selection
The features that we decide to use in a model have a big impact on the performance of a model and the quality of the output.
And among the features that we do decide to use, some features are more important than others for model performance.
Additionally, if we use features that are unimportant (i.e., irrelevant, redundant, uninformative), then these features can actually degrade model performance, which could increase False Negatives specifically.
So whenever we build a model, we need to use good feature selection methods to select the best features, and exclude irrelevant or uninformative features.
Feature Engineering
In addition to selecting existing features, we also sometimes need to create new ones.
We can create new features by transforming the existing features (i.e., normalizing the features, using a polynomial transformation on a numeric feature, etc). We can also use dimension reduction techniques to create new features that are mathematical combinations of the old ones.
Good feature engineering can improve classifier performance generally, and reduce FNs specifically.
Keep in mind that feature selection and engineering are very big topics, and I’m necessarily leaving out many of the details. I’ll write more about these subjects in separate blog posts.
Adjust Classification Thresholds
As I’ve written about elsewhere, the number of False Negatives and related metrics depends on the classification threshold.
To quickly review, many classification models use a classification threshold as a cutoff to decide if a particular example should receive a label of positive or negative. In classification systems that work this way, the classifier produces a probability score that encodes the confidence that the model has that the example belongs to the positive class.
If the probability score is above the threshold, the example get the positive label. If the probability score is less than or equal to the threshold, the example gets the negative label.
To be clear, some classification model types work differently and don’t have a threshold. But many classification algorithms do operate this way, so it’s important to understand classification thresholds and their effects on FNs.
There are a few important points to understand with respect to thresholds:
First, you can change the threshold. As a machine learning engineer, you have a choice about where to place the classification threshold. By default, many binary classifiers set the threshold at .5. What that means is that if the classifier has a confidence of .5 or greater that the example is positive, then the classifier will predict the positive label, else the negative label. (Note that multiclass classifiers may set the default differently.)
But, you can move the threshold.
And moving the threshold will change the number of False Negatives and related metrics.
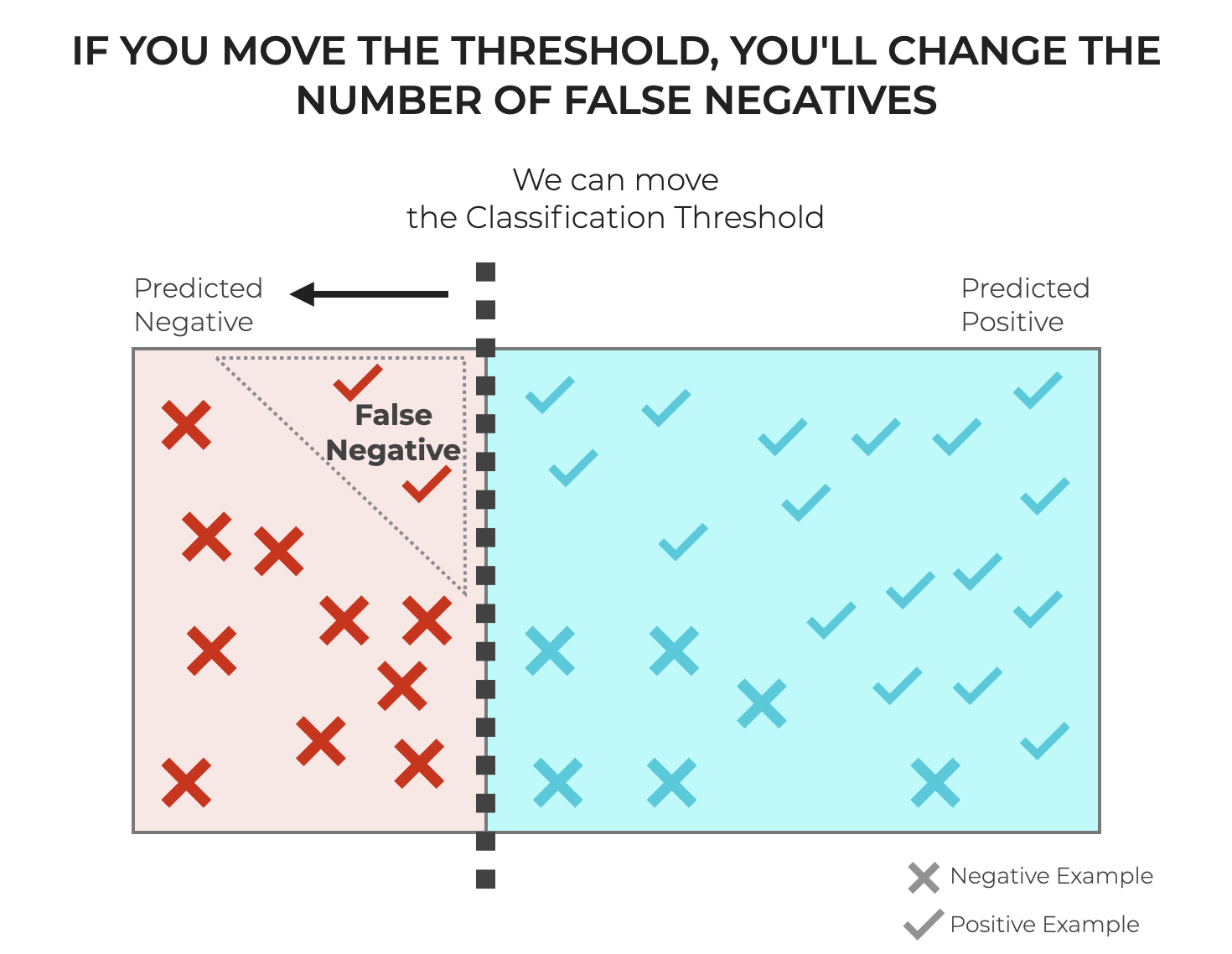
Importantly, if you decrease the threshold, it will decrease the number of False Negatives.
BUT, there’s actually a tradeoff. Decreasing the threshold will decrease the number of False Negatives, but it will simultaneously increase the number of False Positives as well.
So, you can adjust the threshold to decrease FNs, but it may come at the expense of FPs.
(Remember though: adjusting the threshold is generally relevant for probabilistic classifiers that output a probability score for each class.)
Resampling and Data Augmentation
A class imbalance in your dataset could lead to an increase in False Negatives.
In particular, if the negative class is over represented (i.e., if there are more negative examples than positive examples), then a classification built on this data might produce more FNs.
One way to fix such a class imbalance is to oversample the positive examples or to undersample the negative examples. Doing this could even out the classes in the data.
You can also try to use some type of synthetic data generation to add balance to the examples. For example, you can use a technique like Synthetic Minority Over-sampling Technique SMOTE to generate new, synthetic examples inside the feature space of the existing data. To fix the problem of too many False Negatives, you could use synthetic data generation to create more positive examples to balance out the data.
Having said that, synthetic data generation can introduce new problems, so you need to be careful if you use this technique. Due to the complexities of its application, I’ll write about this subject in more detail in a future blog post.
Algorithm Selection
If one particular algorithm or model type is producing too many False Negatives, you can also try a different algorithm.
Different machine learning model types can be more or less susceptible to FNs.
So if your model is producing too many FNs, then you may want to experiment with other algorithms to build your model, such as logistic regression, decision trees, random forests, neural networks, etc.
Ensemble Methods
Similar to the advice in the previous section, instead of simply choosing any type of algorithm, you may want to choose an ensemble method.
Ensemble methods work by building multiple models, and then they combine those models together to create an “ensemble”. Ensemble methods aim to leverage the strengths and mitigate the weaknesses of individual models. That being the case, they often perform better, and are more robust against False Negatives and False Positives.
For example, Random Forests and Boosted Trees tend to have better predictive performance than single decision trees. And they tend to produce fewer False Negatives.
So if your model is producing too many FNs, you may want to experiment with an ensemble method and see if it works better for your particular goals.
Expert Review and Model Feedback
You might also want to introduce a step where an expert or panel of experts review the individual predictions, which would allow them to catch unwanted False Negatives. Although this type of expert review might not scale with systems that need to make a large number of predictions, it can work well for systems with fewer predictions, and where the predictions are high-impact (like a cancer diagnosis system).
Similarly, you may want to introduce mechanisms that allow users to give feedback to the system, and indicate whether or not the prediction was accurate. This feedback can be used as additional input to fine-tune the performance of the model. Ideally, this feedback will help to reduce the number of False Negatives over time.
Final Thoughts on Dealing with False Negatives
False Negatives can be a big problem for classification systems.
And although there are many possible ways to reduce FNs (as discussed above), these techniques can be complicated to execute, and they often involve tradeoffs. Using one technique to reduce FNs may degrade the model’s performance in another way, or introduce additional complexities or costs.
That being the case, each of the above methods for dealing with False Negatives deserves a more detailed explanation, so I’ll write more about them in the future.
Additional Reading
Although it’s often important to diagnose and decrease the number of False Negatives that a model produces, as I’ve mentioned, doing so can often impact other aspects of a model’s performance.
That being the case, you should understand the relationship that FNs have to other classification metrics and concepts, such as:
False Negatives and the methods of dealing with them can impact all of these aspects of model performance, either directly or indirectly.
Do you have other questions?
Is there something that I’ve missed?
Do you still have questions about False Negatives?
I want to hear from you.
Leave your questions in the comments section at the bottom of the page.
For more machine learning tutorials, sign up for our email list
In this tutorial, I’ve explained False Negatives and how they relate to classification systems.
But if you want to master machine learning in Python, there’s a lot more to learn.
That said, if you want to master machine learning, then sign up for our email list.
When you sign up, you’ll get free tutorials on:
- Machine learning
- Deep learning
- Scikit learn
- … as well as tutorials about Numpy, Pandas, Seaborn, and more
We publish tutorials for FREE every week, and when you sign up for our email list, they’ll be delivered directly to your inbox.