Machine learning – and the related field of AI – will probably be worth millions of dollars for people who master these skills.
But as I always tell my students: to master ML and AI, you need to master the basics.
And part of “the basics” are evaluation metrics …
… like classifier recall.
This blog post will explain all of the essentials that you need to know about recall.
It will explain what recall is, the pros and cons of this metric, how to improve recall, and more.
Table of Contents:
- A Quick Review of Classification
- Recall Basics
- Pros and Cons of Recall
- How to Improve Recall
- Alternatives to Recall
If you need something specific, you can click on any of the links above.
But this concept will probably make more sense if you read the whole article.
Ok, let’s jump in.
A Quick Review of Classification
I know that you’re ready to learn about the oh-so-cool topic of “classifier recall,” but in order to understand recall, you need to know how classification works generally.
So, we’re going to quickly review machine learning classification systems. In particular, we’re going to review how they work, and the types of predictions that they make (I promise, this is highly relevant to the topic of recall … you need to read this).
Once we (briefly) review classification, we’ll quickly move on to a proper discussion of recall.
Machine Learning Overview
First, I want to briefly explain machine learning generally.
Machine learning, is a field devoted to building computer systems that improve performance on a task as we expose them to data.
Machine learning systems learn without explicit instructions from a human about how to operate.
They simply input data and “learn” algorithmically how to solve the problem.
(Notice as well that in the definition above, I mentioned that they “improve performance.” This assumes that we measure their performance, which directly relates to recall. More on that later.)
What is Classification
Within the broad topic of machine learning, there are different types of machine learning systems that do different things.
And one of the main types of ML systems are classifiers (i.e., classification systems).
Classifiers learn how to classify input examples by giving them a categorical label.
So when we train a classifier, we feed the algorithm input examples, and the classifier learns predict a categorical label for every example like positive/negative, cat/dog, spam/not spam, etc.
After we train the classifier, we can use the classifier to predict the correct label for new, previously unseen data examples that don’t already have labels.
To better understand this, let’s take a look at a simple classifier.
(I’ll explain recall soon after that, I promise.)
A quick example of classification
One example that I like to use to explain how classification systems work is what I call “The Cat Detector.”
The Cat Detector is a simple classifier.
The Cat Detector accepts pictures as inputs.
And the Cat Detector predicts a label as an output. It only has 2 possible output labels:
Positiveif the image is a cat.Negativeif the image is not a cat.
That’s it.
It’s a simple binary classifier. It accepts a picture as an input, and it outputs positive or negative to indicate if it thinks that the image is a cat or not a cat.
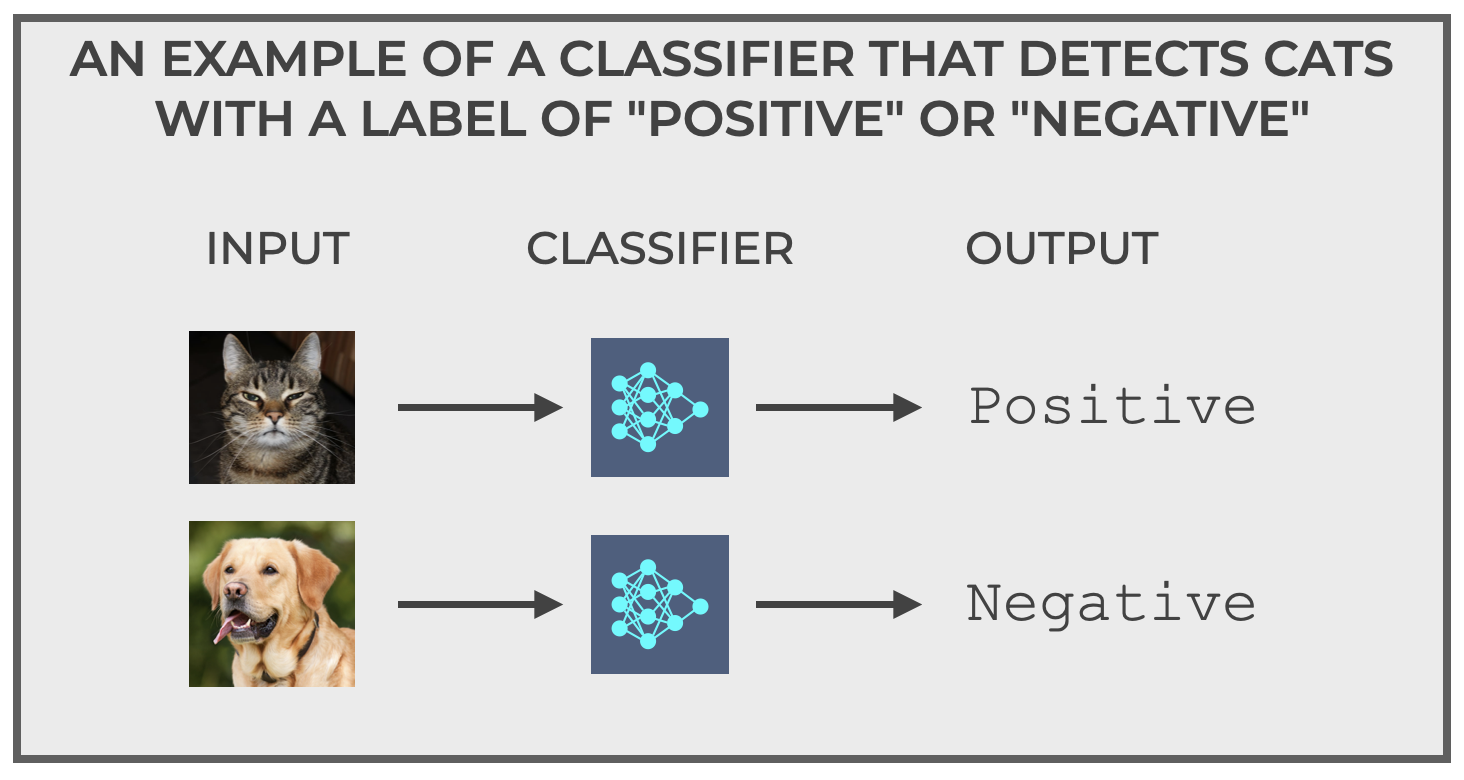
It seems pretty straightforward in how it works.
But … well.
Sometimes it’s a little more complicated.
Classification Mistakes
The main issue that you need to keep in mind is that classification systems make mistakes (unless the problem is trivially easy).
Said differently, classifiers sometimes predict the wrong label for an example.
To illustrate this issue, let’s go back and think about our Cat Detector.
If the Cat Detector was working perfectly, then you’d feed it an input image of a cat and it would (correctly) output the label positive (meaning that it thinks the input image is indeed, a cat).
And if you feed it an input image that’s not a cat (like an image of a dog), then the Cat Detector should output negative, meaning that it thinks the image is not a cat.
But that’s what should happen if the classifier works perfectly, and perfect prediction is almost impossible in real-world problems.
What that means is that for most real-world problems of any difficulty, the classifier will sometimes output the wrong class label.
For example, the Cat Detector system could input the image of an actual cat but output negative.
Or, the system could input the image of a non-cat but output positive.
Both of those prediction types are incorrect (and there are names for these types of incorrect predictions, which we’ll get to in a moment).
So for our Cat Detector – a type of binary classifier – there are actually 4 different predictions that can happen, based on the actual value of the input (cat or not cat) and the output of the classifier (positive or negative).
This image summarizes those possibilities:
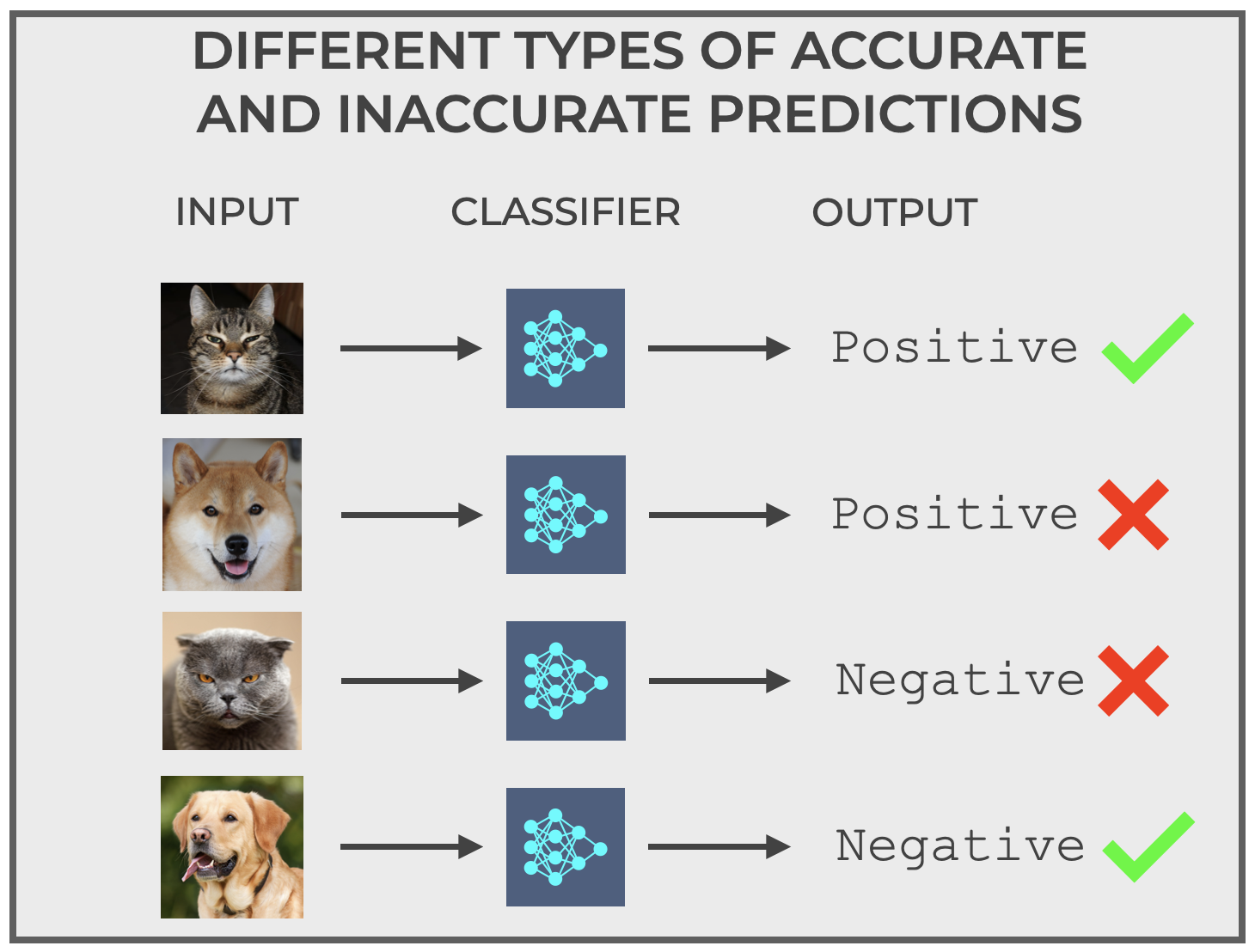
These types of correct and incorrect predictions are at the core of classifier evaluation.
And for the purposes of this blog post, they’re also at the core of classifier recall.
We’re almost at the point of the article where I explicitly explain what recall is, but first, let’s talk a little more precisely about the correct and incorrect predictions that I just described above, because you need to understand them to understand recall.
Correct and Incorrect Prediction Types
As I mentioned above, there are four types of prediction for a binary classifier.
Specifically, for our Cat Detector above, they are:
- Correctly predict
positivewhen the input is actually a cat - Correctly predict
negativewhen the input is not a cat - Incorrectly predict
positivewhen the input is not a cat - Incorrectly predict
negativewhen the input is actually a cat
But if we generalize the possible labels as positive and negative, we can generalize these prediction types in a way that they will apply to any binary classifier:
- True Positive: Predict
positivewhen the actual input is positive - True Negative: Predict
negativewhen the actual input is negative - False Positive: Predict
positivewhen the actual input is negative - False Negative: Predict
negativewhen the actual input is positive
Notice that each of these prediction types has a name (True Positive, True Negative, False Positive, and False Negative).
Now, you might be asking, “Why is Josh explaining this?”
Because, these prediction types (which are collectively the elements of a confusion matrix), are critical for calculating and understanding classification recall.
Ok. You’re ready.
Recall Basics
Now that we’ve reviewed how classifiers work, and now that we’ve talked about the types of correct and incorrect predictions that classifiers make, we’re ready to talk about recall.
To put it simply: recall is the number of True Positive predictions, divided by the total number of actual positive examples.
We can quantify recall like this:
(1) 
So recall is the number of True Positive predictions divided by True Positives plus False Negatives.
(2) 
Remember that in a False Negative, the actual input example is positive, but the classifier incorrectly predicts negative.
So for both a True Positive and a False Negative, the example is actually a positive case. In the True Positives, the classifier correctly predicts the positive example as positive, but in the False Positives, the classifier incorrectly predicts the positive example as negative.
Thus, the denominator of the recall equation contains all of the actual positive examples, both those that were correctly classified by the classifier (True Positives) and those that were incorrectly classified by the predictor (False Negatives).
To help you understand, we can visualize these True Positives and False Negatives, as well as the recall equation as follows:

Do you understand now why we needed to review all that material about True Positives, False Negatives, and classification types?
THIS is why.
Because recall depends on those quantities.
Ultimately though, as you can see, recall tells us the proportion of all positive examples were predicted as positive. (Remember that a True Positive is a correct prediction of a positive example, and a False Negative is an incorrect prediction of a positive example.)
An Example of Classifier Recall
To illustrate how we calculate recall, let’s look at an example.
We can assume that we’re using the Cat Detector classifier that I explained above.
Once the model is trained, let’s assume that we’re going to evaluate the model.
To do this, we’ll feed it 100 input photos (AKA, “examples”). Among these 100 examples are 50 pictures of cats and 50 pictures of dogs.
And upon feeding these inputs to the Cat Detector, the system produces the following predictions:
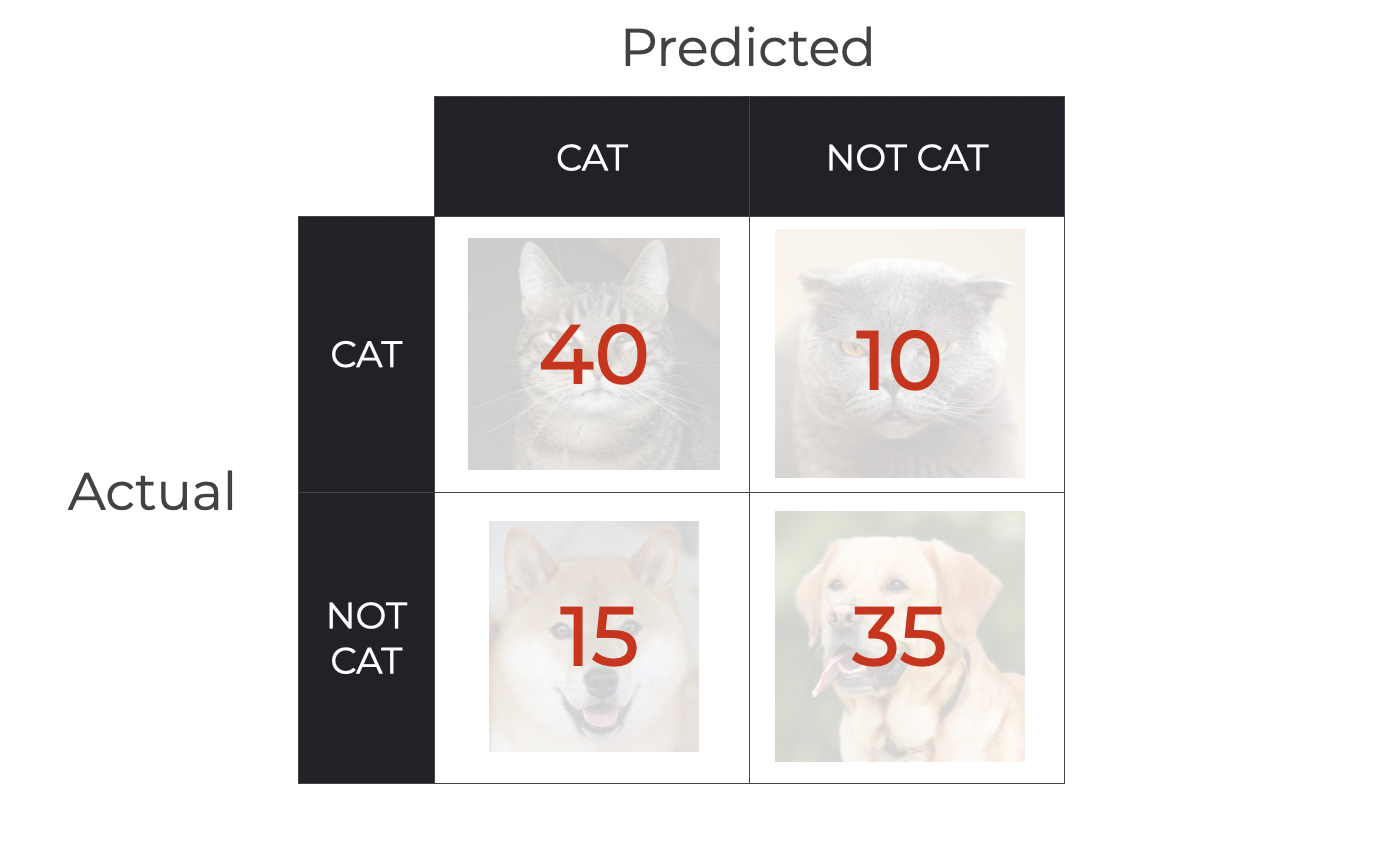
So, we have the following predictions:
- 40 True Positives (pictures of cats predicted as cat)
- 35 True Negatives (pictures of non-cats predicted as not cat)
- 15 False Positives (pictures of non-cats predicted as cats)
- 10 False Negatives (pictures of cats predicted as not cat)
Using these quantities – and in particular the number of True Positives and False Negatives – we can calculate recall.
Calculating Recall with TP, TN, FP, and FN
Given the numbers above numbers, let’s calculate the recall of our classifier.
Remember: recall is the number of True Positives divided by the number of True Positives plus False Negatives.
Therefore, using the numbers for TPs and FNs above, we can calculate the recall as follows:
(3) 
So the recall of our Cat Detector system is .8.
The Pros and Cons of Classification Recall
As we’ve just seen in our example, it’s fairly easy to calculate recall. Due in part to its simplicity, recall is a very commonly used classification evaluation metric.
BUT, recall does have strengths and weaknesses.
You need to understand those strengths and weaknesses so you know when it’s appropriate to use recall, and when it’s inappropriate.
That being said, let’s look at some of the pros and cons of using recall.
The Pros of Recall
There are a few pros of using recall, but here, we’ll focus on three:
Emphasis on Minimizing False Negatives
Recall is particularly useful in situations where incorrectly classifying a positive example (i.e., classifying a positive example as negative) has strongly negative consequences.
For example: a situation where you’re using a system to identify cases of a serious medical disease.
In situations like these, you want to minimize False Negatives. That’s largely what recall helps you do.
Works Well on Imbalanced Data
Recall is often better than accuracy when you have a so-called “imbalanced dataset.” I.e., when you have a dataset with a class imbalance between positive and negative classes.
In particular, recall is helpful when you’re trying to identify the positive class, and the positive class is rare. That’s because (as I explained previously), recall measures the proportion of positive examples that were correctly classified.
So if the positive class is rare and important, recall is often a useful metric.
Important for High-Stake Decisions
In cases where the cost of a false negative is high (like some applications in healthcare, finance, etc), recall provides a measure of how many actual positive instances were missed. This is often critical for improving a classifier in these types of situations.
The Cons of Recall
Although recall is useful in some types of situations, recall also has weaknesses as a classification metric.
Let’s look at the cons of recall.
Vulnerable to False Positives
High recall doesn’t always indicate a “good” model, since high recall can come at the cost of a large number of False Positives.
This can be a problem in situations where False Positives have substantial costs or negative consequences.
Often Needs to be Used with Other Metrics
Relying only on recall often provides an incomplete picture of a model’s performance. Recall typically needs to be balanced with other metrics like precision, since focusing strictly on recall can lead to a classifier that simply predicts every example as positive.
How to Improve Recall
There are a variety of ways to improve recall, and most of them are things that we would do to improve model performance generally.
At a high level, you can improve recall with:
- Better data preprocessing
- Good feature selection and engineering
- Choosing a good machine learning algorithm (e.g., choosing a decision tree vs logistic regression, etc)
- Hyperparameter tuning
- Tuning the classification threshold
And more.
Improving model performance generally, and improving recall specifically, is a pretty big topic, so I’ll write more about it in future blog posts.
Alternatives to Recall
As I noted previously, recall is just one classification metric among many that you can use to evaluate the performance of a classifier.
And as I also mentioned, some classification metrics work better than others for some situations.
That being the case, you need to know the full range of classification metrics, like:
… and others.
You should be able to click on any of the above links for more info on those metrics.
Wrapping Up …
Recall is an important metric that we use for for evaluating classifiers. It’s also one of the most common machine learning metrics, so you need to understand it.
Having said that, recall has strengths and weaknesses. You need to learn the limitations of recall, and also the cases when it’s best to use it, how to improve it, etc.
Hopefully, this tutorial gave you a good overview of recall. And I hope that it improved your knowledge of how to evaluate machine learning systems.
Leave Your Questions and Comments Below
Do you have other questions about recall?
Are you still confused about something, or want to learn something else about recall that I didn’t cover?
I want to hear from you.
Leave your questions and comments in the comments section at the bottom of the page.
Sign up for our email list
If you want to learn more about machine learning, then sign up for our email list.
Every week, we publish free long-form tutorials about a variety of data science topics, including:
- Scikit Learn
- Numpy
- Pandas
- Machine Learning
- Deep Learning
- … and more
If you sign up for our email list, then we’ll deliver those free tutorials to you, direct to your inbox.
There is a typo in the denominator of recall. The expression reflects precision.
Thank you. I fixed it.