If you want to master building classification systems for machine learning, you need to understand how to evaluate classifiers.
And in turn, that means you need to understand classification metrics.
In classification there are a wide variety of metrics, like precision, recall, sensitivity, accuracy, and many others, but most of these metrics are actually based on a few very simple metrics: False Positive, False Negative, True Positive, and True Negative.
And with that in mind, in this post, I’m going to focus entirely on True Negatives.
I’m going to explain what True Negatives are, how they’re used in classification evaluation, and also introduce you to a few issues around measuring True Negatives.
If you need something specific, you can click on any of the following links. The link will take you to the appropriate section of the tutorial.
Table of Contents:
- What are True Negatives
- Why are True Negatives Important in Classification
- Pitfalls, Caveats, and Other Considerations
- Frequently Asked Questions
But keep in mind that this is largely a conceptual article, and one part really builds on the next. It’s probably best if you read the whole thing.
With that said, let’s start learning about True Negatives.
What is a True Negative?
In simplest terms, a True Negative is when an example is actually a “negative” example, and a classification system correctly predicts the negative class.
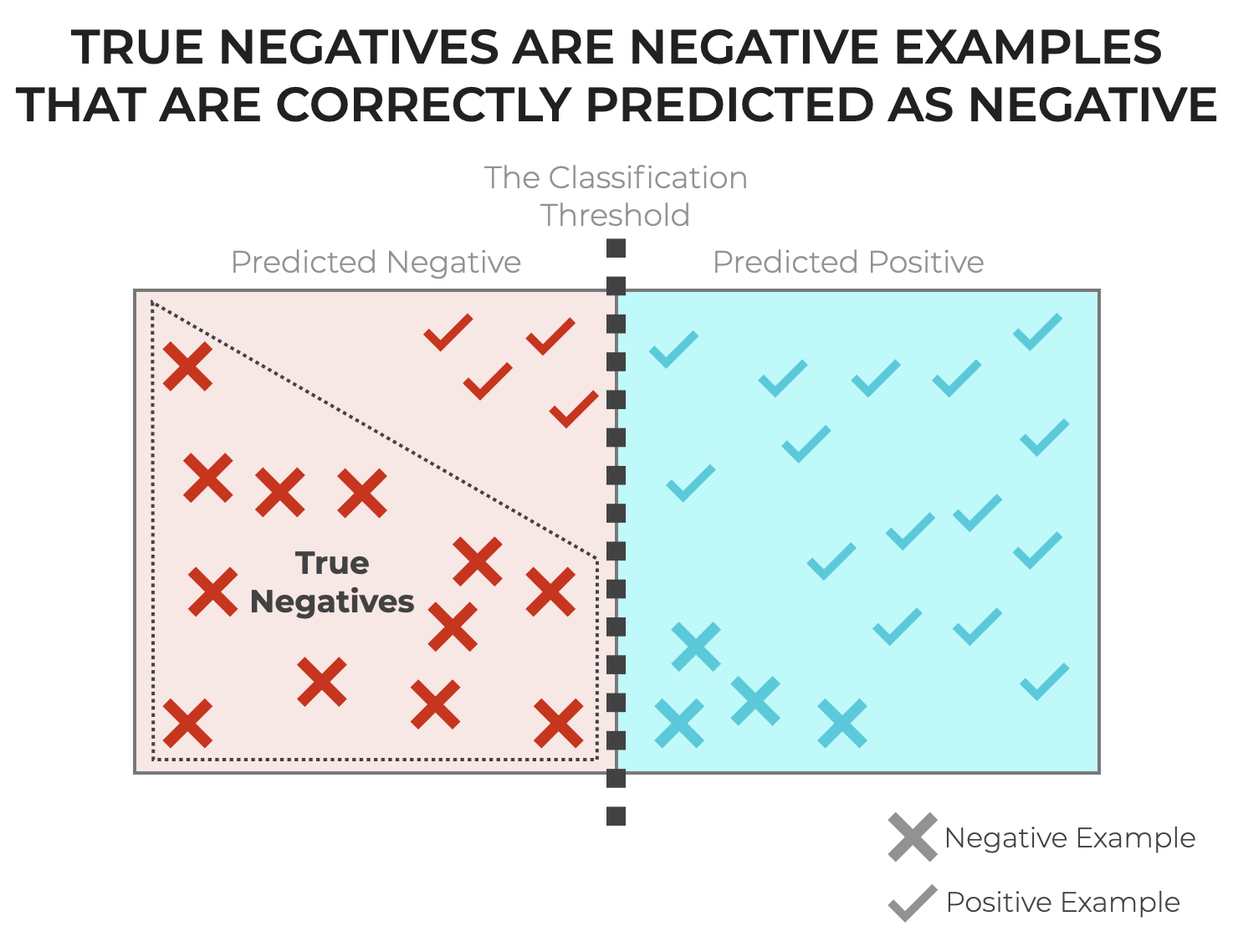
It’s possible that you’re a little unfamiliar with some of these terms though, so let’s quickly review classification so I can explain True Negatives in slightly clearer and more concrete terms.
Classification Review: Classification Systems Predict Categories
Let’s quickly review the basics of classification.
Classification systems – sometimes called “classifiers” – are machine learning prediction systems that predict categories.
In contrast to regression systems, which produce numbers as predicted outputs …
Classifiers predict categorical labels.
Let’s take the simplest case and discuss binary classification.
Binary Classification Labels
In binary classification, which is the simplest and most common type of classification problem, we only have two possible outcomes.
The exact encoding of these outcomes depends on the task, but common binary encodings are things like:
1and0TrueandFalseSpamandNot Spam(for example, in an email “spam” classification task)CancerandNot Cancer(for example, in a medical diagnostics task)
But ultimately, we can simplify all of these different specific encodings to a generalized encoding that includes them all.
Positive and Negative as a General Binary Encoding
We can generalize all of the above encodings into the following scheme: positive and negative.
Example: Spam Classification
To illustrate how this encoding works, let’s quickly think of a spam classification task.
Think of your email system, like Google’s Gmail or something similar.
Almost all of these email systems have a spam filter.
The purpose of the spam filter is to filter out junk emails … commonly referred to as “spam”.
These spam email detectors are literally classification systems. For example, Google has been using machine learning classification to detect spam for well over a decade.
In such a classification system, instead of using the encoding Spam and Not Spam, we can encode the possible outcomes as follows:
Positiveif the system thinks that the email is “spam”.Negativeif the system thinks that the email is “not spam”.
This is just one example, but it shows how we can encode binary labels for a binary classifier as positive and negative.
Classifiers Make Different Type of Correct and Incorrect Predictions
Now that we’ve discussed our generalized binary encoding, let’s talk about the different types of incorrect predictions that a classifier can make.
This is important, because it’s where we start getting to the concept of True Negatives.
Imagine a system that classifies images. The sole purpose of the system is identify images of cats. We’ll call it, The Cat Detector.
This system accepts images as inputs, and only produces one of two outputs. It will:
- Predict
positiveif it thinks that the image is a cat. - Predict
negativeif it thinks that the image is not a cat.
Pretty simple, right?
Not so fast.
Classification systems, like all predictive machine learning systems, make mistakes.
For example, it could be possible for our Cat Detector to input an actual image of a cat, but incorrectly predict negative.
In fact, we consider the actual image types (cat or not cat) and the possible predicted labels (positive and negative), then we can identify 4 possible types of correct and incorrect predictions:
- True Positive: Predict
positivewhen the actual value is positive (an image of a cat) - True Negative: Predict
negativewhen the actual value is negative (not an image of a cat) - False Positive: Predict
positivewhen the actual value is negative (not an image of a cat) - False Negative: Predict
negativewhen the actual value is positive (an image of a cat)
True Negative is one of the 4 prediction types, and it’s one of the 2 correct predictions (the other being True Positive).
A True Negative is simply when the classifier predicts negative, and the actual ground truth value is negative.
Why are True Negatives Important?
Now that we know what True Negatives are, let’s discuss why they’re important.
I think there are a few reasons to know TNs, but these are probably the main reasons:
- They directly measure the ability of a classifier to identify negative cases.
- It’s the basis for other classification metrics and evaluation tools.
- We can use it to evaluate and optimize classifier performance.
Let’s discuss each of these areas separately.
Measure the Ability of a Classifier to Identify Negative Cases
First, True Negatives directly measure the ability of a classification system to correctly identify negative examples.
This is often not only one of the main considerations for a classification system, and it may be of primary importance, depending on the problem we’re trying to solve.
Example: Detecting a rare but costly-to-treat disease
Let’s imagine a scenario where there’s a rare disease. We’ll call it Aurelian Disease.
This disease is rare and treatable, but very costly to treat. It will require a large amount of money, but the person would also need to be quarantined for several months. So the treatment would require a person diagnosed with this disease to leave their job, and spend a large amount of money on treatment. Let’s also say that this hypothetical disease would be contagious, and there would be a public interest in treating it.
In such a scenario, we would want to correctly identify the True Negatives.
Why?
If a person actually did not have Aurelian Disease, we would want to correctly classify that case as negative, because incorrectly diagnosing the case as positive would have high costs.
Furthermore, there might be other abstract costs for misdiagnosis, like psychological suffering for the patient (who would need to be quarantined), and potentially a loss of public trust in health authorities if there were too many False Positives (a person who did not have Aurelian Disease, but was incorrectly classified as positive).
There would be a strong need to correctly classify negative cases as negative.
But, there’s a tradeoff ….
Having said that, there’s always a tradeoff between detection of True Negatives and avoidance of False Positives.
We’ll discuss that more later in this blog post.
True Negatives are the Basis for Other Classification Metrics and Evaluation Tools
The number of True Negatives is not just useful by itself as a classification evaluation metric.
True Negatives are also involved in the calculation of several other classification metrics, such as:
- Accuracy
- F1-score
- True Negative Rate (which is synonymous with specificity)
- ROC Curves
- Confusion Matrices
Although you’re not going to be computing these metrics by hand yourself, you’ll need to know how they’re computed and what they represent.
And they all include True Negatives in one way or another.
Model Optimization
Ultimately, we need to understand True Negatives in order to optimize our classification models.
There are instances where we will need to optimize a classifier strongly for detection of True Negatives.
But as I’ve suggested already, even if True Negatives aren’t the primary concern, almost all model optimization will take True Negatives into account in one way or another.
So if you want to learn how to build great classification systems (and let’s be honest you should, since there will be enormous amounts of money in it), then you need to understand True Negatives and how the metrics related to TNs enable you to optimize your classifiers.
Pitfalls, Caveats and Other Considerations
Although we often need to compute True Negatives and related metrics to evaluate the performance of a classification system, there are several potential pitfalls and other considerations that we need to consider as well.
Here are a few extra things to consider alongside True Negatives.
True Negatives often Depend on Classification Threshold
For most classification systems, True Negatives are not perfectly constant, but rather, they vary depending on how you build your classifiers.
More specifically, True Negatives often depend on what’s called the classification threshold.
As I’ve written about elsewhere, a classification threshold is like a cutoff point for predicting a particular example as “positive”.
Most classification systems produce a probability score that acts like the confidence of classifier that a particular example is “positive“.
If the probability score is above the threshold, the example gets the label positive.
If the probability score is below or equal to the threshold, the example gets the label negative.
So for classifiers that operate this way, the number of positive examples and negative examples depends on the threshold.
And, you can typically change the threshold.
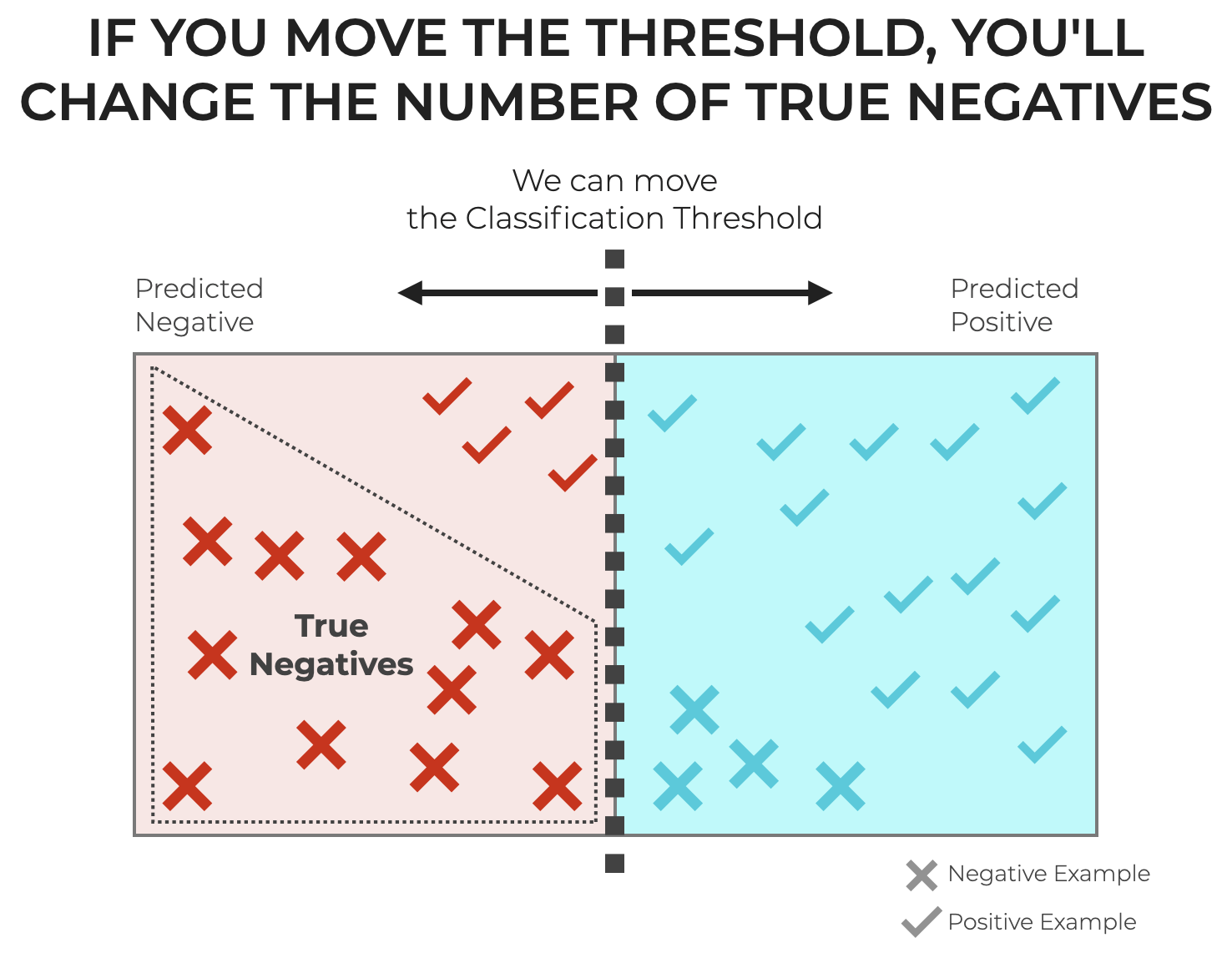
This has a variety of consequences, but one of the big things is that it will change the number of True Negatives and True Positives.
So, you need to be aware of how your choice of threshold will impact the number of True Negatives produced by a particular model.
True Negatives Must Be Viewed Along With False Negatives
We also need to view True Negatives along with the related metrics, like False Negatives.
As noted above, as we move the classification threshold for a classification model we will change the number of True Negatives.
As we increase the threshold, we’ll get more True Negatives.
As we decrease the threshold, we’ll get fewer True negatives.
But it will also change False Negatives and False Positives.
For example:
- Increasing the threshold typically results in more True Negatives and False Negatives, but fewer False Positives and True Positives.
- Decreasing the threshold tends to reduce the number of True Negatives and False Negatives, while increasing True Positives and False Positives.
There’s always a tradeoff between the number of True Negatives and False negatives.
When we build a classifier, we always need to be mindful of that tradeoff.
Overemphasis Can Be Harmful
Building on the previous discussion about the tradeoff between True Negatives and other metrics, you need to keep in mind that overemphasis of detecting True Negatives can be harmful.
The reason is that if you optimize strictly for True Negatives, you’ll also likely get more False Negatives. And at the same time, you might also get fewer True Positives.
In some circumstances, this could have very harmful or costly consequences.
For example, in a medical diagnostics task, overemphasizing detection of True Negatives might also increase False Negatives, causing the classification system to miss the presence of a life-threatening disease.
True Negatives May Be Overrepresented if the Data Are Skewed
Another consideration that may affect True Negatives is an imbalanced dataset.
Imbalanced data is when the target classes are unequal. There may be a much higher proportion of positives or a much higher proportion of negatives, instead of a close to 50/50 balance between positive and negative.
In this situation, where one class is overrepresented in the data, the classifier tends to favor the majority class and have decreased sensitivity to the minority class.
Imbalanced Data Favors the Majority Class
When we train a classifier on an imbalanced dataset, classifiers will tend to favor the majority class.
One way to understand this is to think about accuracy.
Imagine a dataset where 95% of the examples are positive.
If the classifier were to operate in an extreme way, and simply classify every example as positive, then it would have a 95% accuracy. Great! Right?
Not so fast.
This would bring the number of True Negatives to 0.
So in the case of an imbalanced dataset, if positive is the majority class, it could damage the ability of the classifier to properly identify True Negatives.
Imbalanced Data Can Cause Decreased Sensitivity to the Minority Class
At the same time that an imbalance can favor the majority class, it can cause decreased sensitivity to the minority class.
Think of a dataset that’s highly imbalanced: 98% are positive, and only 2 percent are negative.
In such a situation, there might be too few negative examples for the model to accurately learn how to identify negative examples. There might be too little information from which to learn the distinguishing features of the negatives.
This would be particularly troublesome with an imbalanced dataset that’s also very small (e.g., a dataset with only 100 total examples, and 2% negatives).
So a strongly imbalanced dataset can reduce the model’s sensitivity to the minority class. And if the minority class is negative, the model will have more difficulty making True Negative predictions.
Overfitting to the Minority Class
If you have an imbalanced dataset and use some corrective measures to fix the imbalance, it can also cause a classifier to overfit the minority class.
For example, corrective measures may lead the model to over-represent the patterns of the minority class, making the model perform poorly on unseen data.
If the negative class were the minority class, this would change the number of True Negatives (it would increase them).
Dealing With Skewed Data
There are several ways to deal with imbalanced data, including:
- oversampling the minority class
- undersampling the majority class
- using synthetic data generation methods like SMOTE
For the sake of brevity, however, I’ll write more about those in separate blog post.
Wrapping Up
Understanding True Negatives is very important because they are foundational for many other classification topics.
At a high level True Negatives provide a measure that tells us a classifier’s ability to correctly detect negative cases.
But True Negatives must be viewed in the context of other metrics (like TP, FP, etc).
Furthermore, one must view True Negatives in the context of other details of the data, like potential data imbalance.
So as you learn to build and optimize classification systems, remember that True Negatives are important, but also part of a much larger picture of classifier performance.
Leave your other questions in the comments below
Do you have other questions about True Negatives and how they relate to machine learning classification classifier?
Is there something that I’ve missed?
If so, leave your questions in the comments section near the bottom of the page.
For more machine learning tutorials, sign up for our email list
In this tutorial, I’ve explained True Negatives and how they relate to classification systems.
But if you want to master machine learning in Python, there’s a lot more to learn.
That said, if you want to master machine learning, then sign up for our email list.
When you sign up, you’ll get free tutorials on:
- Machine learning
- Deep learning
- Scikit learn
- … as well as tutorials about Numpy, Pandas, Seaborn, and more
We publish tutorials for FREE every week, and when you sign up for our email list, they’ll be delivered directly to your inbox.