This blog post will explain classification accuracy.
It will explain what accuracy is, the pros and cons of this metric, how to improve accuracy, and more.
Table of Contents:
- A Quick Review of Classification
- Classification Accuracy Basics
- Pros and Cons of Accuracy
- How to Improve Accuracy
- Alternatives to Accuracy
If you need something specific, you can click on the appropriate link above … but you should probably read the whole post, since there’s a lot of important thing you need to know about accuracy.
That said, let’s get to it.
A Quick Review of Classification
Classification is a cornerstone concept in machine learning, and it’s crucial for understanding not only essential machine learning techniques, but also more advanced topics in artificial intelligence.
Here, I’ll briefly review what machine learning and classification are.
This will give us a foundation on which we can discuss accuracy.
Machine Learning Overview
Machine learning is a field that studies how to enable systems to learn and improve without the programming of explicit human instructions.
Rather than being explicitly programmed with human instructions about how to operate, machine learning systems improve their performance on a task as we expose them to data.
What is Classification
So machine learning enables computer systems to improve performance on a task as we expose the system to data.
But what types of tasks?
Well, there are several, but one of the most important types of tasks is classification.
Classification systems (AKA, classifiers) learn how to categorize examples. Classifiers accept some input data (called examples) and output a categorical label.
It’s important to remember that accuracy is a metric that we use to measure the efficacy of classifiers, which is why I’m discussing them here.
To further clarify what classification systems are, let’s take a look at a quick example.
A quick example of classification
My favorite example of a classification system is one that I’ve dubbed “The Cat Detector.”
Imagine a system that inputs pictures and outputs:
Positiveif the image is a cat.Negativeif the image is not a cat.
This is an example of a binary classifier. There are only two possible outputs … in this case positive or negative, but they could be 1/0, True/False, or some other binary pair of outputs.
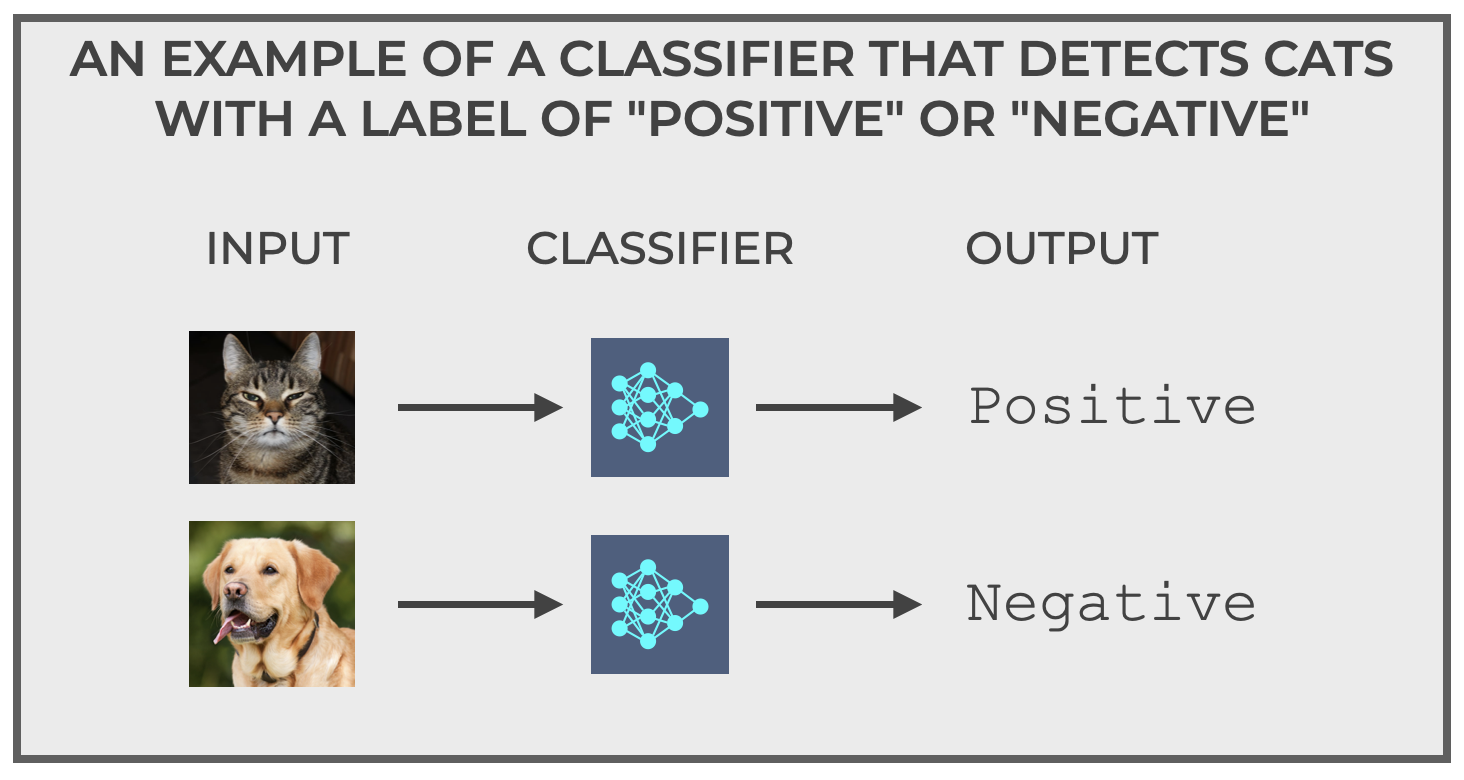
Simple enough, right?
Not so fast.
Classification systems sometimes make mistakes.
Classification Mistakes
In the image above I showed our Cat Detector correctly classifying two input images.
It correctly (ahem, accurately) classified the image of the cat by producing the output positive.
And it correctly classified the image of the dog by producing the output negative.
But sometimes, classifiers make mistakes.
So for example, it’s possible for our classifier to input the image of a cat and output negative.
Or, it’s possible for it to input the image of a dog or another thing that’s not-a-cat, and output the label positive (i.e., output that it is a cat).
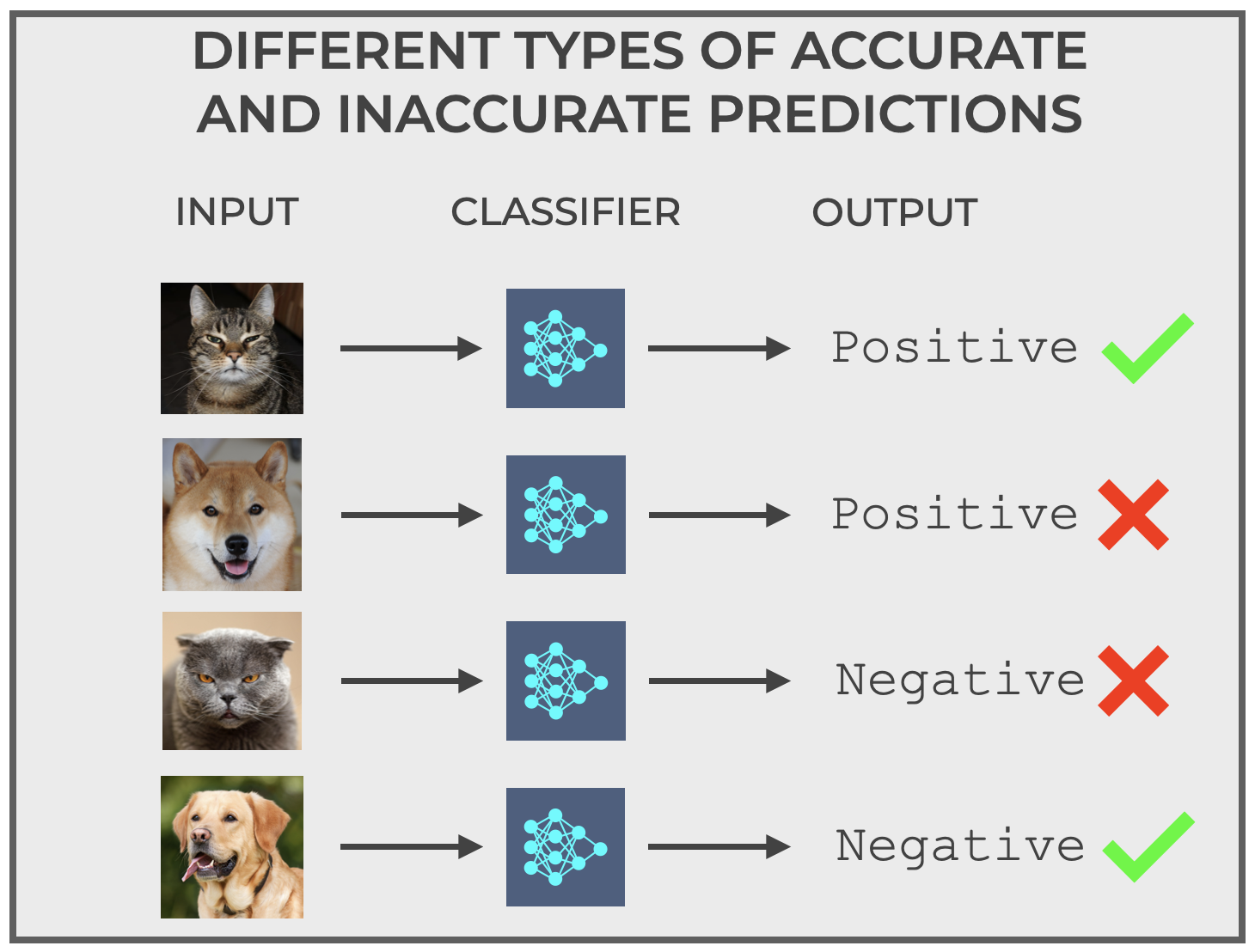
These types of correct and incorrect predictions are very important for classification generally, and the topic of classification accuracy in particular.
So before we directly talk about accuracy, let’s quickly discuss the types of correct and incorrect predictions that classifiers make.
Correct and Incorrect Prediction Types
Notice above that there are actually 4 different prediction types.
- Correctly predict that it’s a cat when it’s actually a cat
- Correctly predict that it’s not a cat when it’s actually not a cat
- Incorrectly predict that it’s a cat when it’s actually not a cat
- Incorrectly predict that it’s not a cat, when it’s actually a cat
Speaking more generally, in classification, each of these prediction types has a name:
- True Positive: Predict
positivewhen the actual value is positive - True Negative: Predict
negativewhen the actual value is negative - False Positive: Predict
positivewhen the actual value is negative - False Negative: Predict
negativewhen the actual value is positive
All of this discussion of correct and incorrect prediction types might seem boring, but it’s very important.
These classification types – True Positive, True Negative, False Positive, and False Negative – form the foundation of almost all classification metrics, including classification accuracy.
Classification Accuracy Basics
Now that we’ve discussed classification, as well as the types of correct and incorrect predictions that classifiers make, we’re ready to discuss accuracy.
We define classification accuracy as the number of correct predictions divided by the number of total predictions.
(1) 
But we can write this in terms of true positive, false positive, etc, like this:
(2) 
(Do you understand now why I needed to explain the different types of correct and incorrect predictions above?)
Put simply, classification accuracy tells us the percent of the total classification predictions that were correct.
It’s a fairly simple and straightforward way to measure the efficacy of a classification system.
An Example of Classification Accuracy
To illustrate how we use accuracy and how we calculate it, let’s use an example.
Let’s assume that we’re using our Cat Detector described above.
We feed 100 example pictures into the model as inputs – 50 cats and 50 dogs– and it outputs the following classifications (here, organized into a confusion matrix):
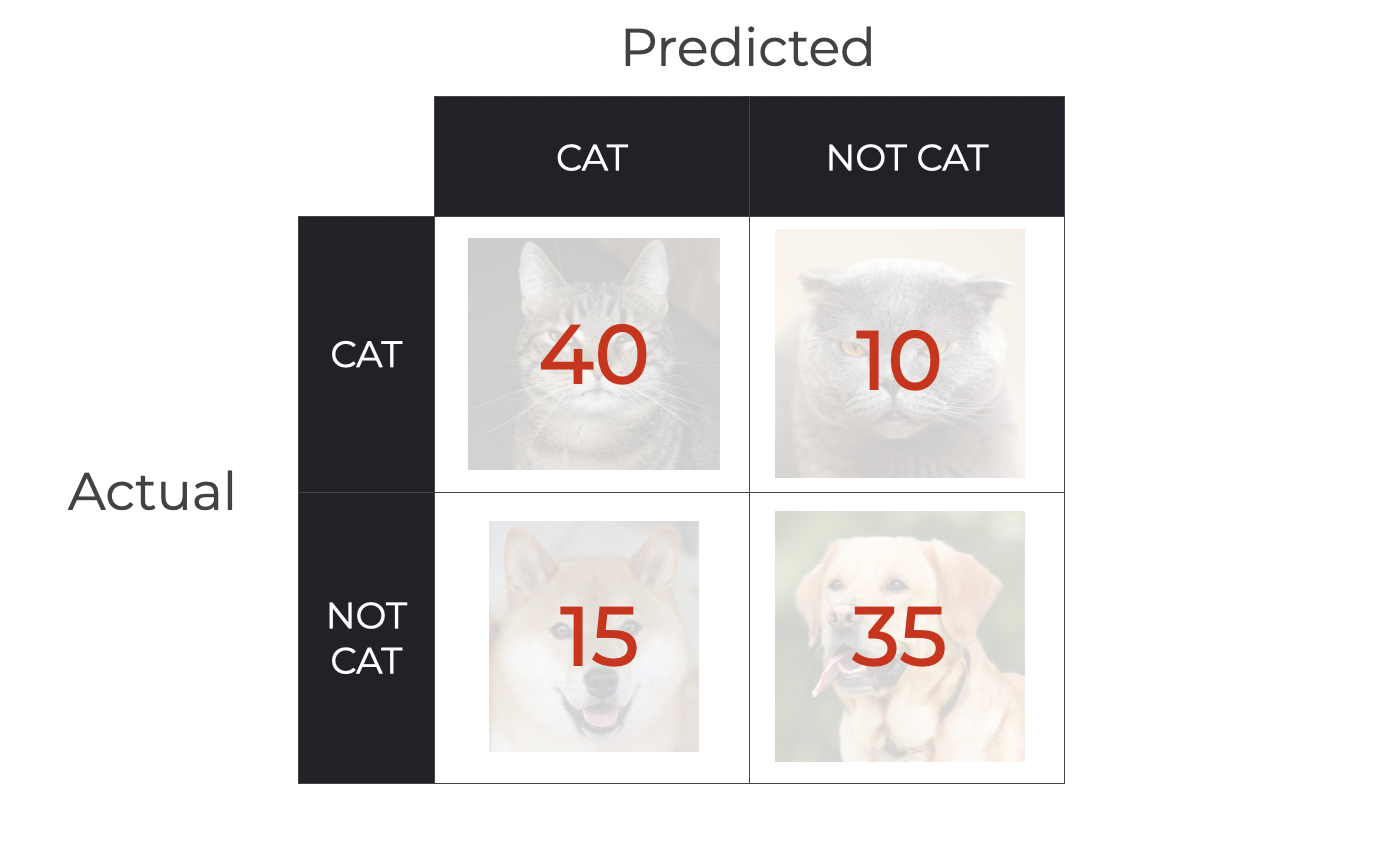
So you can see in the confusion matrix that we have …
- 40 True Positives (pictures of cats predicted as cat)
- 10 False Negatives (pictures of cats predicted as not cat)
- 15 False Positives (pictures of non-cats predicted as cats)
- 35 True Negatives (pictures of non-cats predicted as not cat)
With these numbers, we can calculate accuracy.
Calculating accuracy with TP, TN, FP, and FN
So, let’s calculate accuracy here.
Remember that accuracy is the number of True Positives + True Negatives, divided by the total number of predictions.
If we use our numbers from above, that gives us the following:
(3) 
So in this example, the accuracy of the model is .75.
The Pros and Cons of Classification Accuracy
As you’ve seen above, accuracy is fairly simple to calculate, and it’s also one of the most common metrics that we use to evaluate machine learning classification systems.
Having said that, accuracy can sometimes be an imperfect or misleading evaluation metric, so it’s important to understand it’s strengths and weaknesses.
Let’s quickly review the pros and cons of accuracy:
The Pros of Classification Accuracy
Here are the main pros of using accuracy to evaluate classifiers:
- Simplicity and Understandability
- Effectiveness on Balanced Datasets
- Good for Initial Assessment
- Holistic Overview
Let’s look at each of these.
Easy to Understand
First of all, and maybe most important, accuracy is simple and easy to understand.
As I noted above, the computation of accuracy is just the number of correct predictions divided by the total number of predictions.
Simple.
Additionally, once we compute accuracy, we can interpret the metric as a percentage. It’s essentially the percent of the total predictions that are correct.
This makes accuracy an accessible and easy-to-understand metric both for technical stakeholders, but more importantly, non-technical stakeholders.
Effectiveness on Balanced Datasets
Accuracy is also particularly effective when we use it on balanced data.
Remember: balanced data is a situation where we have roughly an equal number of classes in a classification task. So in binary classification, a “balanced” dataset is when we roughly have 50% positive and 50% negative classes.
In such a case, accuracy tends to be a much more reliably measure of model performance.
Said differently: accuracy tends to work best when the dataset is not skewed towards one target class.
Good for Initial Assessment
When we initially begin to evaluate a model, accuracy serves as a good starting point.
In spite of the weaknesses of accuracy in some circumstances (which we’ll cover below), accuracy provides a quick snapshot of model performance. This also makes it somewhat easy to compare different models on the basis of accuracy.
Holistic Overview
Finally, classification accuracy is relatively good as a holistic metric.
Instead of distinguishing between how the model performs on one class vs another (e.g., the positive class or the negative class specifically), it simply gives us a measure of how the model performs across all classes.
Now that we’ve discussed the pros, let’s move on to the cons.
The Cons of Classification Accuracy
As noted above, although accuracy is a very commonly used metric, it has some significant weaknesses as a classification evaluation metric.
At a high level, we can specify 6 major downsides of accuracy:
- Misleading on Imbalanced Datasets
- Fails to Differentiate Between Error Types
- Fails to Account for Cost of Errors
- Uninformative for Multi-Class Problems
- Lack of Insight into Confidence of Predictions
- Often Encourages Overfitting
Let’s look at each of these.
Misleading on Imbalanced Datasets
One of the biggest drawbacks of accuracy is that it is a bad metric when you have an imbalanced dataset.
As I noted above, a balanced dataset is when the dataset has a roughly equal number of the different classes.
So an imbalanced dataset is when the dataset has many more of one of the classes (or possibly several classes if we’re dealing with a multiclass classification problem). Said differently, imbalanced data is when the number of examples of the different classes are unequal in some way; when the classes are “skewed.”
When the dataset is imbalanced, accuracy tends to be deceptive.
For example: imagine a dataset with two classes, positive and negative.
And let’s imagine that the dataset is imbalanced such that 95% of the examples are positive and only 5% are negative.
If this classifier simply predicted every example as positive, it would achieve a 95% accuracy. So by not learning to distinguish between the two classes, and naively predicting everything as positive, it would still have a “great” performance based on accuracy.
Said differently, if you have an imbalanced dataset, it’s possible to achieve a good accuracy, even if the model is bad at distinguishing between the classes.
Fails to Differentiate Between Error Types
Accuracy also fails to distinguish between different types of errors.
In the section about different types of predictions that classifiers make, I mentioned two different types of incorrect predictions: false positives and false negatives.
These are different types of errors, and these errors often have different costs, depending on the exact task.
For example, in a medical diagnosis task for a fatal disease, a false positive (incorrectly diagnosing a person with a disease who does not have it) is different than a false negative (missing a diagnosis in a person who actually does have the disease).
Accuracy fails to distinguish between these different types of errors.
Fails to Account for Cost of Errors
Not only does accuracy fail to account for different types of errors, it also fails to account for the different costs of those errors.
Let’s go back to the medical diagnosis task for a fatal disease, which I just mentioned in the previous section.
In such a situation, false positives and false negatives both have costs.
For example, a false positive, incorrectly diagnosing a person with a disease who does not have it, might cause medical providers to initiate treatment, which will have costs for the patient, insurance provider, etc.
But a false negative – missing a diagnosis in a person who actually does have the disease – would likely be even more costly. Such a mistake might cost the patient his or her life.
Accuracy fails to account for these costs in any way.
In many classification problems, you often have different (and asymmetric) costs, and in these cases, you will likely need a metric besides accuracy.
Uninformative for Multi-Class Problems
Many of the examples that I’ve referenced in this post have been binary classification problems. In binary classification, there are 2 classes, like positive/negative, true/false, etc.
But in a multiclass classification problem, there are three or more classes.
In these multiclass classification problems, accuracy fails to provide information about which classes it performs well on and which it performs poorly on.
For example, if there are three classes, and your model systematically fails to perform on one of those classes, accuracy will provide no insight into this issue.
In this sense, a model with good accuracy could still mask poor performance on a particular class. This is especially true if the class is a minority class with fewer examples.
Lack of Insight into Confidence of Predictions
Accuracy also fails to provide insight into the confidence that the model has about its predictions.
Two models could have the same accuracy, but potentially have different levels of certainty regarding their predictions.
Often Encourages Overfitting
Finally, focusing exclusively on maximization of accuracy can lead to overfitting, where the model performs well on the training dataset, but performs more poorly on previously unseen data.
Overall, accuracy is easy to use and easy to understand when we evaluate classifiers.
But, accuracy has many limitations.
It works best on balanced datasets, and it’s best to use accuracy in the context of a broader set of evaluation metrics.
In order to get a comprehensive assessment of a model’s performance, you typically need to consider other metrics like precision, recall, and F1 score.
These other metrics can provide a more nuanced view of a model’s behavior.
How to Improve Classification Accuracy
Now that we’ve discussed what accuracy is and the pros and cons of accuracy, let’s quickly discuss how to improve the accuracy of a classification system.
There are a variety of strategies for increasing accuracy, but we can bundle those strategies into a few categories:
- Data Preprocessing
- Feature Selection and Engineering
- Choosing a Good ML Algorithm
- Hyperparameter Tuning & Cross Validation
Let’s quickly discuss each of these.
Data Preprocessing
Good data preprocessing can improve accuracy.
This includes:
- Data Cleaning: Data cleaning involves removing duplicate records, handling missing values, and correcting errors in the data that could cause inaccuracy in the model.
- Normalization and Standardization: Normalization and standardization rescales numeric values to prevent dominance of certain features over others, due to scale differences. Normalization adjusts features to a range of [0, 1], while standardization scales data to a mean of 0 and a standard deviation of 1.
- Encoding Categorical Variables: Variable encoding converts categorical variables into numeric format, using methods like one-hot encoding.
- Handling Imbalanced Data: We can deal with imbalanced data (which I described earlier) with techniques like oversampling the minority class or undersampling the majority class. This can help balance out the dataset, which promotes better model performance.
Feature Selection and Engineering
Selecting and engineering good features can also improve model accuracy. This includes:
- Feature Selection: In feature selection, we identify the most important features. This reduces redundancy and also decreases overfitting.
- Feature Engineering: In feature engineering, we create or transform features in order to capture essential patterns in the data.
Choosing a Good ML Algorithm
The accuracy of a classifier will be influenced (often strongly influenced) by the choice of classification algorithm.
All algorithms – such as logistic regression, decision trees, support vector machines, neural networks, etc – have strengths and weaknesses.
Some algorithms will achieve better accuracy in certain circumstances.
You need to understand the strengths and weaknesses of different algorithms to ensure that you select the most appropriate algorithm for your task.
Hyperparameter Tuning
You can “tune” the hyperparameters of a model in order to improve accuracy.
In hyperparameter tuning, you optimize the model’s performance by adjusting algorithm settings (the hyperparameters) by using methods like grid search or random search.
Cross Validation
Finally, you can use cross validation to improve accuracy.
In cross validation, you repeatedly divide your dataset into different parts for training and validation, and then train the model. This process of dataset division and training is performed multiple times to better show how a model will perform on previously unseen data.
All in all though, improving classification accuracy often requires multiple tools and strategies, from data preparation, to parameter tuning, to cross validation. You often need to use many of these tools an techniques to optimize your model
Alternatives to Accuracy
As mentioned above, accuracy is often a poor metric for evaluating classification problems, particularly in situations like imbalanced data.
That being the case, there are other classification evaluation tools and metrics like precision and recall, F1 Score, and confusion matrices, that we frequently use instead of or in addition to accuracy.
I’m going to write about all of those other metrics in separate blog posts.
Wrapping Up …
Accuracy is an important evaluation metric for machine learning classification systems, and it’s one of the first metrics that you will need to understand.
That said, accuracy has many weaknesses, so you’ll need to learn it’s limitations, how to improve it as best as possible, and other possible classification metrics to use instead of accuracy.
Hopefully, this article gave you a solid overview of accuracy and will serve as a good foundation for your continued learning about machine learning evaluation.
Leave Your Questions and Comments Below
Do you have other questions about the classification accuracy?
Are you still confused about something, or want to learn something else about accuracy that I didn’t cover?
I want to hear from you.
Leave your questions and comments in the comments section at the bottom of the page.
Sign up for our email list
If you want to learn more about machine learning, then sign up for our email list.
Several times per month, we publish free long-form tutorials about a variety of data science topics, including:
- Scikit Learn
- Pandas
- Numpy
- Machine Learning
- Deep Learning
- … and more
If you sign up for our email list, then we’ll deliver those free tutorials to you, direct to your inbox.