Have you ever had someone talk about a classification system or medical diagnostics and mention a “False Positive?”
It’s ok …
False positives can be confusing if you haven’t worked with classifiers and detection systems before.
But they’re important …
Which is why, in this blog post, I’m going to explain almost everything you need to know about False Positives.
I’ll explain what False Positives are in clear, simple terms.
I’ll explain how they relate to machine learning classification systems.
And explain some of the pitfalls and challenges associated with reducing False Positives.
If you need something specific, just click on one of the following links. Each link will take you to the appropriate section of the tutorial.
Table of Contents:
- What are False Positives
- Why are False Positives Important in Classification Systems
- How to Fix False Positives
- Frequently Asked Questions
Still, everything will make more sense if you read the article from the beginning, because you need to understand some related material before we really discuss FPs.
That being said, let’s jump in.
What is a False Positive?
In simple terms, a False Positive (FP for short) is when an underlying example is actually negative, but a classification system or detection system incorrectly predicts that it’s positive.
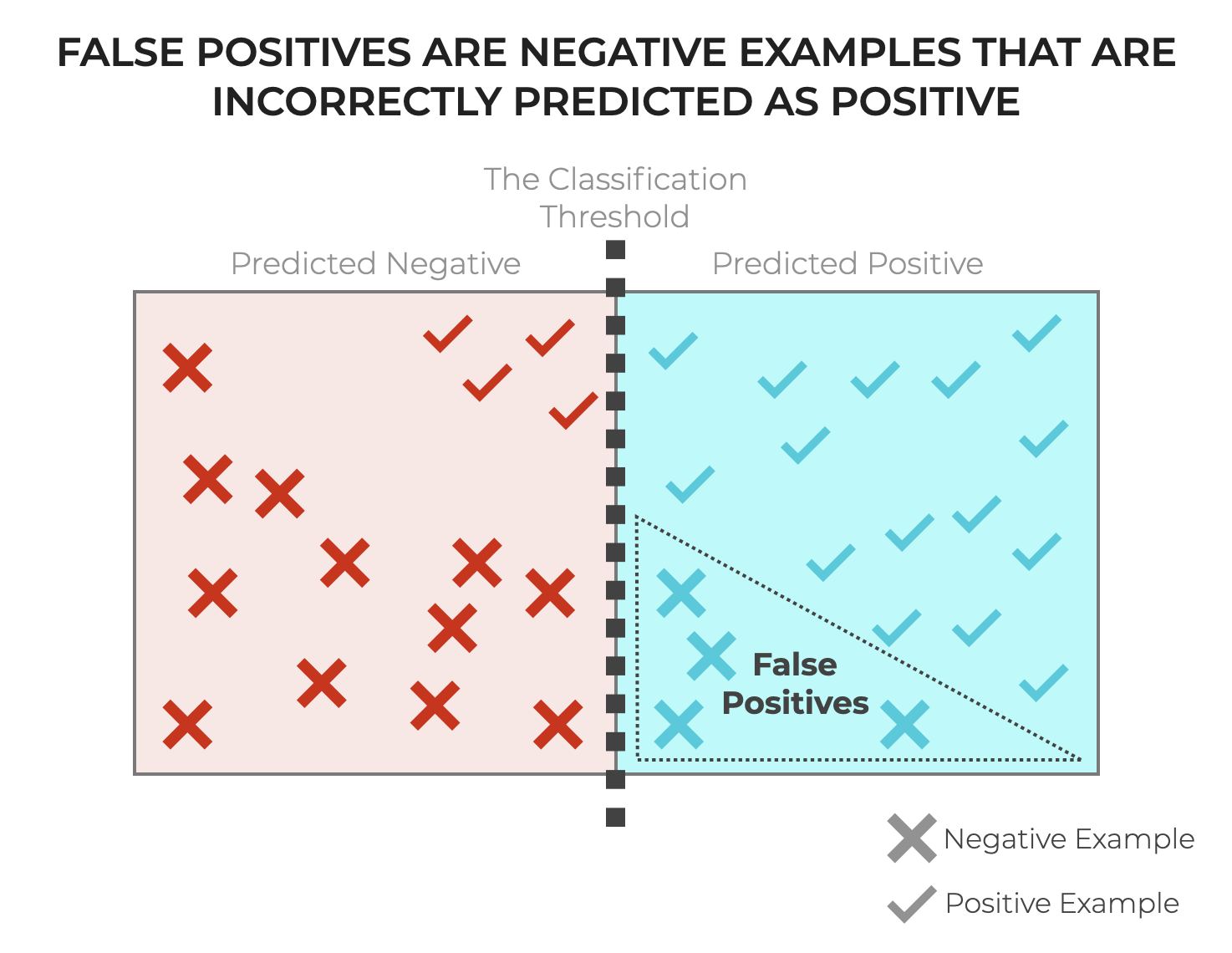
An FP is one type of classification mistake (the other being a False Negative).
To really understand the nature of False Positives, however, and why they happen, we need to discuss classification systems and how they work. Exploring how classification systems work will lay the foundation for understanding the nuances of False Positives.
Classification Review: Classification Systems Predict Categories
Here, I’m going to very quickly review how classification and detection systems work, just so we can lay the foundation for discussing how False Positives occur.
Classifiers (i.e., classification systems) predict categorical labels.
This is in contrast to regression systems that predict numbers.
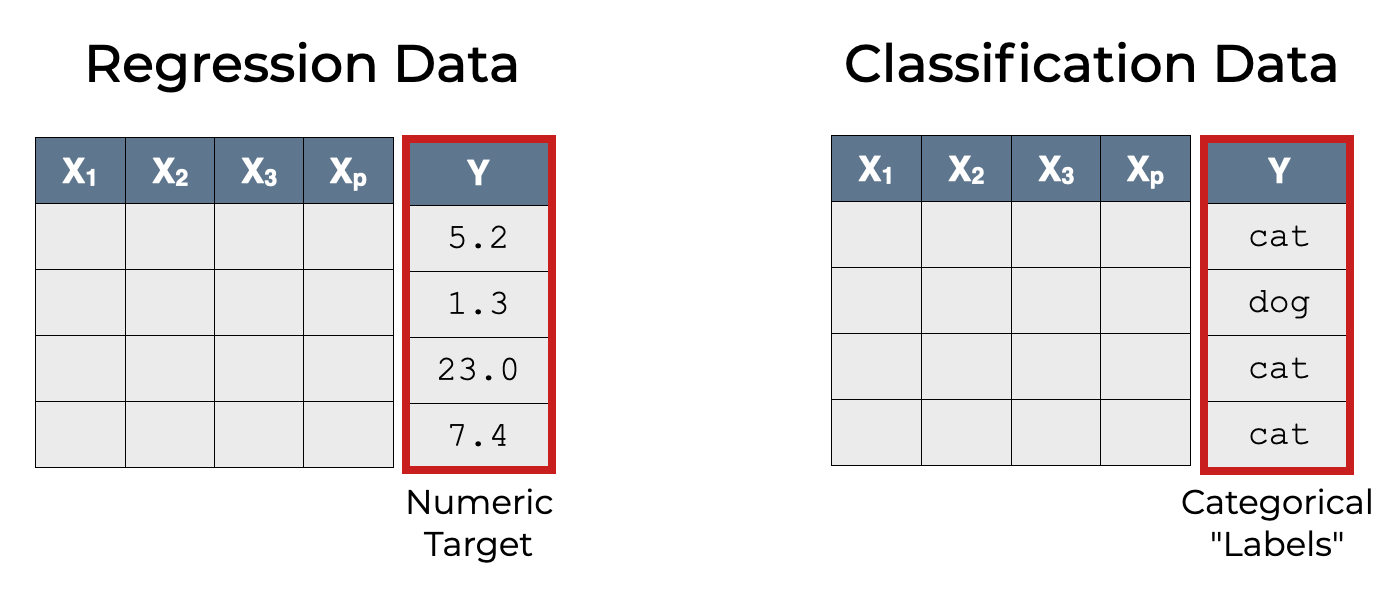
Binary classification systems are a special case (but also the most common case) where there are only two possible categorical labels.
There are different exact encodings for binary data, like:
True/FalseYes/No1/0
As it turns out though, we can simplify all of these encodings down into something more general that covers them all.
Positive and Negative as a General Binary Encoding
All of the binary encodings discussed above generalize to the following: positive/negative.
To illustrate, let’s look at a quick example.
Example: Spam Classification
Spam classification is a classic binary classification example.
Almost all modern email systems use a form of classification to identify spam so it can be filtered out.
Obviously, the purpose of these spam detection systems is to identify junk mail, which we commonly call “spam.”
In these spam detection systems, we can classify every incoming email as follows:
Positiveif the system predicts that the email is “spam”.Negativeif the system predicts that the email is “not spam”.
It’s a simple, common classification system, and it’s a simple illustration of the positive/negative encoding system that we can use generally in binary classification.
Also, remember that positive/negative doesn’t mean good/bad. positive and negative are just labels that encode binary outputs, similar to on/off or True/False.
Classifiers Make Different Type of Correct and Incorrect Predictions
Now that I’ve explained this encoding scheme for binary classification, we can start talking about the types of correct and incorrect classifications that a classification system can make.
This is important, because it’s where we finally encounter False Positives.
Example: the Cat Detector
Let’s imagine that we have a classification system: The Cat Detector.
The purpose of the system is to detect cats.
We feed this classifiers images as the inputs, and the output is a prediction: positive or negative.
The Cat Detector:
- Predicts
positiveif it thinks that the image is a cat. - Predicts
negativeif it thinks that the image is not a cat.
It sounds straightforward.
But you have to remember, that essentially all classification systems make mistakes.
For example, imagine the case where we input a picture of a dog (which should get the label negative), but the classifier makes a mistake and outputs positive.
A classification mistake, and a specific type of mistake that we’ll get to in a moment.
In fact, if we consider the 2 types of input images (cat and not cat) as well as the 2 types of predicted labels (cat and not cat), then there are 4 combinations of predicted class and actual class.
… 4 different types of correct and incorrect predictions.
And we can refer to them with names, as follows:
- True Positive: Predict
positivewhen the actual value is positive (an image of a cat) - True Negative: Predict
negativewhen the actual value is negative (not an image of a cat) - False Positive: Predict
positivewhen the actual value is negative (not an image of a cat) - False Negative: Predict
negativewhen the actual value is positive (an image of a cat)
So a False Positive is one of the incorrect predictions, where the actual class is negative, but the classifier incorrectly predicts positive.
Why are False Positives Important?
Now that we know what False Positives are, let’ talk about why they’re important to understand, and why they are a problem in classification tasks.
Although False Positives may seem like a minor error, they can cause significant costs and consequences.
At a high level, here are a few of the issues that may arise due to FPs:
- Wasted Resources
- Bad Decisions and Decision Fatigue
- Loss of Trust
- Psychological Effects
- Societal Impact
- Ethical and Legal Implications
- Skewed Performance Metrics
Let’s discuss each of these separately.
Wasted Resources
One of the primary issues with False Positives is wasted resources. Consider a security system that is supposed to identify the presence of threats. A false alarm (i.e., a False Positive) will likely require a response from a security team, and this will require the expenditure of both time and financial resources.
Another example is a medical system that detects a disease. A False Positive (e.g., saying that a person has cancer, when in fact, they are healthy), would likely cause a medical provider to order expensive medical procedures to “treat” the disease, even though the disease is absent.
Bad Decisions and Decision Fatigue
Second, repeated False Positives can lead to a sort of decision fatigue.
Continually responding to non-existent threats can make it harder to identify and react to genuine threats.
A decision maker might become inured to threats, and become resistant to responding to detected threats over time.
Psychological Effects
False Positives can have profound negative psychological effects on the individual level.
Imaging a medical test that incorrectly diagnoses a healthy person with a serious medical disease, like cancer. Setting aside the potential costs of treatment (which I discussed above), the psychological effect of a cancer diagnosis could be terrible. Stress, fear, sadness … these would all be greatly increased by a False Positive diagnosis.
Societal Effects
Moving to the level of a society, False Positives could damage public trust in institutions if there are a high number of FPs.
Again, taking the case of medical diagnostics, if a medical test used to detect a disease produced large numbers of False Positives, people might begin to not only mistrust the test, but the medical institutions that apply that diagnostic test.
Or take another example of a public emergency warning system. If there were a large number of False Positives, people might begin to lose confidence in that system, and the governing institutions that managed it.
So at the societal level, if large scale detection systems produce too many False Positives, it may damage a society’s trust in the institutions related to those systems.
Ethical and Legal Implications
In some areas, like financial fraud detection or criminal justice, False Positives could have dire legal and ethical consequences.
For example, incorrectly flagging a person as a potential criminal or as someone who has committed fraud could trigger criminal investigation or legal action against an innocent person.
One could also imagine a medical scenario where a False Positive caused a person to undergo an extreme medical procedure that might cause an irreversible change, like a surgery to remove an organ or part of the body. If it were shown that the original diagnosis was a False Positive, that might put the medical practitioner under risk of a malpractice suit.
Skewed Performance Metrics
Perhaps the most general problem with False Positives, and the most common for a machine learning practitioner, is the problem of distorted performance metrics.
False Positives underpin a variety of machine learning evaluation tools and performance metrics, such as:
An increase in False Positives will cause a decrease in these metrics.
And ultimately, a decrease in the above metrics means reduced model performance.
To be clear though, the relative impact of a reduction in accuracy, precision, F1 score, or other metric depends on the task and the context. For some tasks we optimize for Precision (where False Positives will matter more). In other tasks, we may prefer to optimize for recall (where False Positives will matter less). Yet in other tasks, we may optimize for F1 score.
In each of these scenarios, an increase in False Positives will have a different effect, so you need to judge the model performance based on the exact metrics you’re optimizing for, and the metrics you choose will depend on the goals of your system.
Because the choice of metrics and how we optimize for them is a very big topic, I’ll write more about it in the future.
How to Fix False Positives
As we’ve seen in prior sections of this article, False Positives are bad in classification systems, since they can damage not only the performance of a classifier, but damage trust in the classifier.
Whether you’re building a spam filter, a medical diagnostic tool, or a security alert system, limiting the number of FPs is essential.
I’m going to review several ways to mitigate or fix False Positives. The major tactics you need to know about are:
- Reassess Feature Selection and Engineering
- Adjust Classification Thresholds
- Resampling and Data Augmentation
- Algorithm Selection
- Ensemble Methods
- Post-processing and Expert Review
Let’s discuss each of these individually.
Reassess Feature Selection and Engineering
First, let’s talk about re-evaluating our selected features.
Feature Selection
The features that you use in a model play a significant role in the quality of the model and quality of the output.
It’s important to remember that features typically play an unequal role in a model’s performance. Some features are more important than others.
Additionally, using unimportant features (AKA, irrelevant, uninformative, or redundant features) can decrease the performance of a model generally, but also increase False Positives specifically. That being the case, if your model has a relatively large number of FPs, you may need to review the features that are being used, and possibly remove some of them.
Feature Engineering
Sometimes, the original features in the dataset are insufficient for learning how to distinguish between the target classes.
In such a situation, it may be possible to use feature engineering to either create new features from the original ones or to transform the original features in such a way that the new engineered features provide more information. Remember: feature engineering is the process of creating new features or transforming existing ones to improve model performance.
Creating new features or transforming the original ones can increase the classifiers’s ability to correctly make True Positive and True Negative predictions, while also decreasing False Positives and False Negatives.
Feature engineering is a very broad and complex topic, so I’ll refrain from providing a full treatment on the subject here. However, the most common techniques that you should know are dimension reduction techniques like Principal Component Analysis, polynomial features, and normalization techniques.
Again, feature engineering is a complex subject, so I’ll write more about these techniques in separate blog posts.
Adjust Classification Thresholds
As I’ve written about elsewhere, the number of True Positives and False Positives frequently depends on the classification threshold of a classifier.
Just to review: many classifiers use a classification threshold as a cutoff point to decide whether an example should get a positive or a negative label. Not all classification algorithms work this way, but many do, including common model types like Logistic Regression.
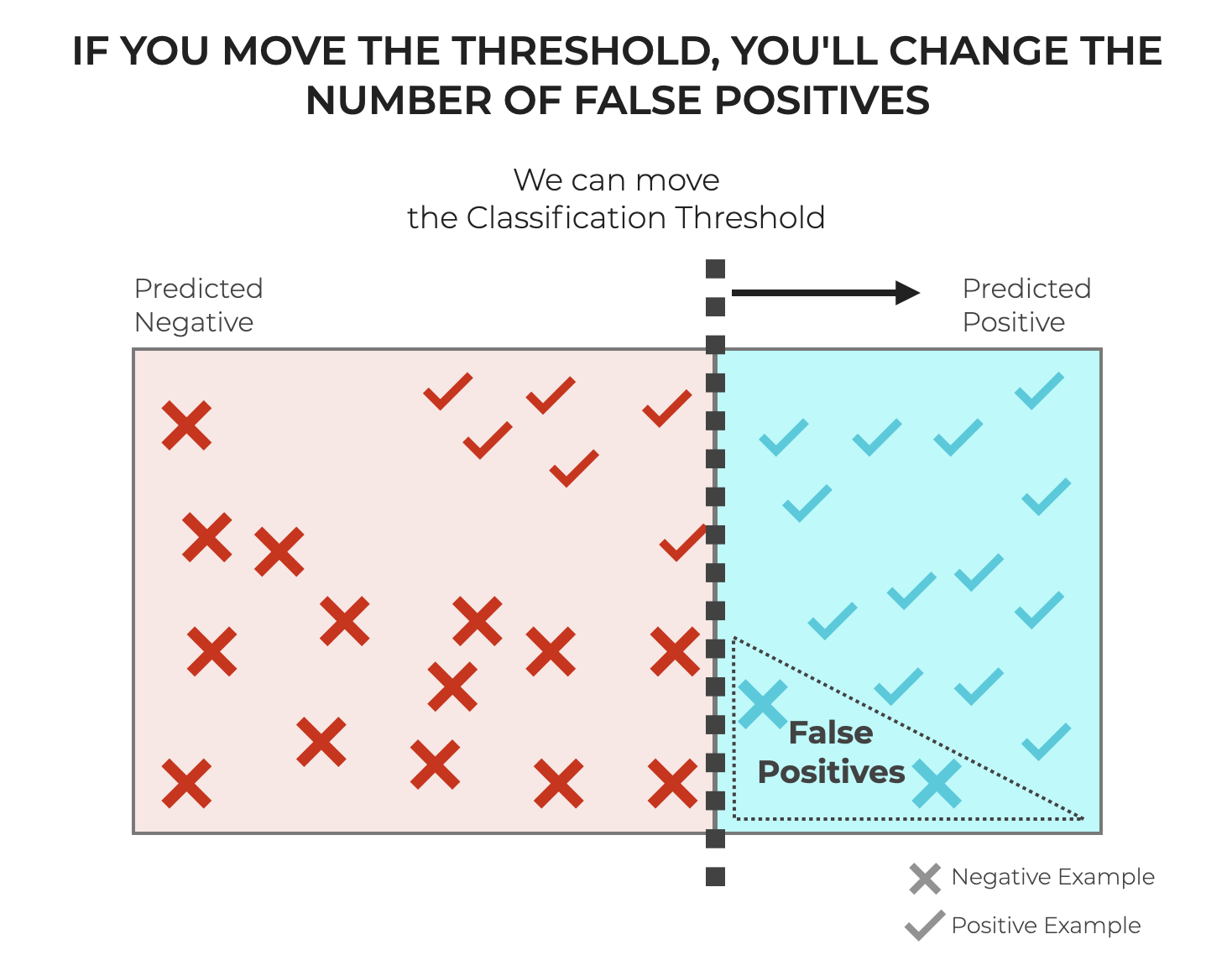
With regard to classification threshold, there are a few important points to consider:
First, the threshold can be moved. As a machine learning engineer, we can choose the threshold. But, this has consequences. If we increase the classification threshold we’ll decrease the number of False Positives, but also increase the number of False Negatives. Conversely, if we decrease the threshold, we’ll increase False Positives, but decrease False Negatives. There’s a tradeoff between FPs and FNs, and we can control the tradeoff by changing the classification threshold.
Second, we can use an ROC curve to visualize that tradeoff and identify the best threshold for the specific needs of our classification system.
Essentially, you can manipulate the number of FPs by changing the classification threshold, in models that have one.
Resampling and Data Augmentation
An imbalanced dataset could cause an increase in False Positives. In particular, if positive examples are over represented (i.e., there are many more positive examples than negative examples), then this could lead to more FPs.
One way of handling this is to oversample negative examples or undersample the positive ones.
It’s also possible to use synthetic data generation to help balance the dataset. Techniques like Synthetic Minority Over-sampling Technique SMOTE can generate new, synthetic examples inside the existing feature space. If your data has too many FPs due to too many positive examples, you could generate negative examples to balance your data.
However, keep in mind that synthetic data has risks. Synthetic data, if not generated improperly, can lead to other issues in model performance.
Algorithm Selection
Different machine learning algorithms have different susceptibility to False Positives.
If you build one model and find that it has too many FPs, you may want to experiment with other model types (i.e., logistic regression, decision trees, random forests, neural networks, etc) and see if a different a different model type improves performance with respect to the False Positives and other metrics of interest.
Ensemble Methods
Instead of using a single model, you can use a “ensemble” technique, where we build multiple models and combine their results. Ensemble methods can lead to more robust results that are more resistant to False Positives, since the probability that all of the models in the ensemble produce an FP for a particular example is lower than the probability of an individual model.
In a related vein, random forests and bagged trees generate multiple decision trees and aggregate the results of these multiple individual tree models. Random forests and bagged trees can have better predictive performance, partially by being more robust against producing FPs. So if, for example, you build a single decision tree and you find that it produces too many FPs, you may want to build a random forest or bagged tree.
Post-processing and Expert Review
In critical applications, you might consider introducing a step where high-impact predictions (i.e., like a cancer diagnosis system) include an expert review. This additional step can sometimes catch FPs before they cause negative financial, social, or psychological consequences.
You can also introduce feedback mechanisms that allow users to report back and indicate whether a prediction was accurate. This feedback data can be used to improve and fine-tune the model’s performance. Ideally, this feedback data will help reduce False Positives over time.
Final Thoughts on Dealing with False Positives
False Positives are potentially a big problem with classification systems. As noted above, there are many ways to reduce FPs or mitigate their negative impact.
Having said that, all of the techniques mentioned above can be complex and nuanced. They all deserve greater explanation, and I will try to write about them more in other articles.
Additional Reading
As I’ve mentioned several times in this article, False Positives can have a big impact on the performance of a classifier.
But it can also be complicated to diagnose the causes of False Positives, and the methods for fixing them often have tradeoffs.
That said, to deal with FPs properly, you should also have a good understanding of several related concepts, including:
Do you have other questions?
Is there something that I’ve missed?
Do you still have questions about False Positives?
I want to hear from you.
Leave your questions in the comments section at the bottom of the page.
For more machine learning tutorials, sign up for our email list
In this tutorial, I’ve explained False Positives and how they relate to classification systems.
But if you want to master machine learning in Python, there’s a lot more to learn.
That said, if you want to master machine learning, then sign up for our email list.
When you sign up, you’ll get free tutorials on:
- Machine learning
- Deep learning
- Scikit learn
- … as well as tutorials about Numpy, Pandas, Seaborn, and more
We publish tutorials for FREE every week, and when you sign up for our email list, they’ll be delivered directly to your inbox.